


AICA X NVIDIA Cluster GPU 교육 시리즈
7. Inference 최적화를 위한 TensorRT
홍광수 박사 (솔루션 아키텍트, NVIDIA))
NVIDIA x AICA Cluster GPU 활용 캠프 (2024/08/26 - 09/05)
•
Inference 최적화에 관해 알아본다.
•
TensorRT와 TensorRT-LLM에 대해 알아본다.
Introduction
•
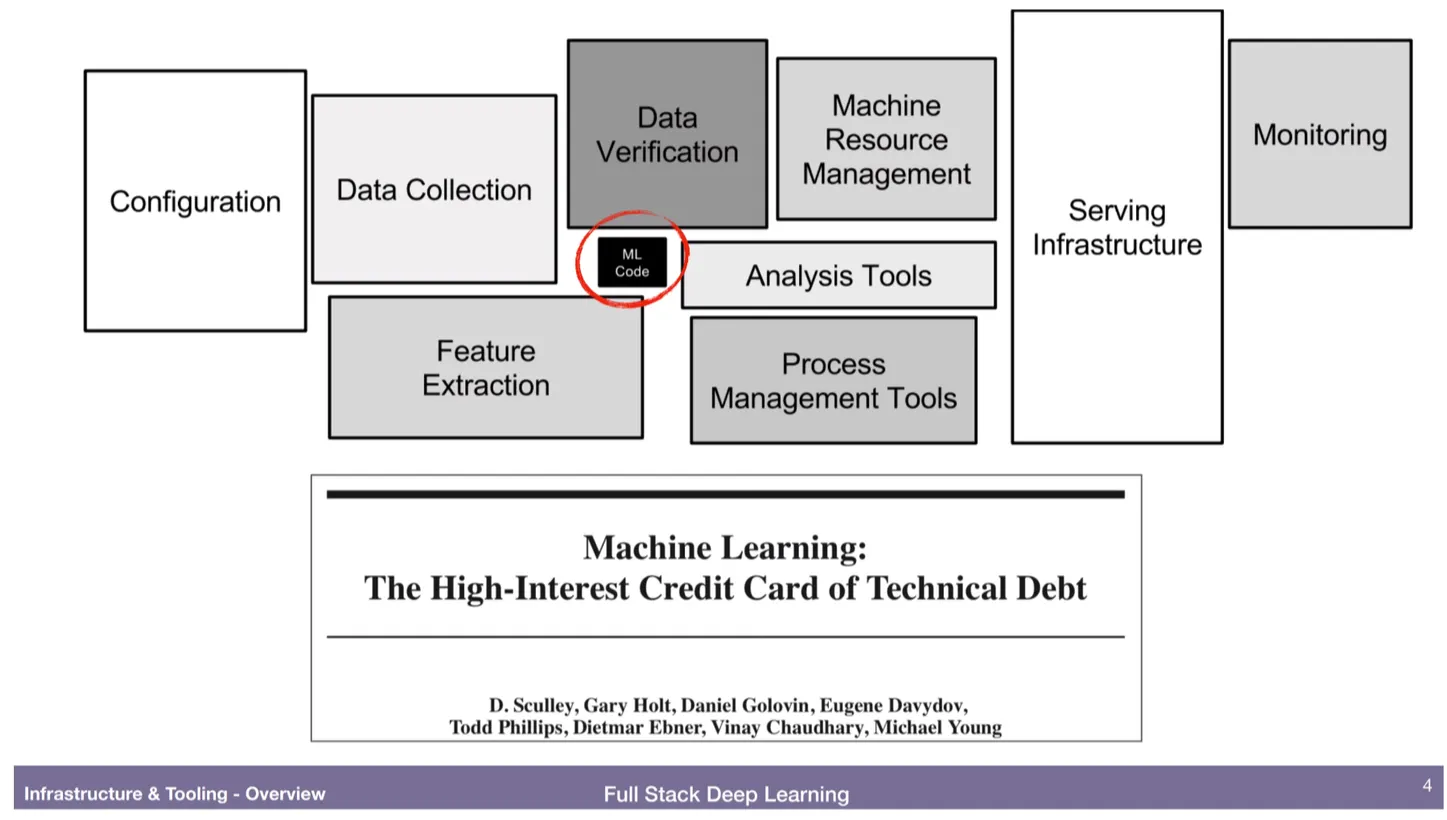
ML 시스템에서 코드 부분은 굉장히 작은 부분을 차지한다.
•
그러므로 Infrastructure, serving, workflow, 리소스 관리등의 도움이 있어야 전체 프로젝트가 완성된다.
•
그렇다면 어떻게 효율적으로 Serving할 수 있을까?
•
어떻게 적은 Engineering Effort를 투입할 수 있을까?
•
이를 도와주는 Product는 무엇이 있을까?
TensorRT for model optimization
•
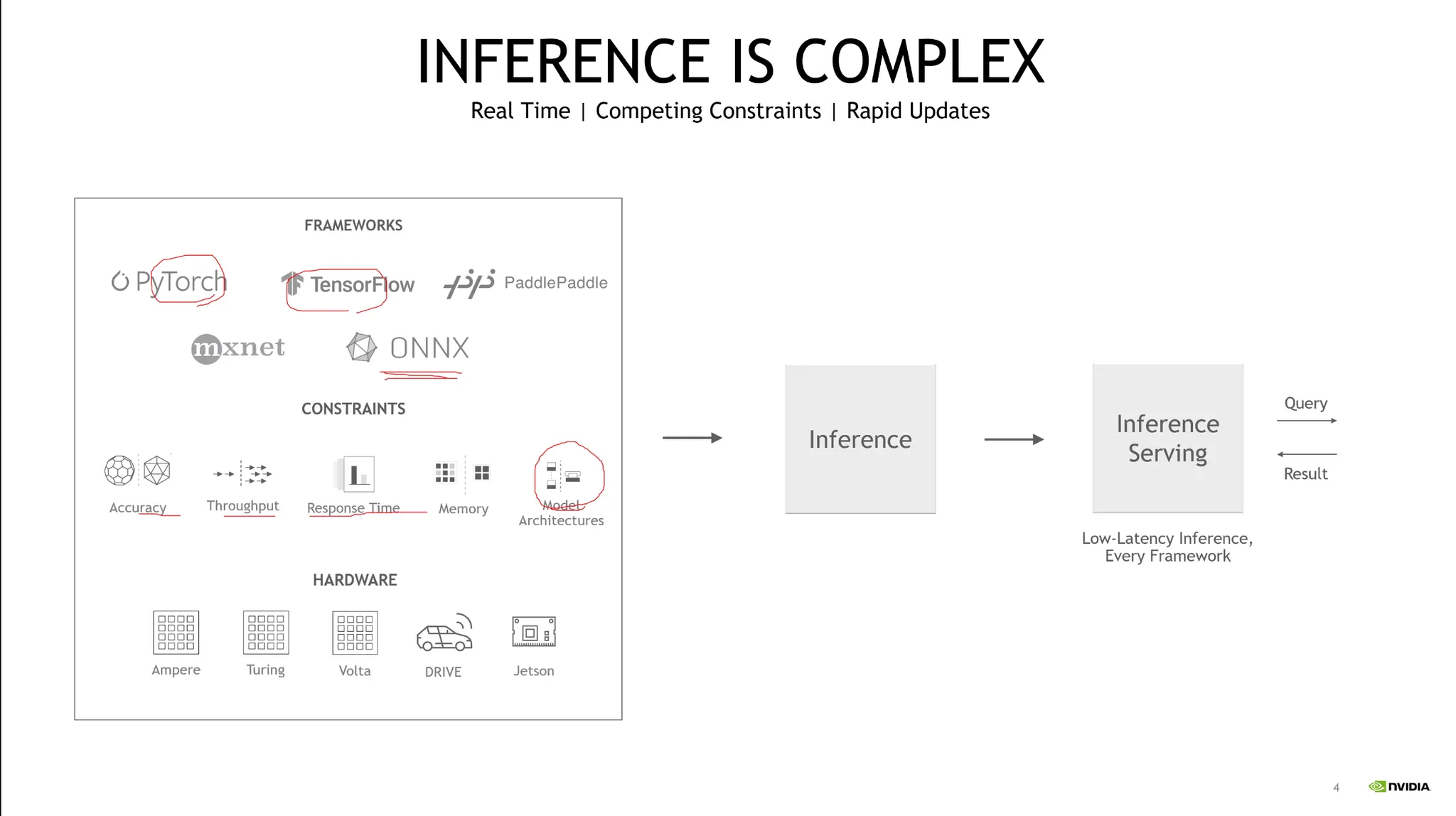
보통 Pytorch등을 사용해 개발한다.
•
이는 Training에 focusing된 라이브러리로써, Inference시에 최적화가 되지 않는다.
•
개발자의 개발 편의성과 성능에는 Tradeoff가 존재한다.
•
Inference의 속도 뿐 아니라 Hardware dependency에 맞추어 최적화를 수행해야 한다.
•
이를 도와주는 것이 TensorRT 가 될 수 있다.
•
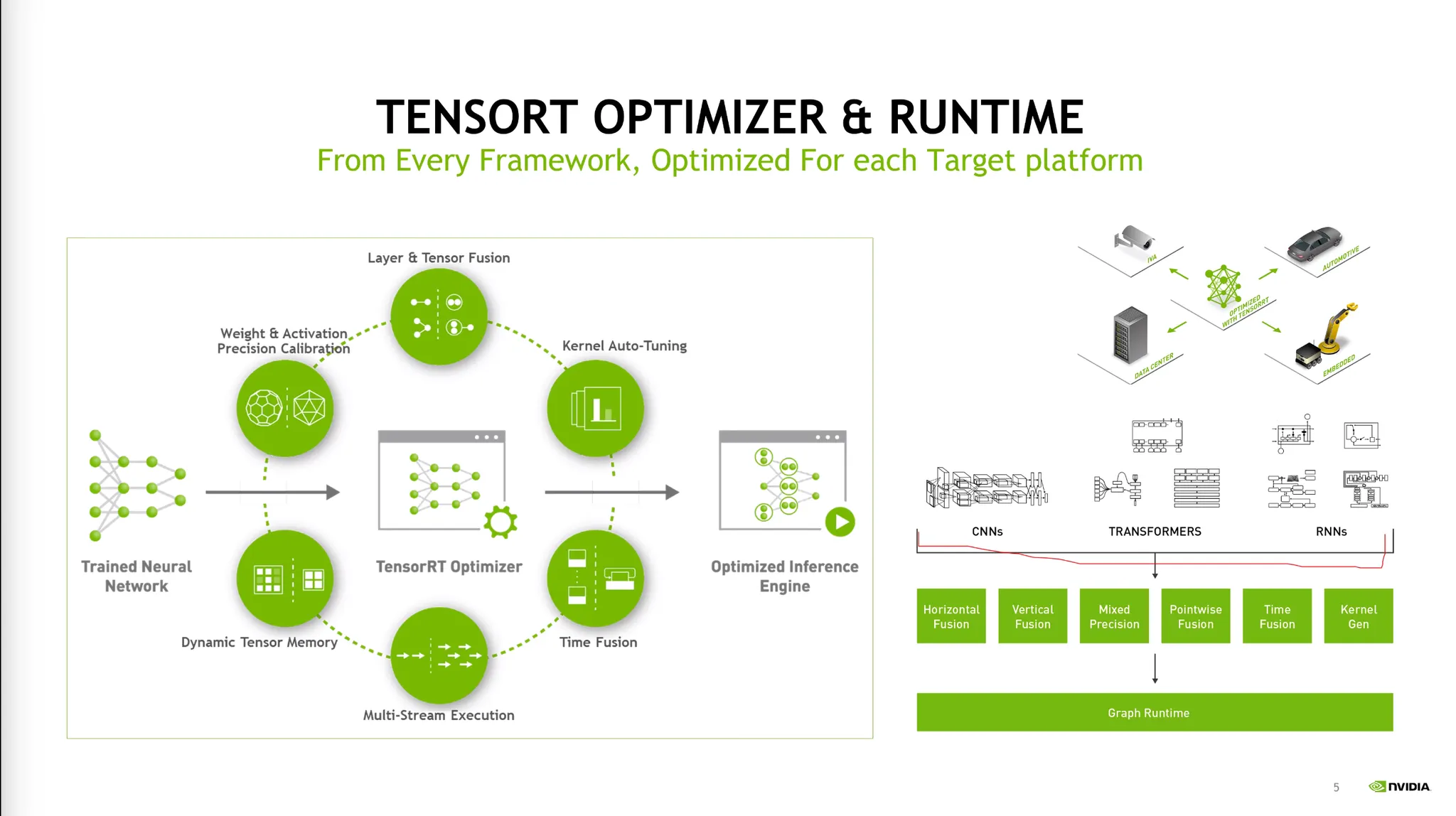
다양한 딥러닝 모델을 하나의 Target에 맞추어 최적화를 해주어야 한다.
