
요즘 Diffusion 필드에서 슈뢰딩거 다리 (SCHRÖDINGER BRIDGE)가 새로운 트렌드로 떠오르는 것 같다. 관련 논문이 많이 나오길래, 따라잡아보았다.
최근 연구 동향
•
Developed a two-stage unsupervised procedure for estimating the SB between a Dirac delta and data.
21NeurIPS DSB: Diffusion Schrödinger Bridge with Applications to Score-Based Generative Modeling. [code]
•
Extends the Iterative Proportional Fitting (IPF) procedure to the continuous setting.
22arXiv RSB: Applying Regularized Schrödinger-Bridge-Based Stochastic Process in Generative Modeling. [code]
22ICLR SB-FBSDE: Likelihood Training of Schrödinger Bridge using Forward-Backward SDEs Theory.
•
•
Solves the SB problem with a conditional variant of flow matching.
23ICMLw OT-CFM: Improving and generalizing flow-based generative models with minibatch optimal transport [code]
Applications
23arXiv InDI: Inversion by direct iteration: An alternative to denoising diffusion for image restoration.
•
Uses paired data to learn SBs between Dirac delta and data
•
Discovered DDIMs as SBs between data and Gaussian distributions.
1. Prelinamary: SGMs (score-based generative modeling)
•
생성 모델링 (Generative Modeling)에서는 주어진 분포 를 주어진 데이터 분포 로 변환 (Transform)하는 알고리즘을 설계하는데 관심이 있습니다. 데이터 분포 는 샘플을 통해서만 접근할 수 있습니다.
•
Energy-based Models, GANs, Normalizing Flow, VAE 또는 Diffusion Score-matching 과 같은 다양한 프레임워크가 연구되어왔습니다.
•
Diffusion Model은 시각적 품질 측면에서 GAN을 능가하는 데 큰 가능성을 보여주었으며, 확산 과정의 이산화(discretization)로 재구성 될 수 있으므로 수학적 관점에서도 매력적입니다.
•

SGMs
1차원 Standard Wiener Process
•
•
Forward Process (데이터분포→ 사전분포)
•
(벡터 함수): 드리프트 계수
(스칼라 함수): 는 확산 계수
: Standard Wiener Process (Standard Brownian Motion)
→ 평균이 0인 분산의 정규 분포 t를 따르는 연속 확률 변수.
•
Reverse Process (사전분포 → 데이터분포)
•
드리프트 계수에 Score Function 항이 추가되었습니다.
•
함수 는 확률 밀도 뒤에 순방향 과정에서 가 됩니다. ().
◦
이때,
•
Forward Process에서 확률분포 다음 가 오는 것은 Fokker-Plank (FP) 방정식으로 주어집니다.
◦
Kolmogorov's equation of advance 라고도 함.
◦
Forward Process (1) 에 대응하는 FP는 다음과 같이 주어짐.
◦
는 명시적이지 않으므로 솔루션이 존재하지 않음.
•
Objective Parameter화 된 모델 에 대해 를 학습합니다.
◦
생성( 회귀프로세스) 중에는 밀도함수 를 알 필요가 없음.
◦
조건부 확률 의 score에 대한 L2 Loss 최소화
•
Score-Matching 위 손실함수는 다음 최적화문제와 동일합니다.
•
학습된 score 추정모델 를 사용해 회귀프로세스의 해 를 구합니다.
•
정확도 및 계산복잡성을 고려하여 다양한 알고리즘을 사용합니다.
•
가장 간단한 솔루션은 Euler-maruyama method입니다.
◦
상미분방정식 (ODE)에 대한 수치 솔루션인 오일러 방법의 SDE 버전.
•
이는 오일러 방법에 노이즈항이 추가된 형태입니다. (DDPM과 동일)
ODE (Probability Flow ODE)
•
실제로 확산 모델의 많은 응용 분야에서는 생성에 SDE 대신 ODE를 사용합니다.
