AICA X NVIDIA Cluster GPU 교육 시리즈
2. NVIDIA AI 솔루션 소개
홍광수 박사 (솔루션 아키텍트, NVIDIA))
NVIDIA x AICA Cluster GPU 활용 캠프 (2024/08/26 - 09/05)
•
NVIDIA의 Application Framework와 솔루션을 간략하게 알아본다.
•
상위 레벨의 Library와 프레임워크를 알아본다.
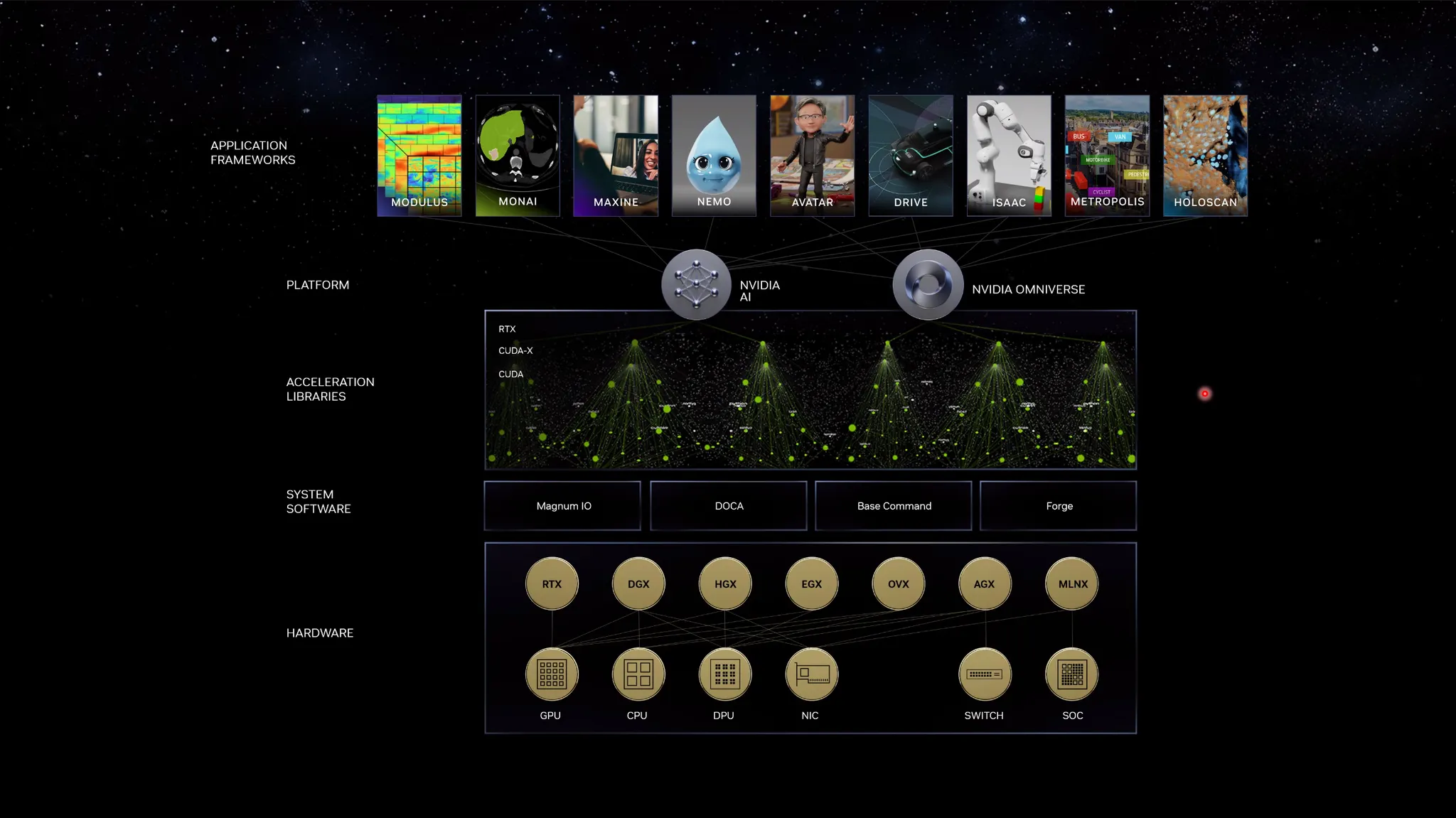