◦
예를 들어 같은 모델이라고 해도 임베디드, 서버등에 맞추어 최적화를 해주어야 한다.
◦
이는 딥러닝 프레임워크가 할 수 없는 영역이다.
•
이를 해결하기 위해 TensorRT를 사용한다.
◦
Layer Fusion, Auto-tuning등 여러 기능을 제공한다.
1. Reduce Mixed Precision
•
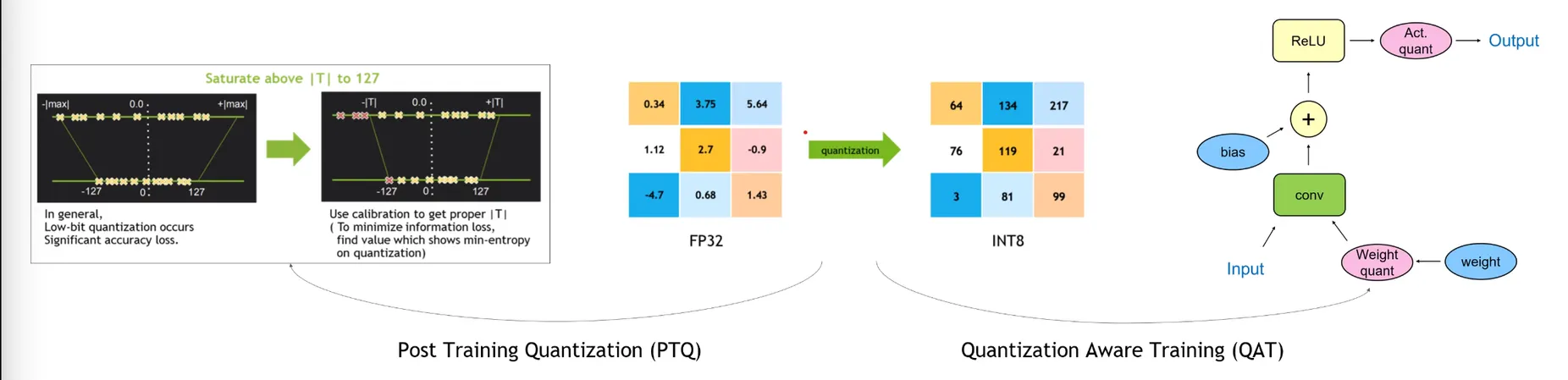
quantization을 통해 Precision을 낮추어 최적화를 진행할 수 있다.
Reduced Precision의 장점:
•
FLOP 증가
•
memory footprint와 bandwidth workload 감소
Reduced Precision의 종류:
1.
Post Training Quantization (PTQ)
•
이미 학습된 모델에 대하여 Quantization을 수행한다.
•
Sample Input을 넣어 최적화를 진행한다.
•
빠르지만 정확도가 다소 떨어진다.
2.
Quantization Aware Training (QAT)
•
Quantization을 하며 학습을 진행하는 방법.
•
느리지만 정확도가 다소 높다.
2. Layer & Tensor Fusion
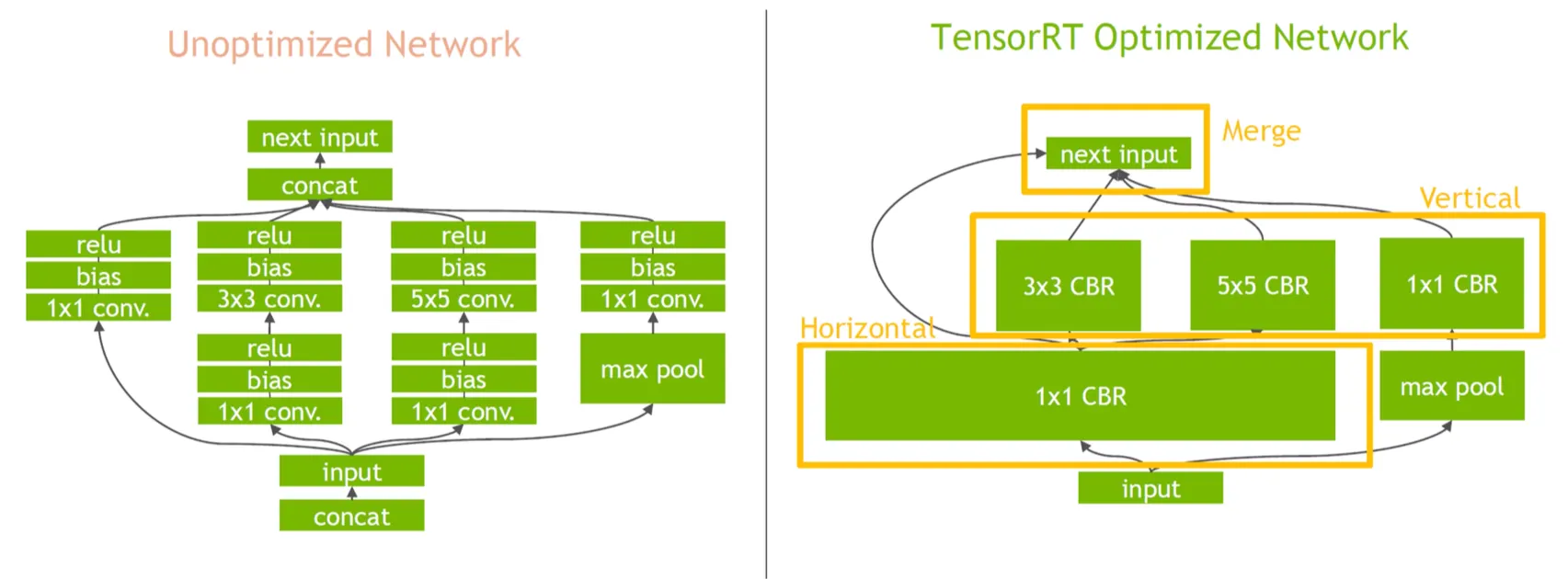
InceptionNet에 대한 예시.
•
여러 레이어나 비슷한 연산을 한번에 수행한다.(Vertical, Horizontal)
•
Transformer Engine이 하는 역할은 FP8 + Layer Fusion을 함께 수행한다.
3. Kernel Auto-tuning
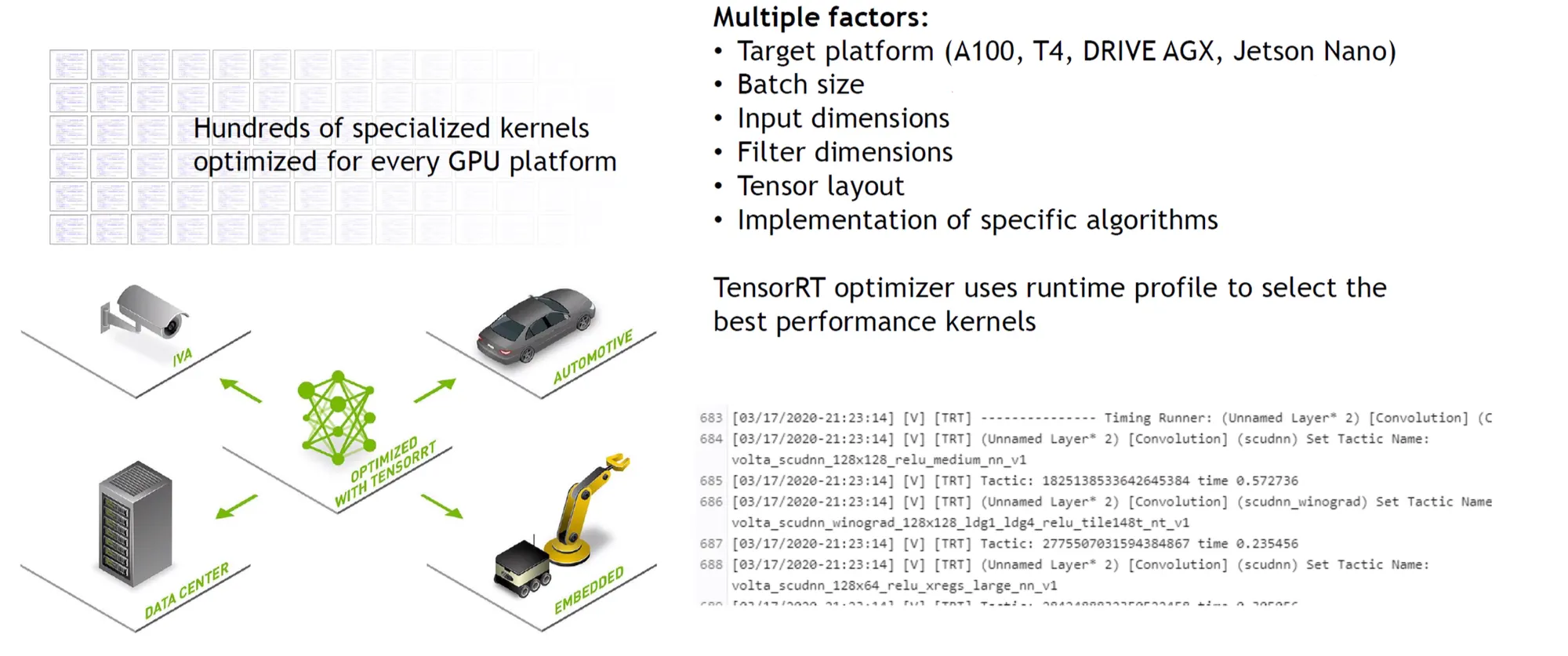
•
같은 함수라도 Hardware Architecture별로 최적화된 함수가 다르다.
•
Target Hardware에 맞게끔 최적의 커널을 프로파일링하여 선택할 수 있도록 도와준다.
4. Dynamic Tensor Memory
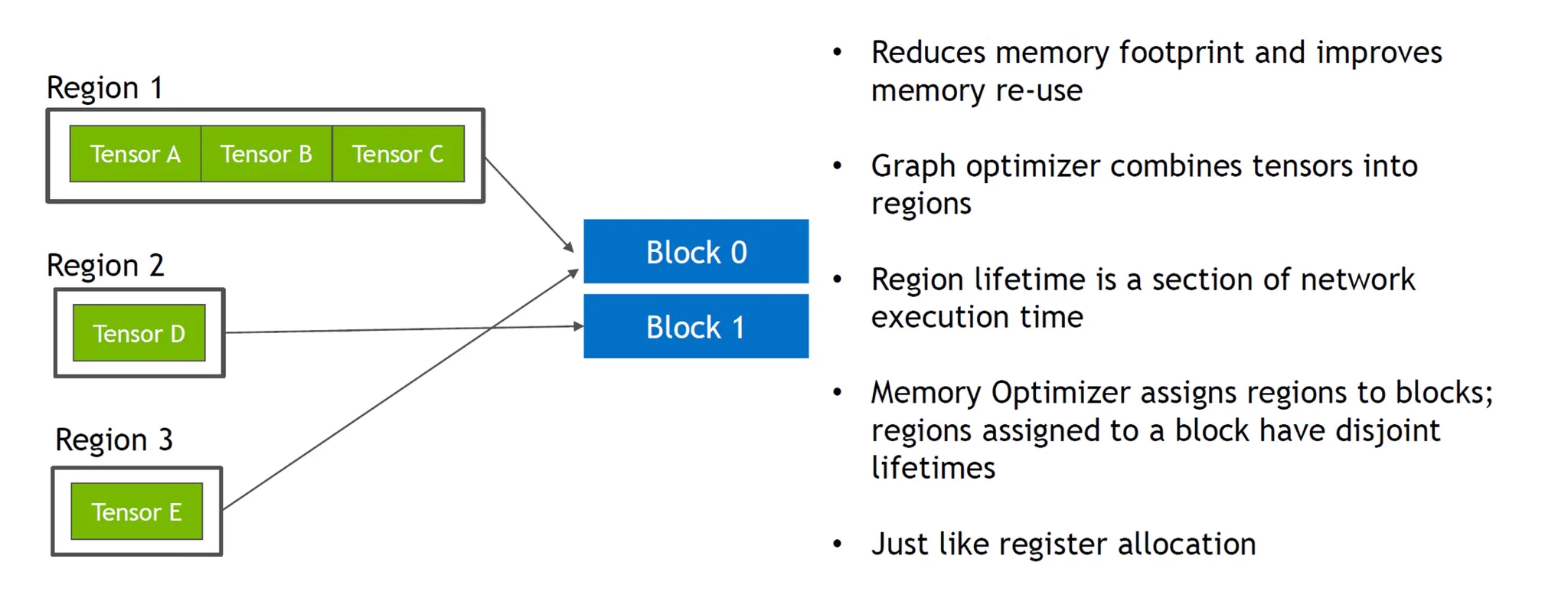
•
Region별로 메모리 블럭을 만든 후 공유하며 재사용하는 기법.