•
확산 모델의 SDE는 Probability Flow ODE → 공통 밀도 함수를 가진 ODE를 동반합니다.
•
장점:
1.
재학습 없이 기존 학습된 모델에 적용 가능
2.
결정론적 생성 과정이기 때문에 고정된 초기값에 대해 항상 동일한 결과를 보장됨.
3.
오랫동안 연구된 ODE Solver를 사용할 수 있음. (예: Runge-Kutta 방법)
•
SDE → Probability Flow ODE 유도
1.
를 FP방정식에 적용 (로그 미분 공식)
2.
변수변환 은 확산항이 없는 FP방정식이고 해는 Forward Porcess와 일치.
3.
변환된 FP방정식에 해당하는 (확률) 미분방정식 중 하나는 Probability Flow ODE.
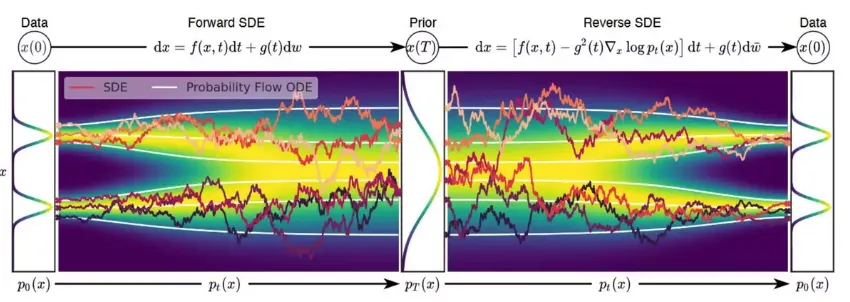
FP SDE와 Probability Flow ODE

점수 기반 생성 모델링의 주요 한계 중 하나는 초기 forward process가 에 근접하도록 많은 양의 step를 요구하고 신경망 근사가 유지되도록 충분히 작은 크기의 stepsize를 요구한다는 것입니다.
이를 해결하기 위해 Diffusion Schrödinger Bridge가 제안되었습니다.
•
기존 Score-based Modeling의 일반화 버전.
•
Score-based 방법에 비해 필요한 stepsize의 수를 크게 줄일 수 있음.
•
가 Gaussian이어야 한다는 제한을 제거함
•
따라서 고차원 최적 운송 (Optimal Transport) 에 대한 가능성을 열음.
Schrodinger Bridge - “진정한” Image-to-image를 향하여
•
Diffusion Models의 체계를 Image-to-image로 확장하려고 합니다.
•
하지만 입력 이미지는 guide가 아닌 다른 방법으로 간주합니다.
•
사전확률분포를 임의의 분포로 대체하지 않는 이유? → Forward Process의 설계 방법이 문제가 됩니다.
◦
확률 밀도에 대한 를 만족하기 위해 하이퍼파라메터 를 설계해야 함
(FP방정식에서 는 에 의해 자동으로 결정됨)
◦
하지만 일반적으로 는 암시적이므로 학습전에 설계된 를 사용하기 어려움.
•
확산 모델에 대한 FP 방정식은 다음과 같습니다.
•
확산 모델 대신 조금 더 추상화된 생성모델에 대한 문제 설정을 고려하겠습니다.
1.
데이터분포 와 사전분포 가 주어지면,
2.
각 분포는 SDE를 통해 연결됩니다.
3.