•
메모리 레지스터의 개념
5. Multi-Stream Concurrent Execution
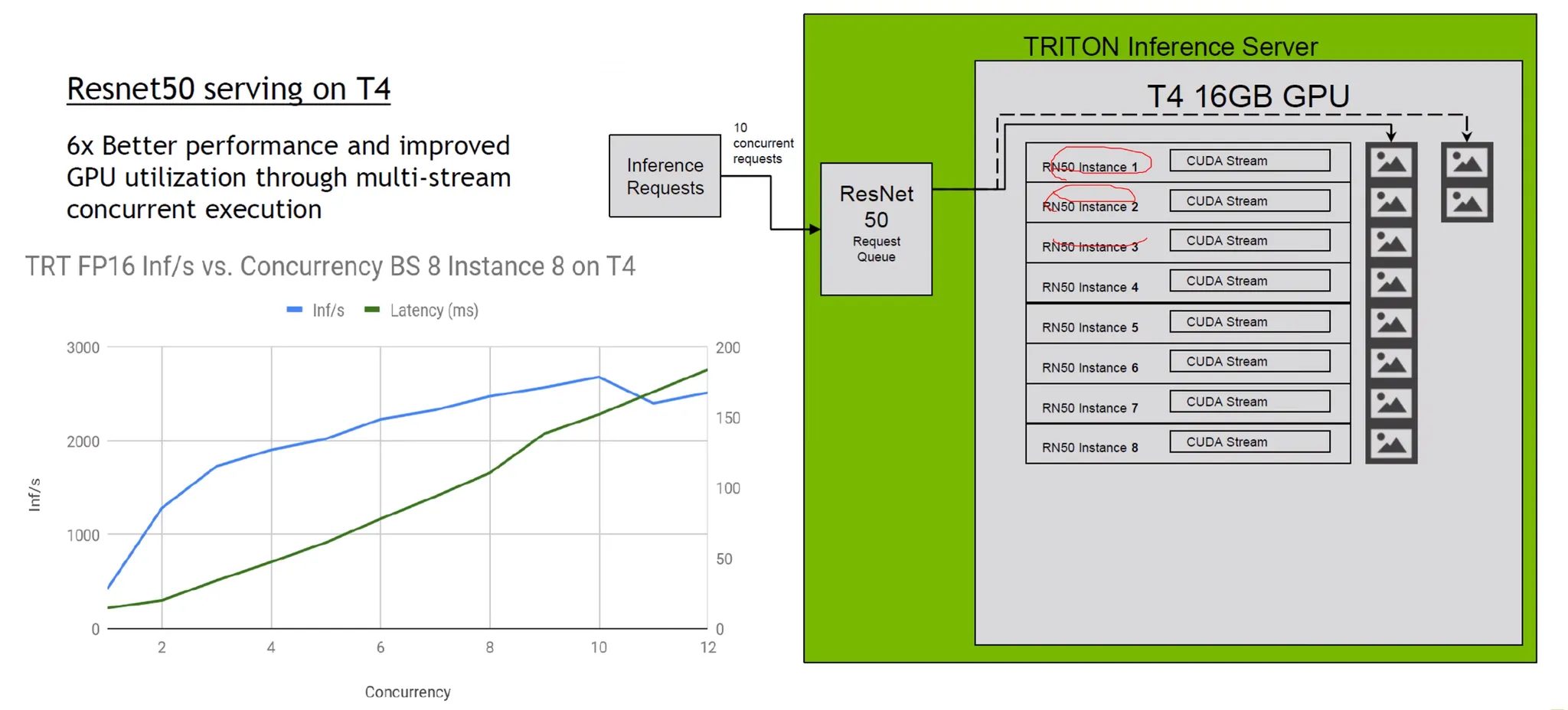
•
여러개의 instance를 동시에 실행하는 기법
Optimization for LLM
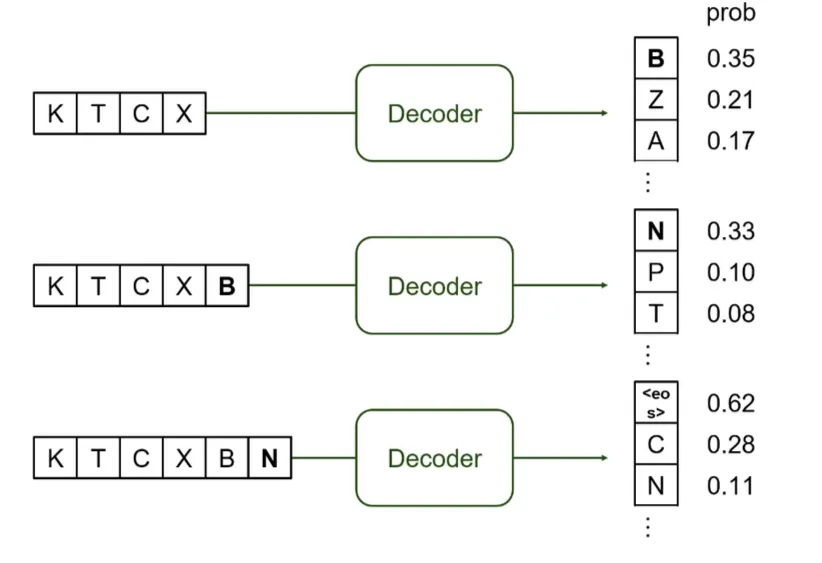
LLM의 특징
•
Input으로 Token이 왔을 때 확률값을 가지고 하나씩 generation 하는 것이라고 말할 수 있다.
◦
Input Sequence는 token id들의 Array로 볼 수 있다. (KTCX)
◦
Input token (KTCX)을 Decoder로 feed해서 다음 token을 예측한다. (B)
◦
Input token과 predicted token을 (KTCXB) Decoder로 feed해서 그 다음 token을 예측한다. (N)
◦
<EOS> token이 나올때까지 이를 반복한다.
이때 어떤 최적화 포인트를 가질 수 있을까?
1) KV-Cache
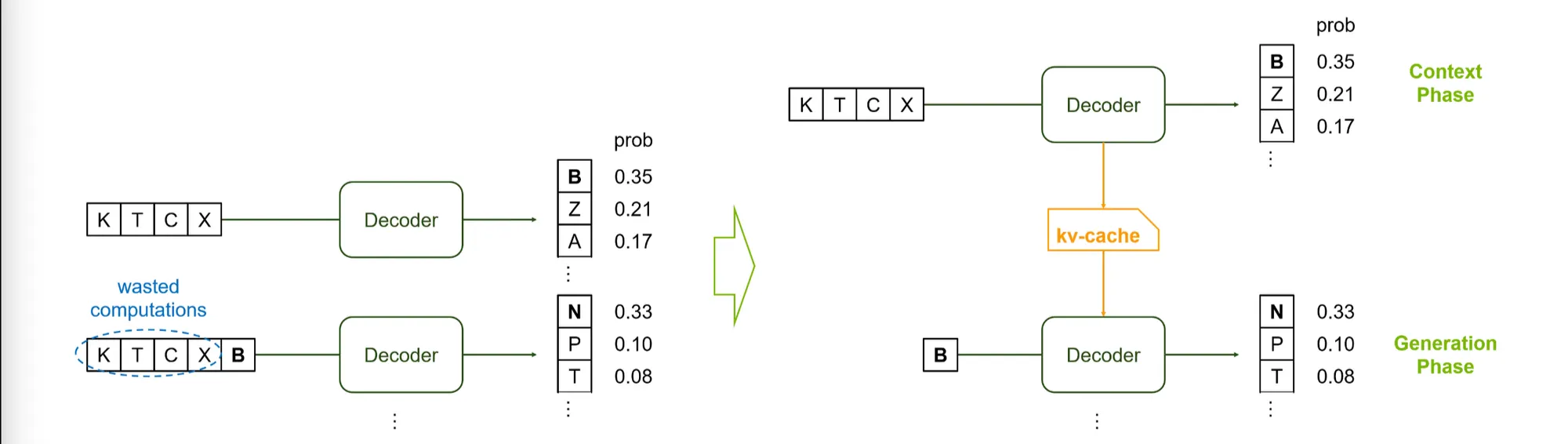
•
KV Attention은 재활용이 가능하다.
•
이전에 계산된 KV값들을 캐쉬로 저장하고 이를 이용해 next step을 계산한다.
2) Int8 SmoothQuant
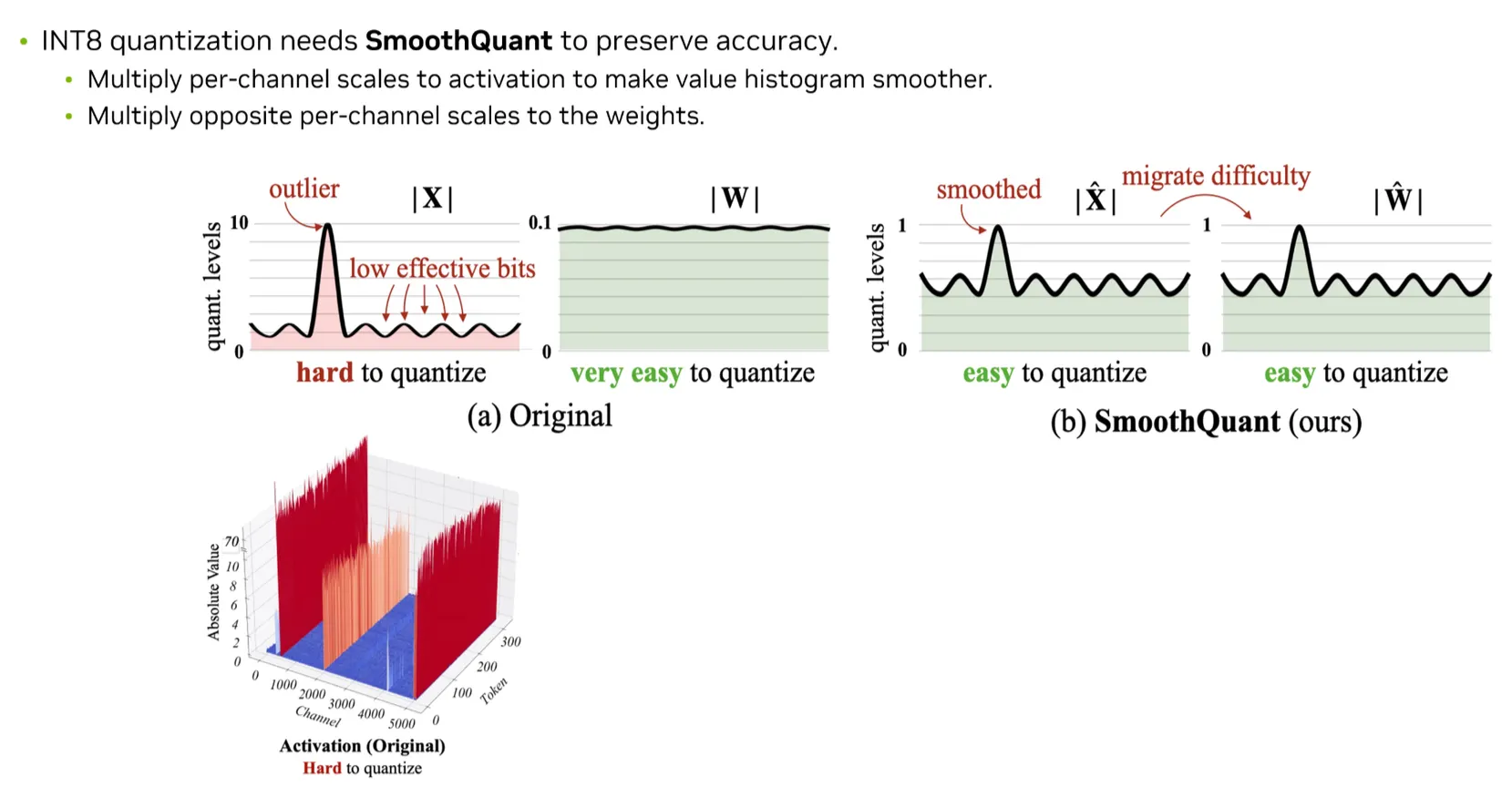
: Activation의 확률값, : Weight의 확률 값
•
Weight와 Activation 모두 Quantization해주는 기법
1.
Weight에 대한 Quantization은 쉬운 반면 Activation에 대한 Quantization은 매우 어렵다.