SDE에 따라 확률밀도 를 모델링합니다. (경계조건:
•
Schrodinger Bridge
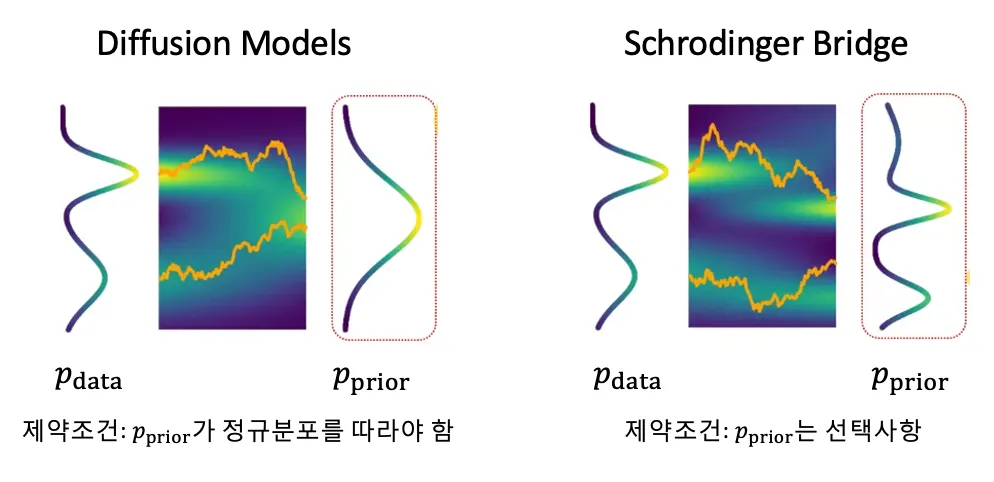
•
분포는 브라운 운동 사이의 “다리”가 됩니다.
•
양자역학의 슈뢰딩거 방정식과는 다릅니다. (관련은 있습니다.)
•
C. Léonard (2013), Y. Chen et al. (2020)
Dynamic Schrodinger Bridge (Static SB)
•
SB는 확률 과정의 경로 측도 제약이있는 KL 다이버전스 최소화 문제로 공식화
•
경로 측도는 경로 전체를 하나의 단일표본으로 보았을 때의 확률분포에 해당합니다.
•
여기서, 경로 측도 ℙ, ℚ는 각각 근사 분포와 참 분포에 대응하며, 특히 ℚ를 참조측도라 부릅니다.
•
후술하는 static SB와 대비하여, 이는 dynamic SB라고도 불립니다.
Static Schrodinger Bridge (Static SB)
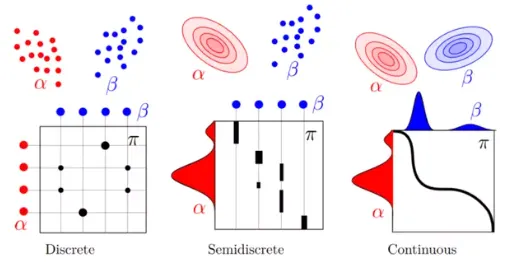
π.α.β는 각각 ℙ0,𝑇, 𝜇0, 𝜇𝑇에 대응
•
Dynamic SB의 최적해는 관련된 Static SB의 해로 구성할 수 있습니다.
◦
완만한 가정 하에서 양자의 최적해는 일대일로 대응합니다. (후술)
•
Static SB: 처음 및 마지막 시간에 대한 결합분포에 대한 KL Divergence 최소화 문제.
◦
도중의 경로를 주변화 (Marginalize)해 시점과 종점의 조합만을 고려하는 설정
Dynamic SB와 Static SB의 관계
•
Dynamic SB의 해를 , static SB의 해를 로 나타냅니다.
•
◦
양단의 값 이 고정된 확산과정을 (Diffusion) Bridge라고 부릅니다.
◦
와 같이 bridge의 주변화로 구성된 경로 측도를 Mixture of bridges라고 부릅니다.
◦
또한 반대로 를 에서 고유하게 구성할 수 있습니다.