2.
Channel별로 Outlier가 존재한다.
→ Channel별로 Scaling값을 만들어주는 것이 중요하다.
•
SmoothQuant: Activation에 대한 Scaling값을 가지고 Weight 역시 Scaling을 해준다.
4) Weight-Only Quantization

•
Weight만 Quantization을 하는 방법.
•
Activation의 distribution을 분석하여 scaling을 도출하게 된다.
•
모델에 대한 weight에 1%만 살려도 Quantization Error를 크게 줄일 수 있다.
5) Multi-GPU Inference
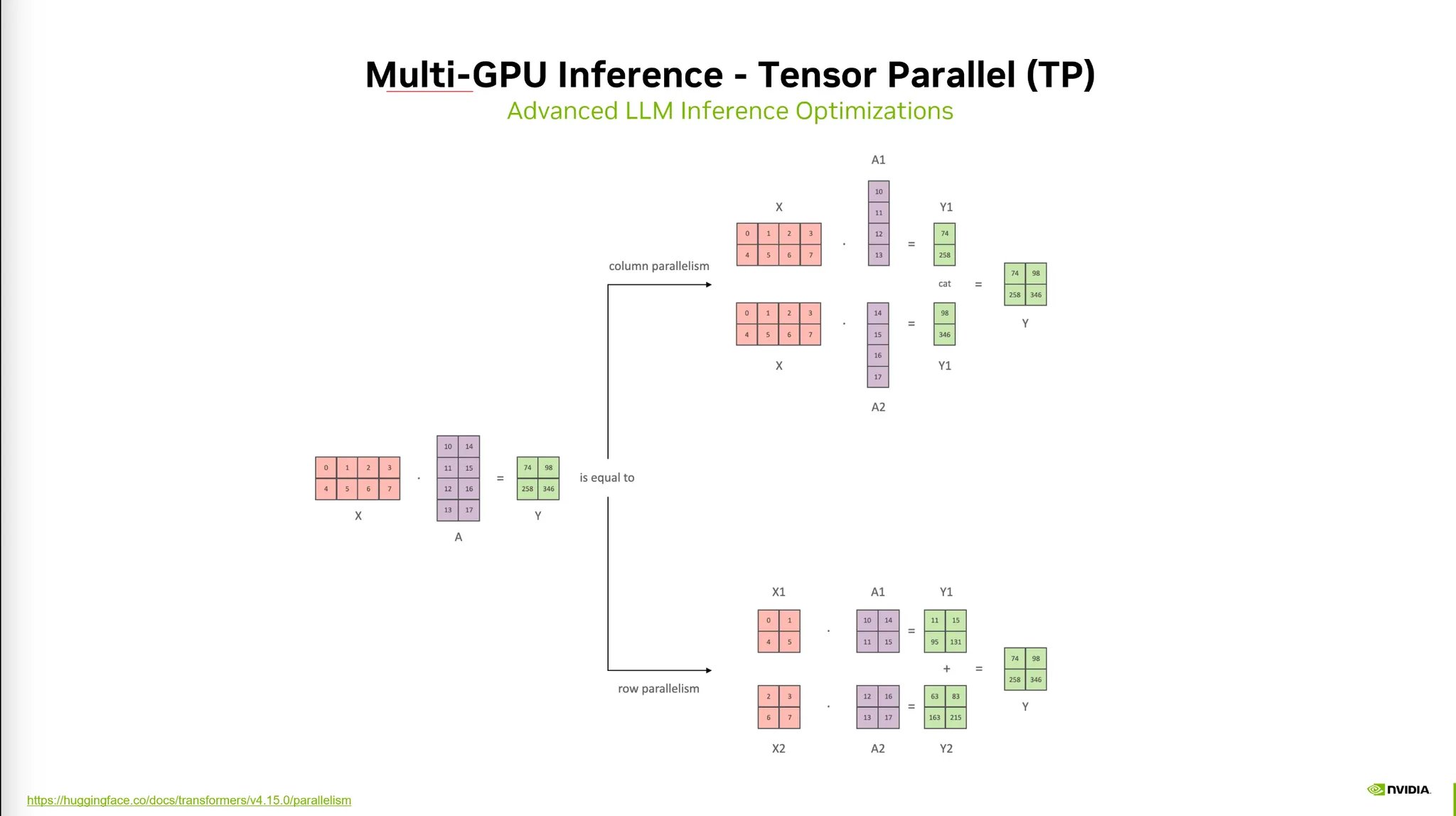
1.
TensorParallel
2.
PipelineParallel
6) In-Flight Batching
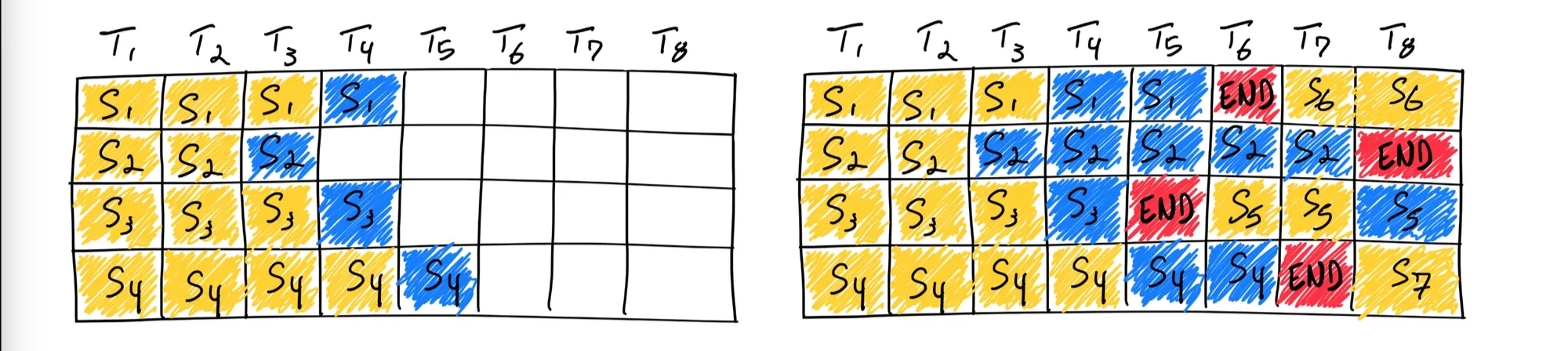
•
한 batch가 끝날 때 까지 기다리는 것이 아니라, end토큰이 나오면 다음 배치를 바로 시작한다.
7) Paged KV-cache
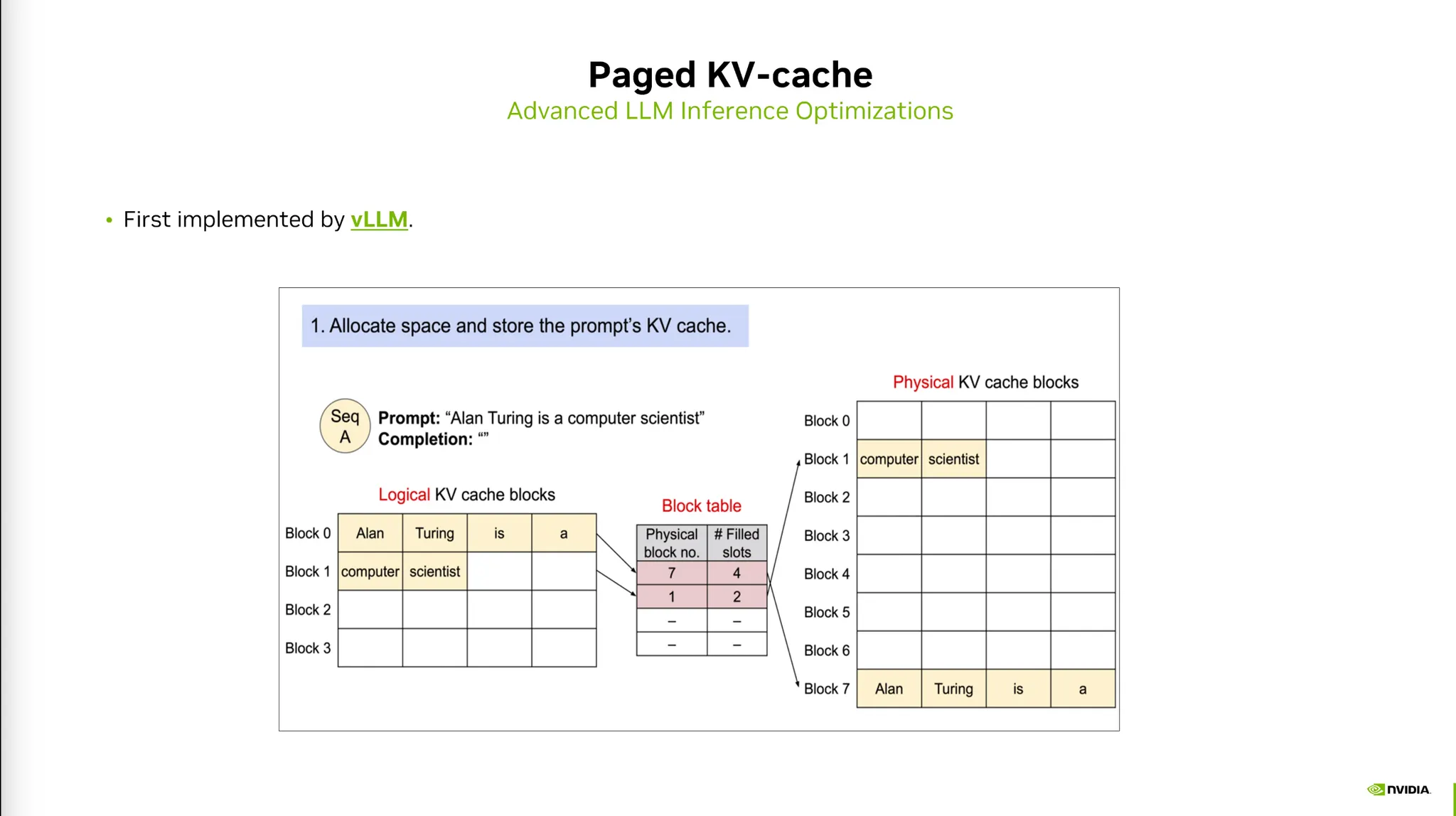
•
KV Cache를 저장할 때 Context가 얼마나 커질 지 모른다.
•
미리 큰 메모리를 할당하면 효율성이 매우 떨어진다.
•
이를 해결하기 위해 동적으로 메모리를 할당하는 기법이다.
◦
물리적으로 메모리 영역을 떨어뜨려놓아 mapping table을 통해 동적으로 할당한다.
8) Memory Offloading to CPU
•
Weight나 KV-Cache를 GPU에서 CPU Memory로 offload 해주는 기법
◦
Prefetch weights/kv-cache to GPU memory while running other layers.
◦
Allows running large models on single GPU.
•
LLM Inference tends to be very mem-bound.