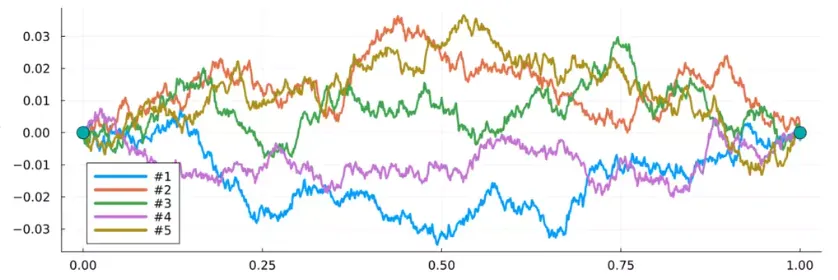
1차원Diffusion Bridge 의 표본 경로
최적 수송 (Optimal Transport; OT)
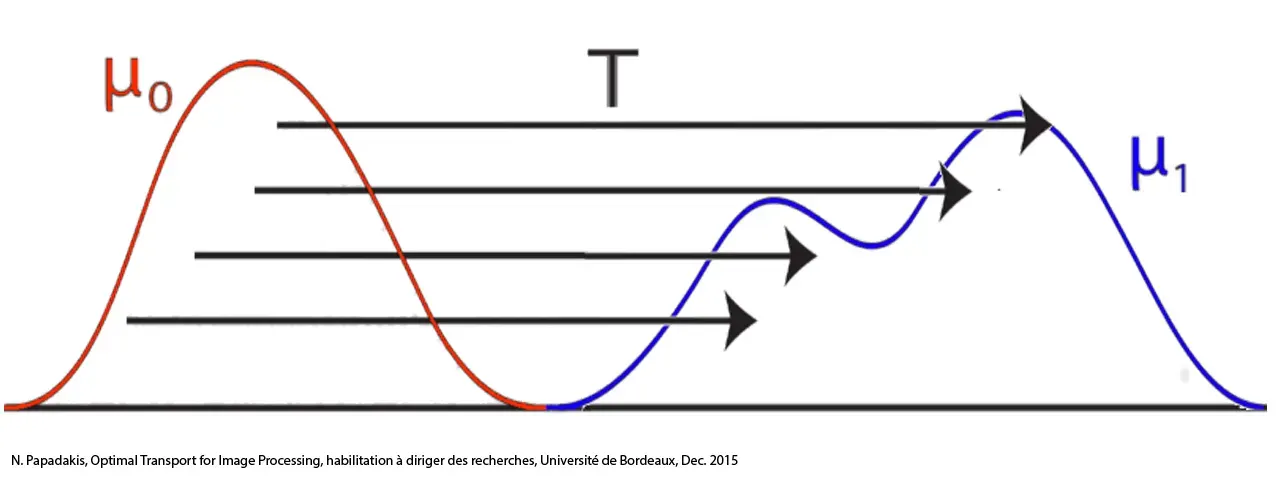
•
Optimal Transport: 확률분포를 이동 시킬 때 비용을 최소화 하는 운반방법을 찾는 문제
•
•
밀도 함수를 모래 산으로 보고, 한 모래산을 운반하여 다른 형태의 모래산을 구축할 때 걸리는 운반비용 (거리와 운반량에 상관)이 최소가 되는 조합을 찾는 문제
Kantorovich Optimal Transport
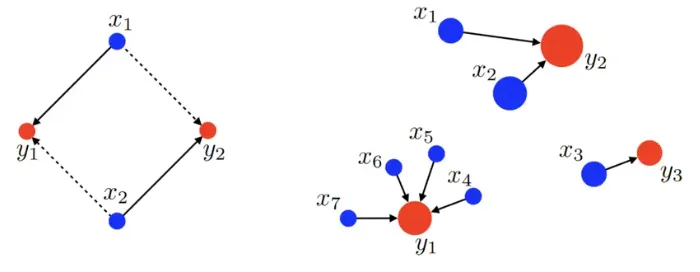
•
현대적인 최적수송의 공식화는 Kantorovich의 방법을 사용합니다.
•
총 이동 비용을 최소화하는 커플링 측도 𝜋 를 찾는 문제로 볼 수 있습니다.
◦
한 점에서 다른 점으로 이동할 때 분할 및 통합을 인정하는 설정
◦
수송원, 수송처의 확률 측도를 각각 𝛼, 𝛽로 표기
◦
엔트로피 정규화 OT (Entory-Regularized OT; EROT)
•
수치 계산으로 OT를 취급할 때는 엔트로피 정규화를 더한 완화 문제를 생각하는 경우가 많습니다.