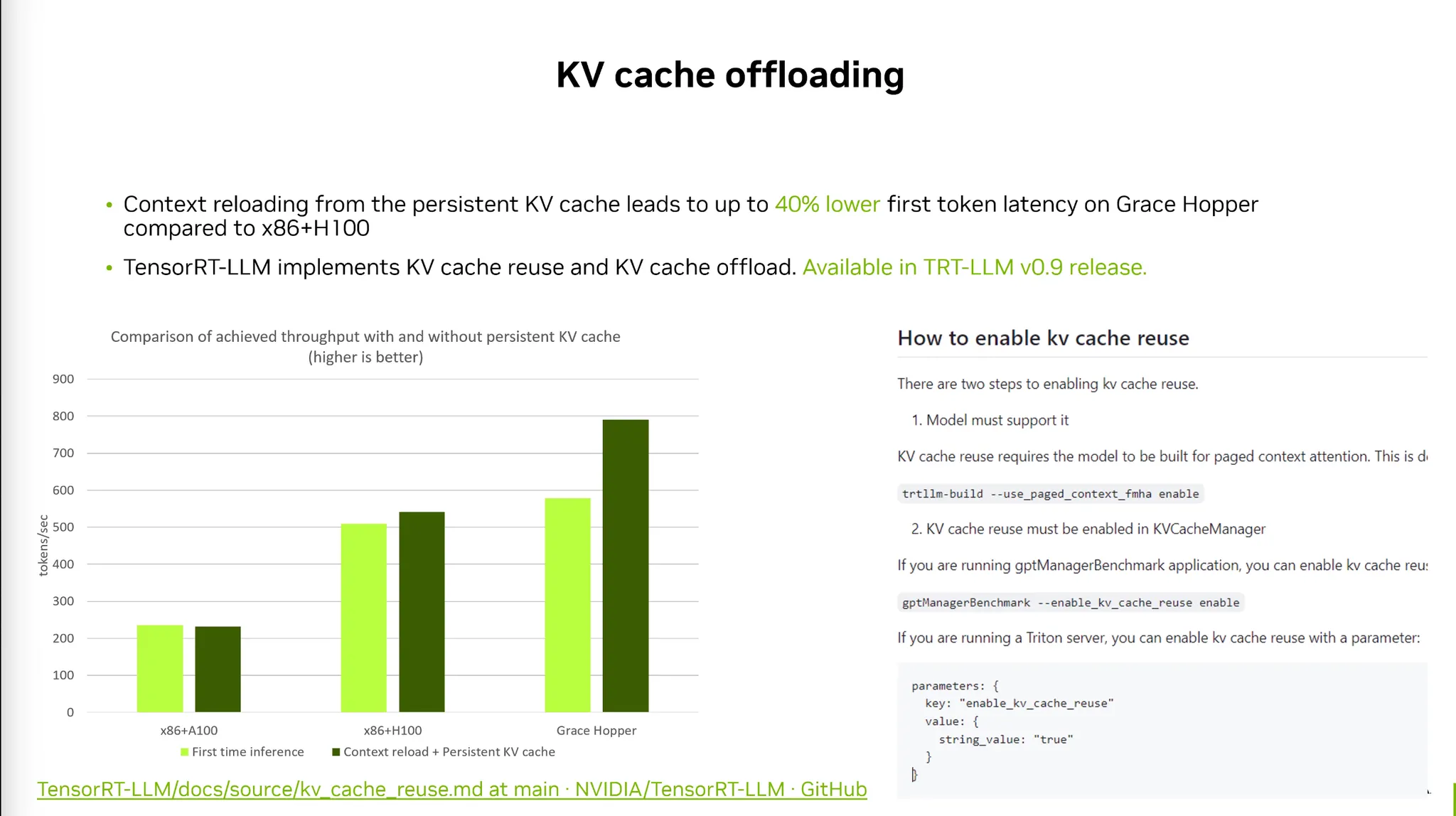
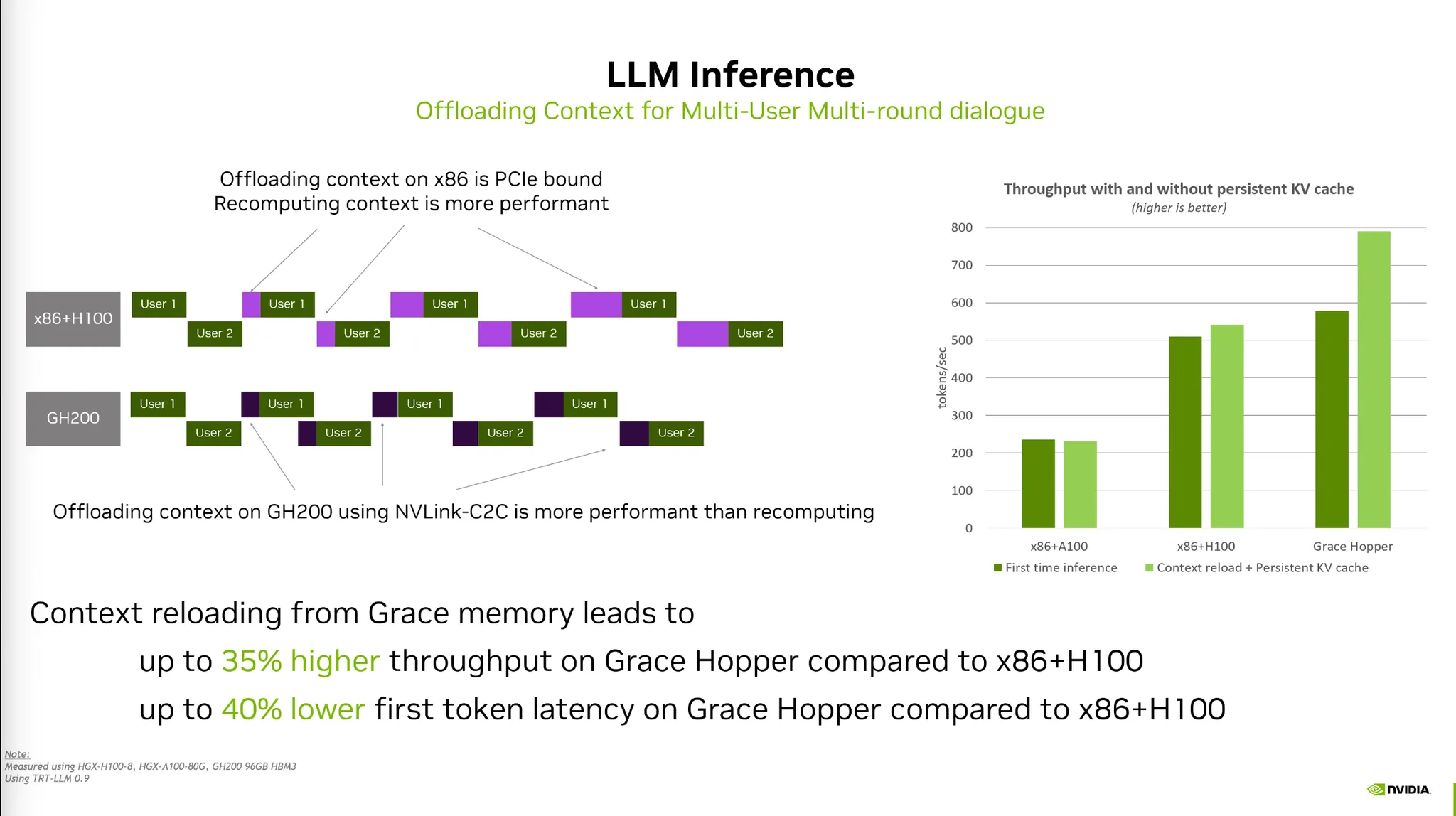
왜?
•
Multi-user가 multi-turn으로 대화를 진행하는 Multiround가 있다고 가정하자.
•
이 때 user 1 / 2 의 KV Cache값을 가지고 있다면 메모리사용량이 굉장히 많아진다.
•
따라서 CPU memory로 offload 해주는 전략이 필요하다.
•
이 때 PCIe bound bottleneck이 존재할 수 있다.
◦
최신 Grasshoper 아키텍처는 온칩 설계와 NVLink로 대역폭을 확보했다.
9) Multiple LoRA Support
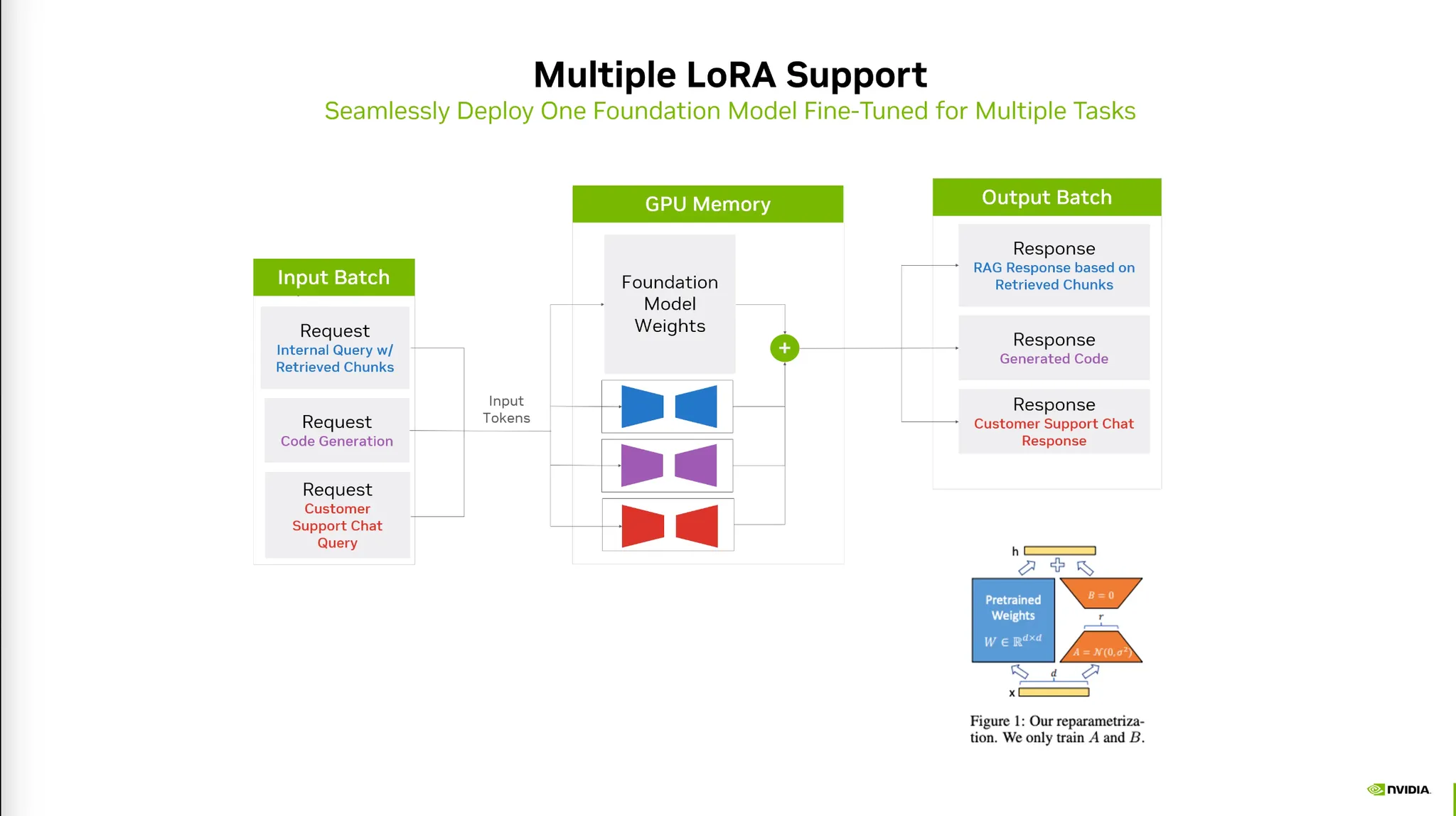
•
여러가지 LoRA에 대한 학습과 Inference를 지원한다.
10) Speculative Inference (Speculative Decoding)
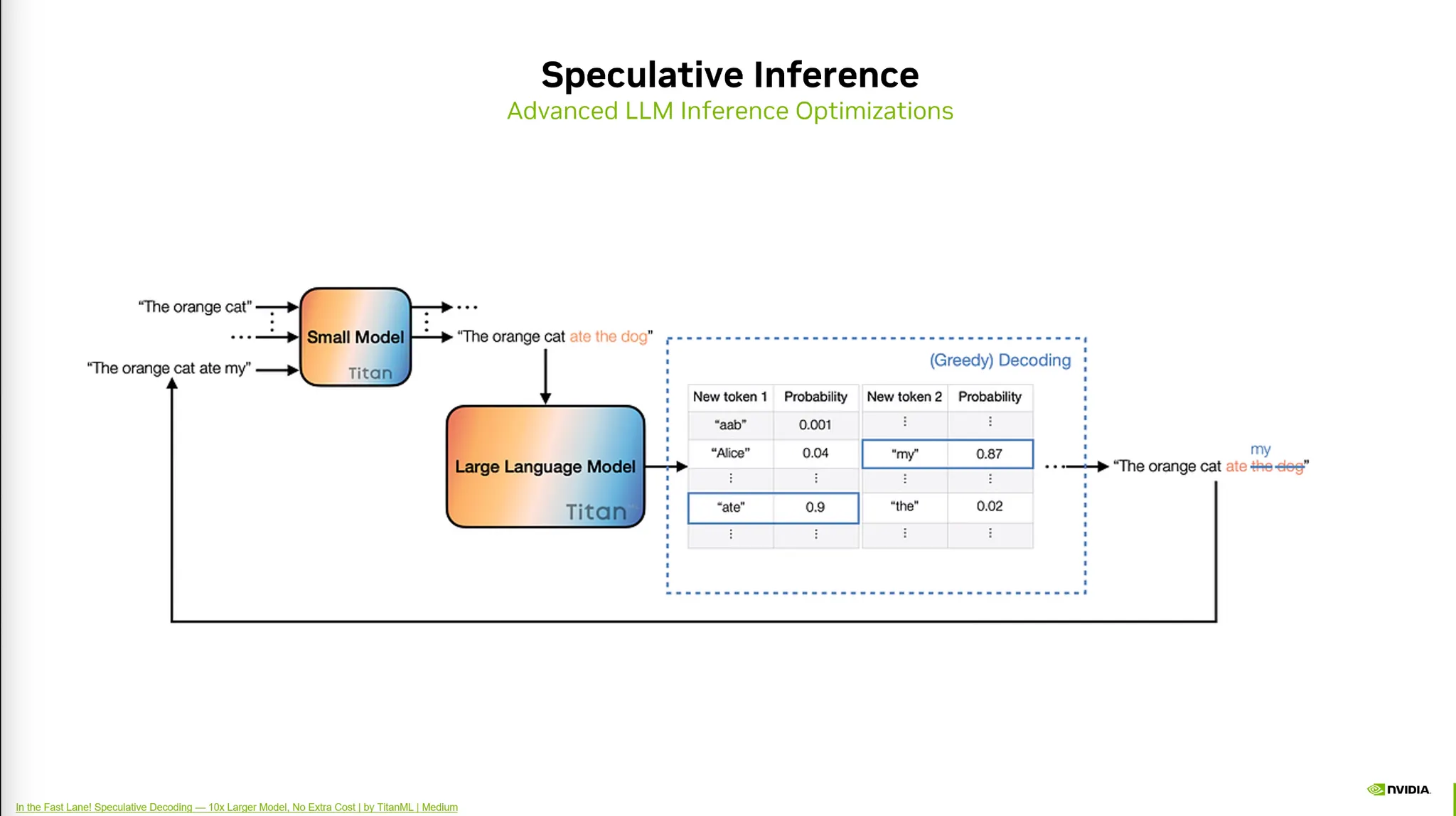
•
개요: Inference를 더욱 빠르게 하기 위한 알고리즘적인 방법.
◦
작은 모델과 큰 모델을 이용해 Inference를 빠르게 수행한다.
•
전제: 작은 모델은 큰 모델과 유사한 정확도를 가져야 한다.
•
목적: 작은 모델의 Acceptence Rate를 높이는 과정이다.
•
방법:
◦
상대적으로 큰 모델과 작은 모델 (Draft Model)을 준비한다.
◦
작은 모델은 Inference시 성능이 떨어진다.
◦
이를 해결하기 위해 큰 모델을 이용하여 검증만 해준다.
TensorRT-LLM
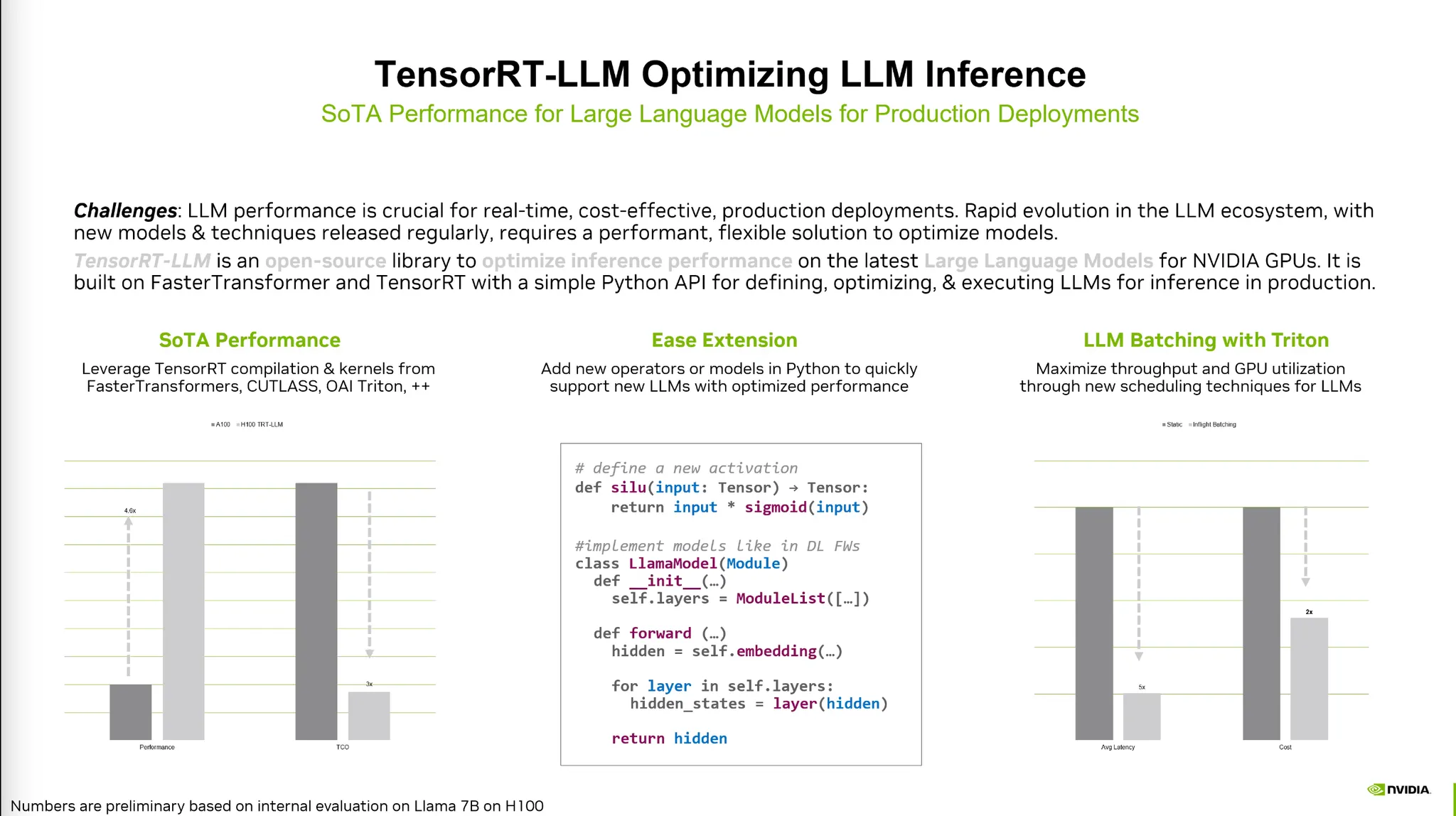
•
TensorRT-LLM: 파이썬기반의 최적화 툴.
•
Pytorch 모듈을 상속하여 사용할 수 있다.

•
위에 설명했던 기법들을 포함하고 있다.

•
Huggingface 버전으로 모델을 convert하고 build 후 execution해주는 과정

•
Python-like한 definition이 가능하다.

•
새로운 모듈도 쉽게 정의가 가능하다.
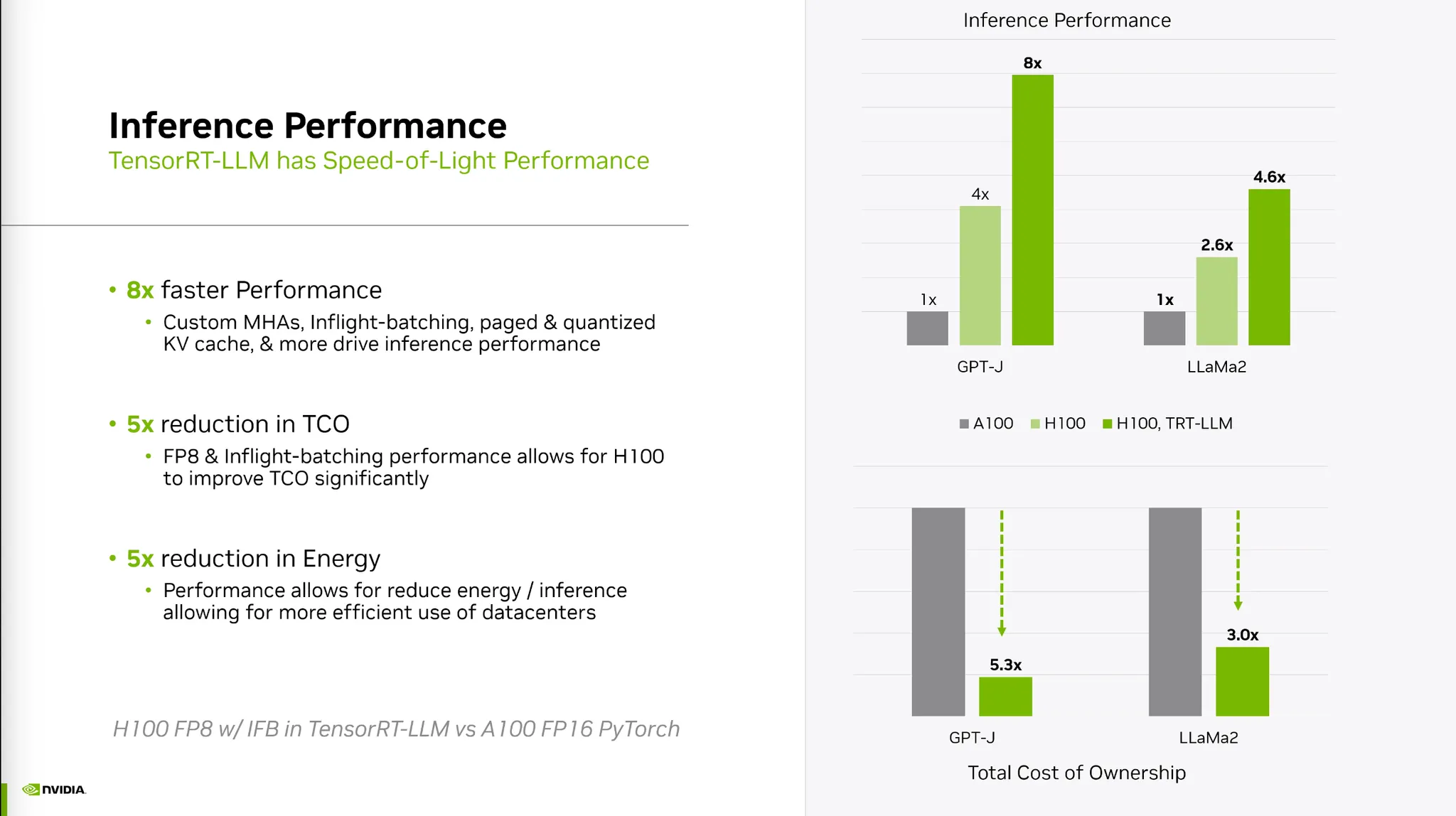
•
퍼포먼스와 비용적인 측면 모두 개선이 가능하다.
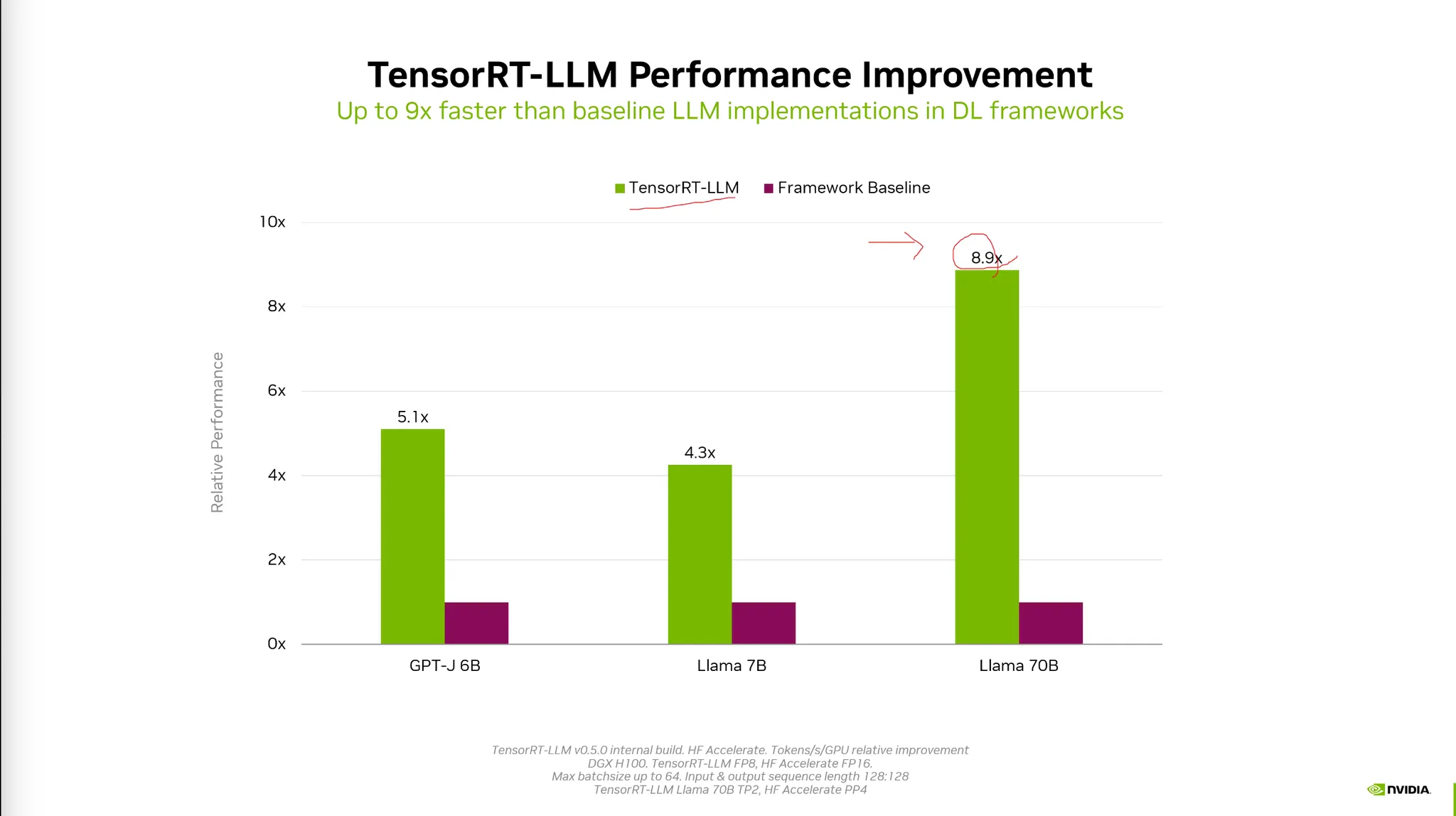
•
Precision차이때문에 퍼포먼스의 차이는 거 커진다.