•
비용 함수가 𝜋에 관해 강볼록하게 되므로, 최적해가 고유하게 정해져서 수치계산이 편합니다.
•
원래 OT는 볼록하지만 일반적으로 강볼록하지 않기 때문에 최적해는 고유하지 않습니다.
•
여기서 는 미분 엔트로피.
•
식 (14)에서는 측도 𝜋에 대응하는 밀도함수 가 존재한다고 가정합니다.
•
SB와 OT의 관계
•
확률 밀도 함수가 존재할 때의 증명은 다음과 같습니다.
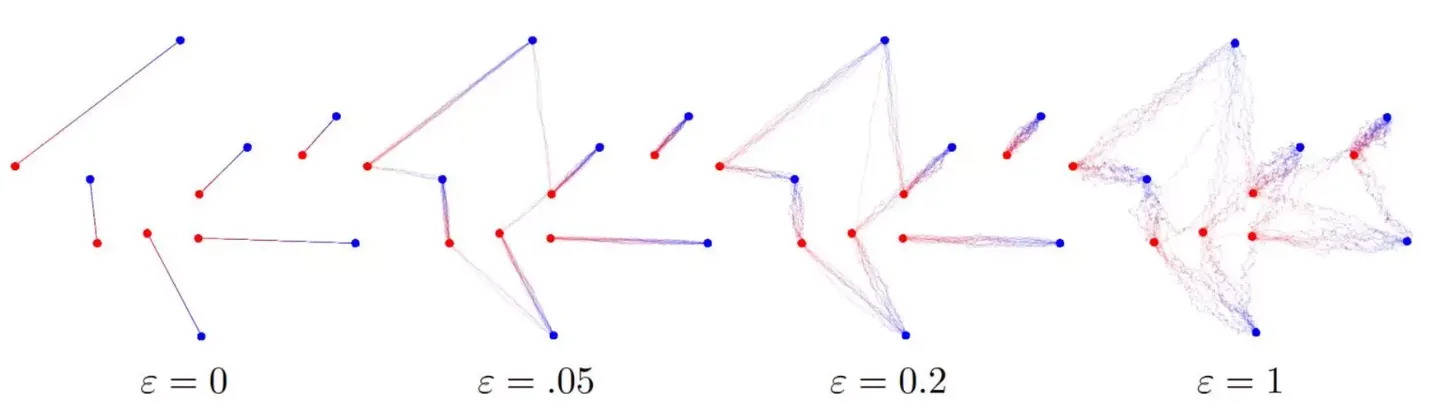
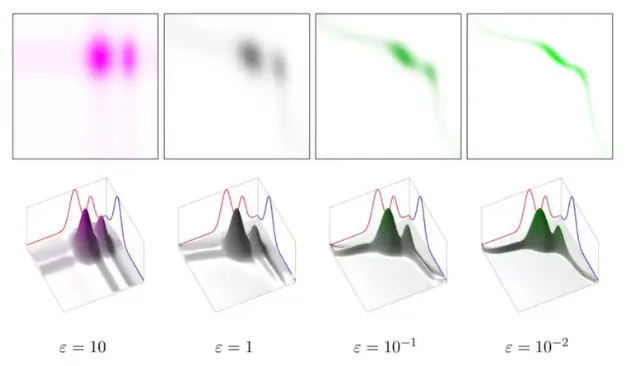
이산 EROT의 해로 구성된 mixture of bridges
•
파란색 점들로부터 빨간색 점들로의 수송 경로 (각 점의 질량은 모두 동일하다고 가정)
•
엔트로피항의 기여(𝜀) 가 커질수록 허용 가능한 bridge가 다양화되는 경향을 보입니다.
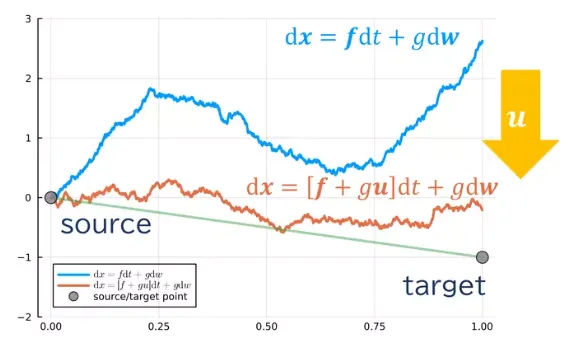
SB 재정의: 확률 최적 제어 문제
•
패스 측도는 그대로라면 다루기 어려우므로 SDE를 이용한 표현으로 바꾸기로 합니다.
◦
•
◦
여기서 일때 상태 방정식
◦
참조 경로 측도 ℚ 보다 유도되는 확률장 (SDE: ) 을 떠도는 입자에 대하여 외력(𝒖)을 제어하여 초기치 에서 목표 로 이끄는 문제
◦
최소의 작용 () 으로 목적을 달성할 수 있을 때의 𝒖가 최적해
SB 재정의: Schrodinger System
•
◦
이때 는 Schrödinger potential, PDE 는 Schrödinger system.
◦
각각 Kolmogorov의 Forward/Reverse Process에 해당하지만, 서로 다른 포텐셜을 사용함.
•
Schrödinger system의 해 , 을 사용하면 와 는 다음과 같습니다.
•
즉, 중간과정은 , 와 를 따르는 밀도함수 를 분해한 것으로 볼 수 있습니다.
•
구체적으로 , 를 구하는 방법은 후술하겠습니다.
SB 재정의: Forward · Reverse SDE
•
상태 방정식의 제어 변수 을 최적 포텐셜 , 로 대체함으로써 SB의 해는 다음의Forward·Reverse SDE로 표현할 수 있습니다. [19]
◦
각 SDE는 reverse-time formula [12]에 의해 상호 변환 가능
•
즉, Schrödinger bridge 문제는 다음과 같이 바꿀 수 있습니다.
확률분포 와 참조측도 (확률장) 가 주어졌을 때,
Schrödinger system을 만족시키는 함수 쌍 , 을 구하는 문제.
SB 학습 및 생성과정


•
학습과정
1.
데이터 분포를 준비:
2.
기준 측도를 SDE로 설계:
3.
Schrödinger system을 충족시키기 위해 매개변수화 된 모델 훈련 (, 중간 학습)
•
생성과정
1.
초기 데이터 x를 에서 샘플
2.
학습된 모델을 사용하여 초기조건 x 하에서 Reverse SDE를 품:
SGM과의 관계

•
SB는 확산모델의 확장이라고 볼 수 있습니다.
•
확산 모델의 Forward Reverse SDE는 의 제약은 둔 SB와 같습니다.
•
이 때, 가 성립합니다.
•
더 엄밀히 말하면, 사전 분포의 제약 조건을 푸는 대신 전진 과정도 학습 파라미터화한 확산 모델이 Schrödinger bridge입니다.
결론
•
Schrödinger Bridge (SB)는 사전 분포의 제약을 완화 한 확산 모델입니다.
•
SB는 Dynamic Optimal Transport 문제로 간주 될 수 있습니다.
•
T. Chen et al. (2021)에 따르면 Forward 및 Reverse Process SDE의 동시 최적화로 볼 수 있습니다.
더 알아볼 내용
1.
기준 경로 측도 의 설계 방법
•
확률 최적 제어 문제의 확률 필드 (SDE)
•
드리프트 계수 와 확산 계수 는 어떻게 설계해야 할까?
2.
SB 모델 훈련 알고리즘
•
Schrödinger potential , 의 최적 해를 구하는 방법
•
기계 학습 프레임 워크에 가져올 때, 어떻게 매개 변수화하는 것이 바람직할까?
•
◦
•
•
Iterative Markov Fitting (IMF)
•
Computer Vision 응용
◦
•
관련 알고리즘
◦
◦