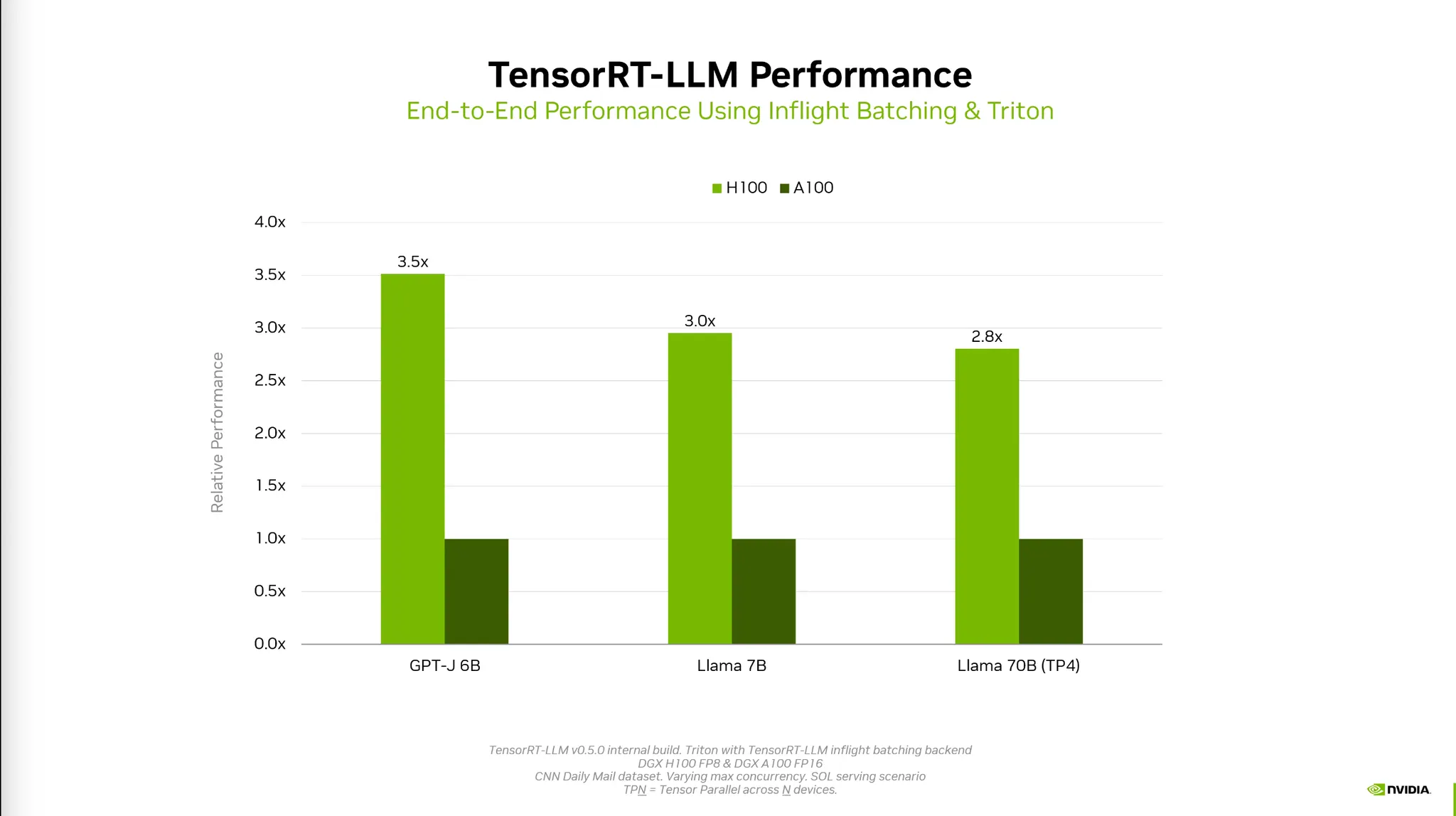
•
Triton을 함께 사용하면 더 좋아진다.
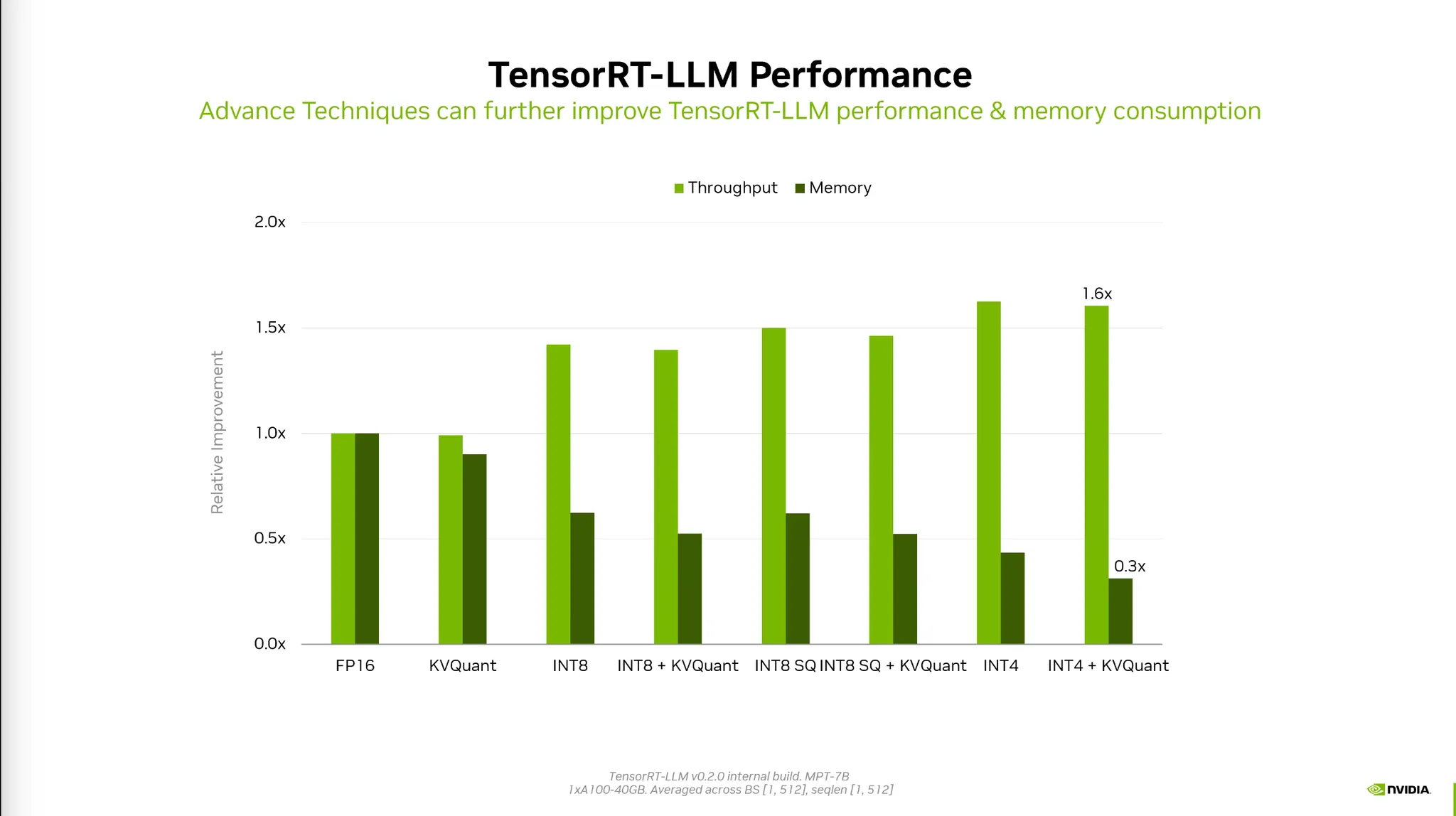
•
Quantization 방법에 따라 메모리와 Throughput 모두 개선된다.
•
정확도는 Tradeoff가 발생하므로 이를 고려하여 최적의 Precision을 결정해야 한다.
Triton Inference Server
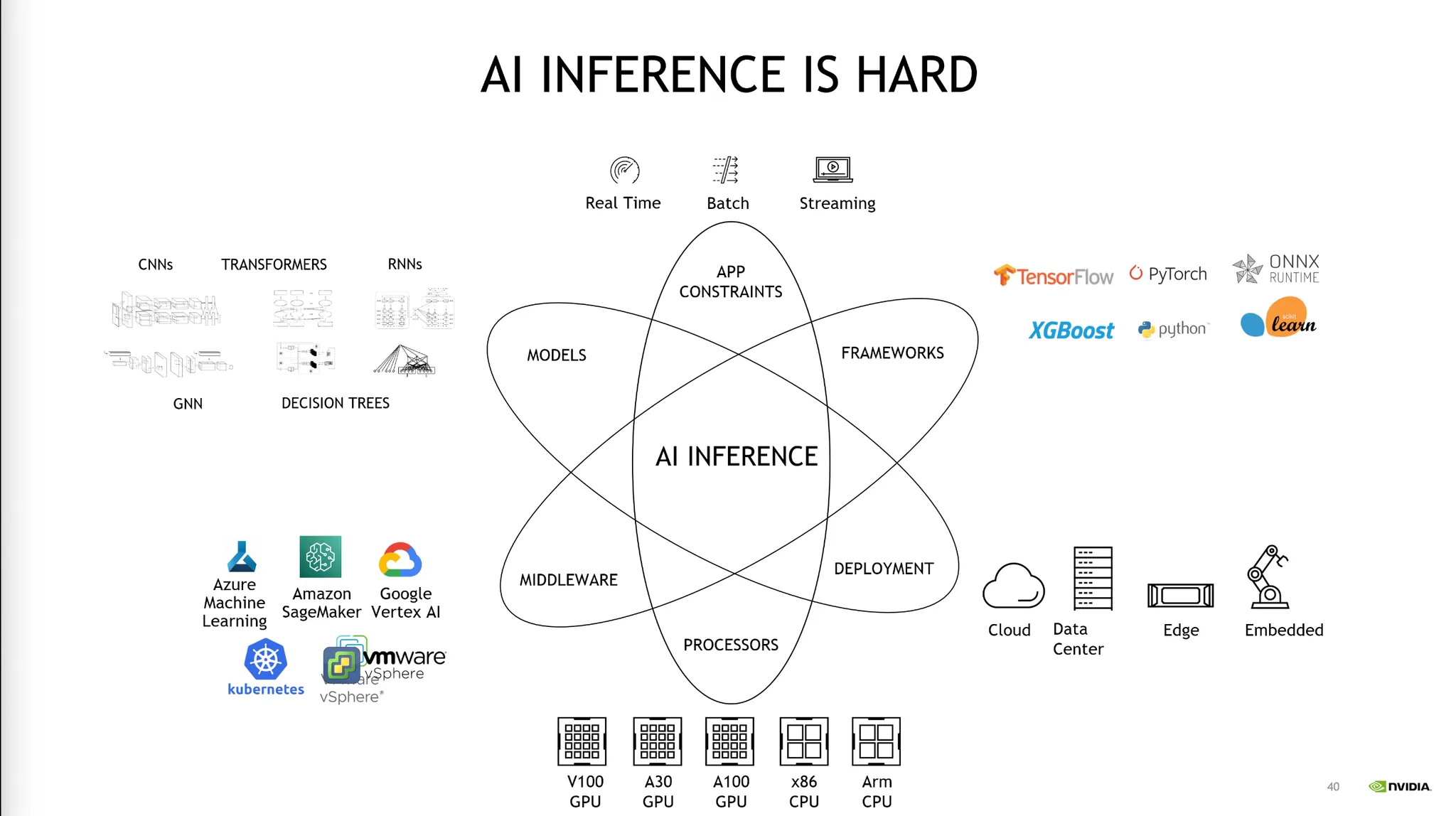
•
Inference Server는 Serving Platform이다.
•
TIS는 다양한 모델들을 서빙하는데 어려움을 해결해준다.
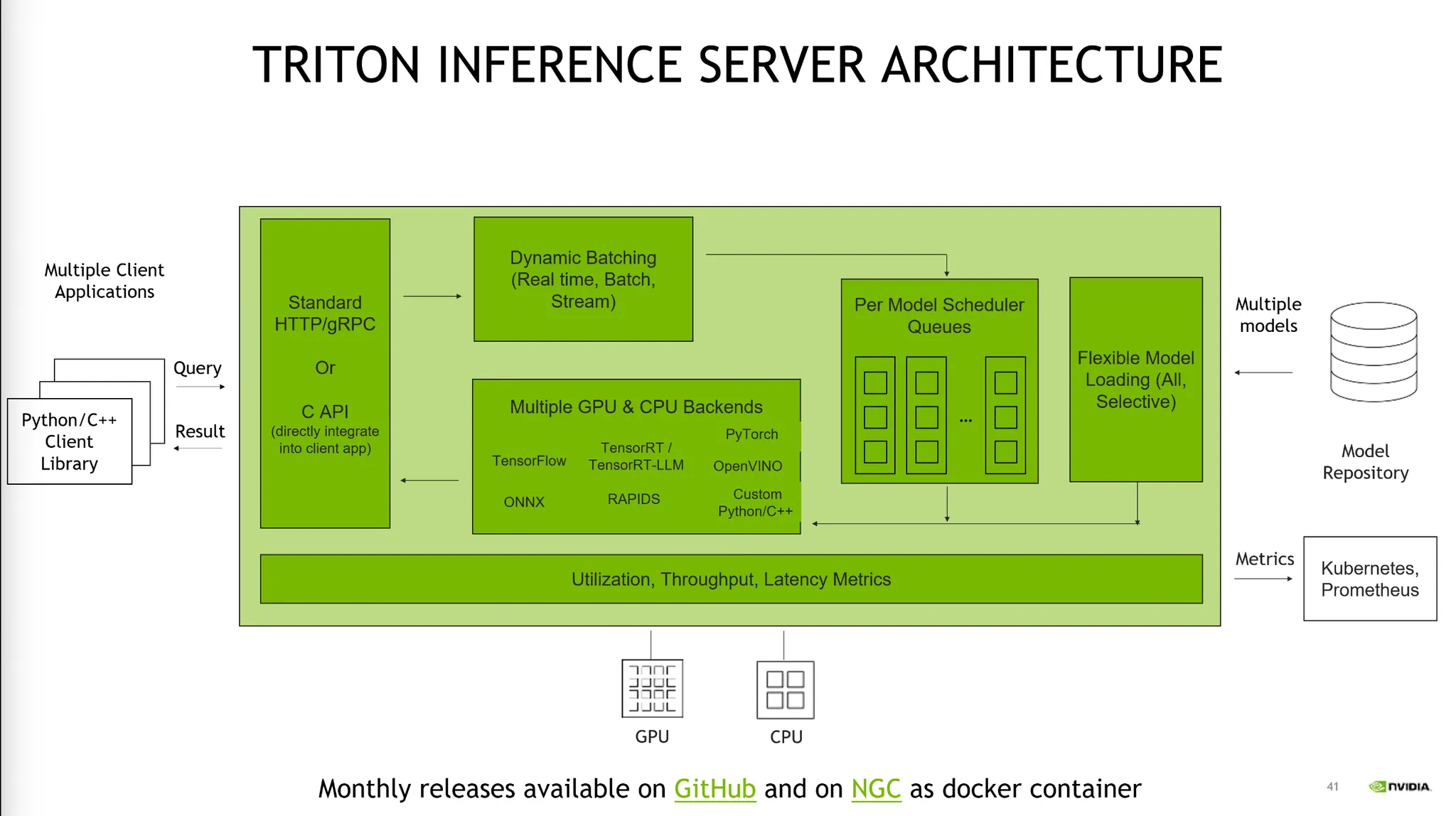
•
Client의 요청에 따라 여러 모델들을 스케줄링하여 리소스를 분배한다.
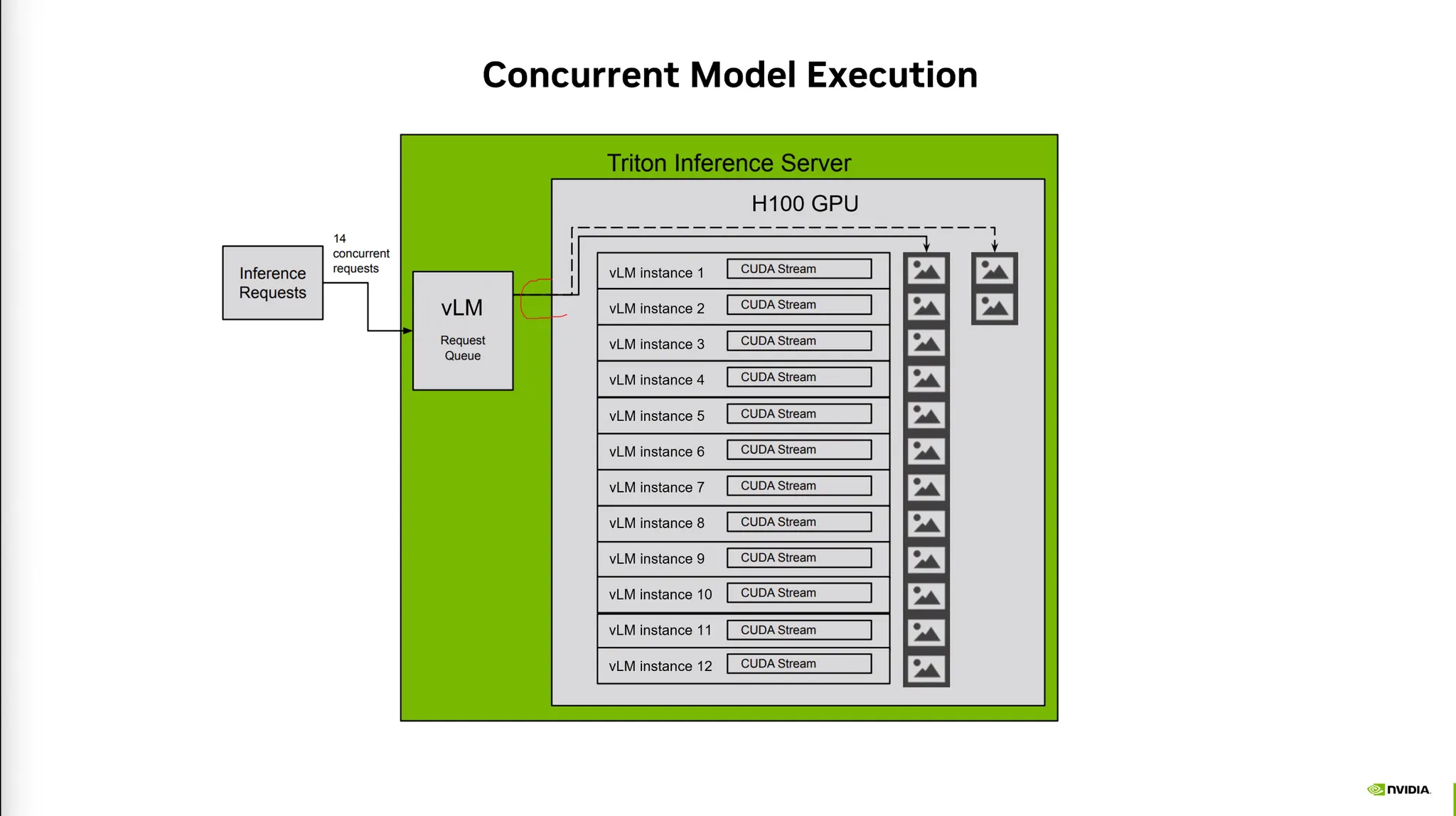
•
Vision Language Model을 multiple instance에 올려놓고 여러개의 Request를 동시에 처리한다.
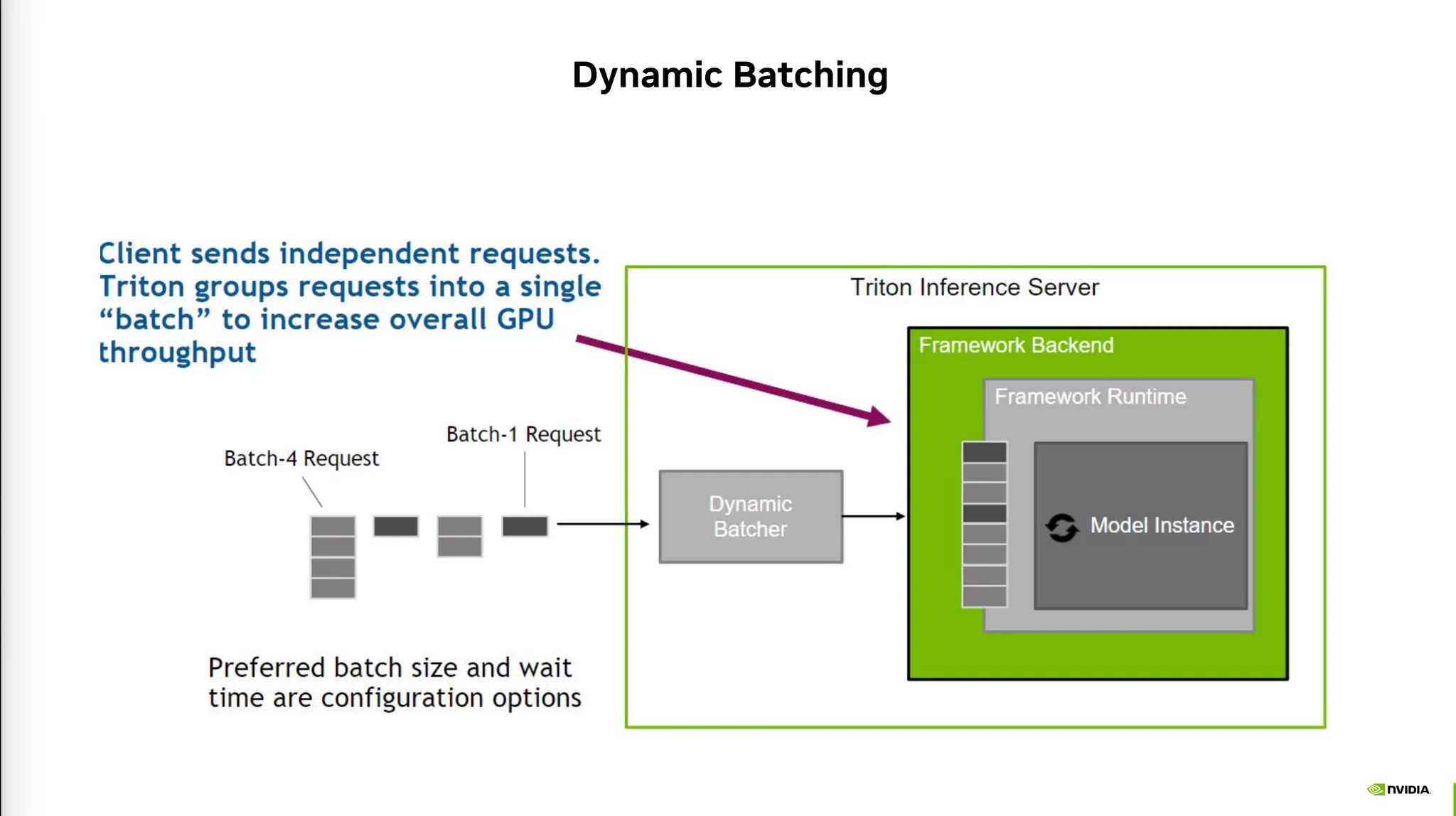
•
여러 Request가 단시간내에 왔을 때 설정된 시간 안에 Batch를 합쳐서 처리할 수 있다.
•
이런식의 동적 scheduling 작업을 수행할 수 있다.