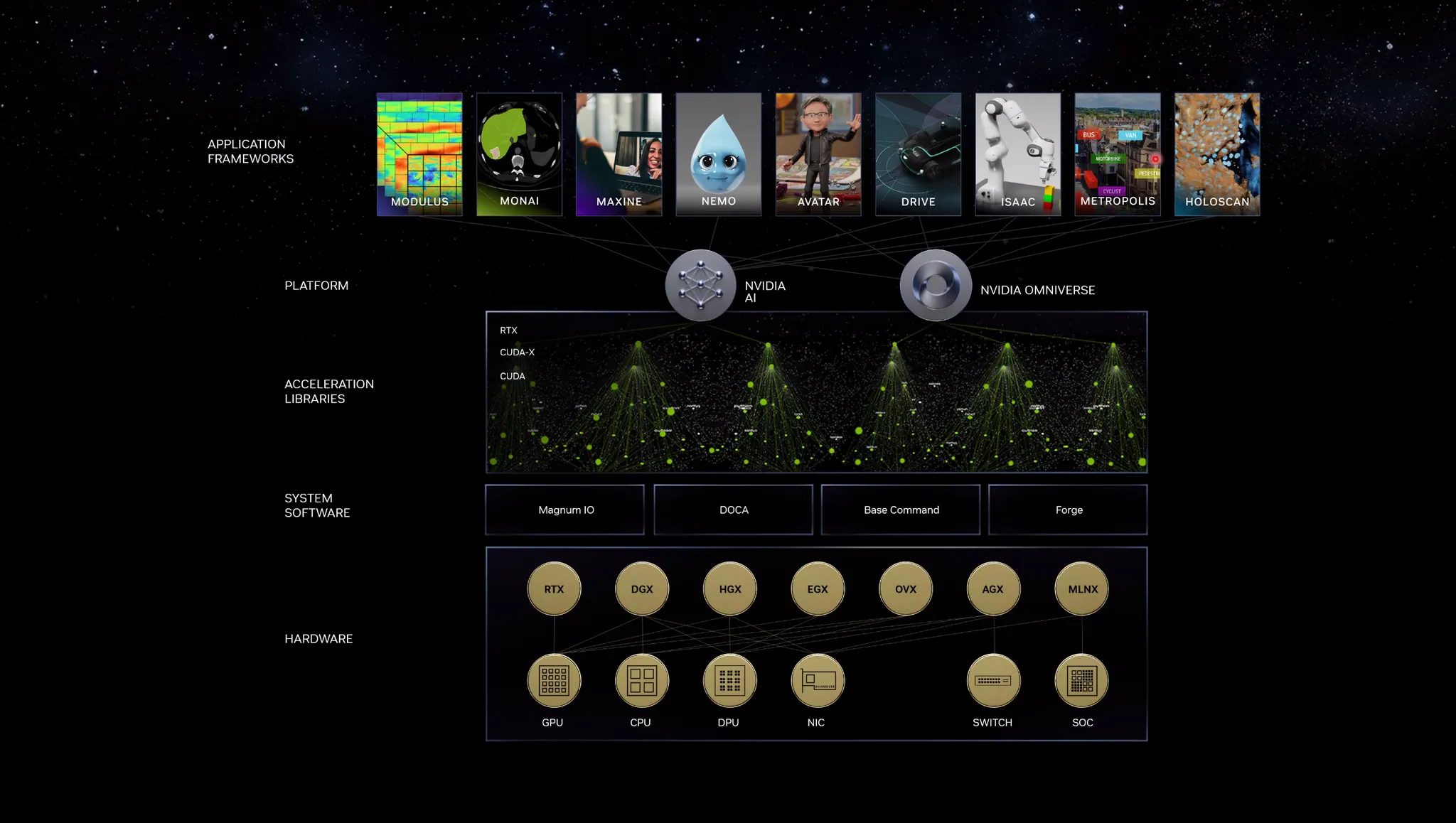
CUDA-X Library Eco System
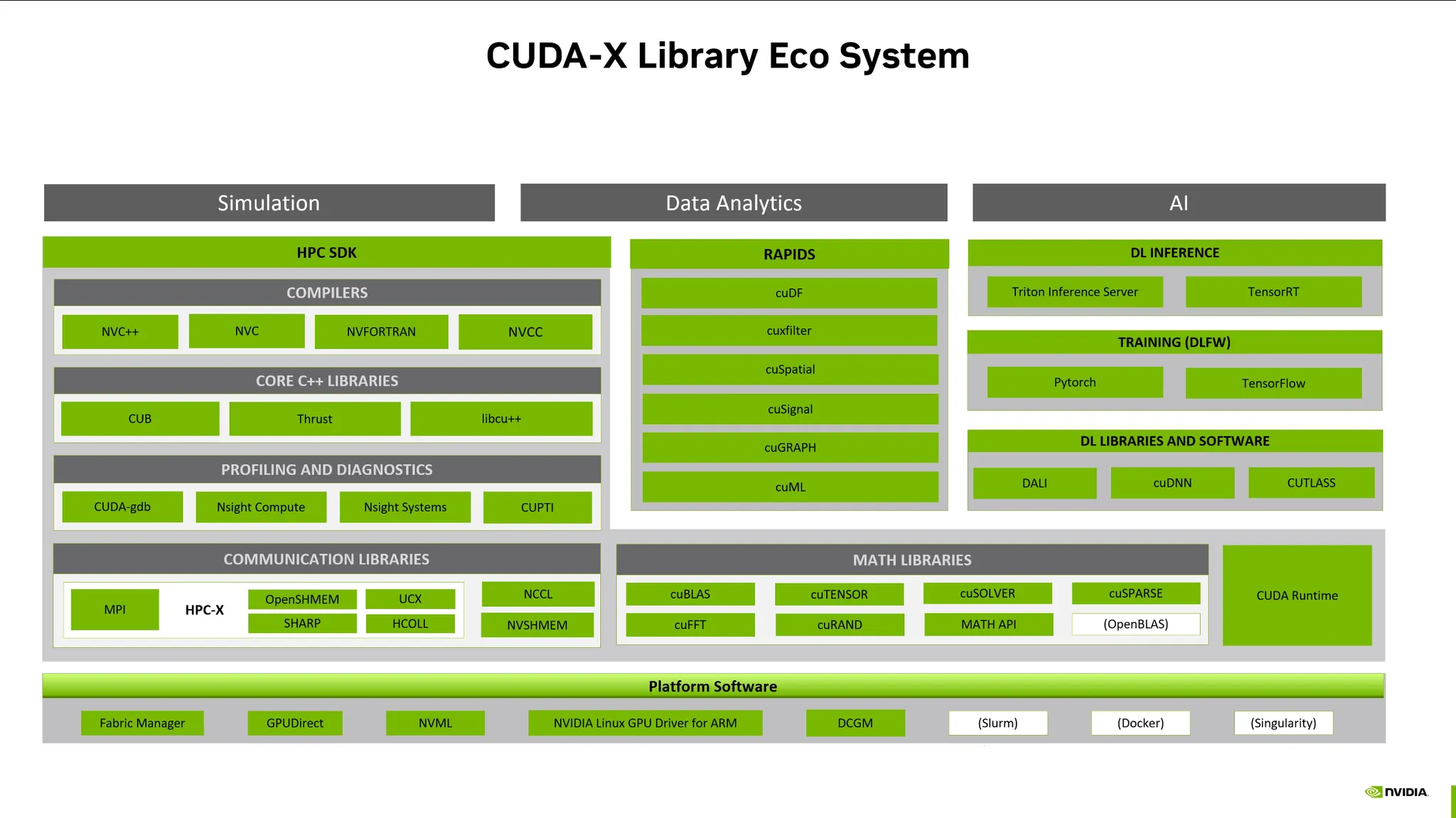
CUDA-X: GPU기반 병렬학습 라이브러리
•
하나의 어플리케이션을 만들고 구동하다보면 이상적인 에코시스템이 필요함.
•
Nvidia는 이러한 에코시스템이 잘 구축되어있음
Platform Software:
•
GPU Direct IDML
•
GPU Direct Storage: NVME로 구성된 SSD와 GPU 메모리간 데이터 전송기술 (AI, 게임)
•
NVML: NVidia Management Library (nvidia-smi)
•
DCGM: Data Center Management
Math Libaries: CUDA를 활용한 수학계산
Communication Library: Bottleneck을 줄여주는 라이브러리
•
NCCL: Deeplearning Operation 최적화
Profiling and Diagnostic: 프로파일링 라이브러리.
C++ Libraries / Compilers: 다양한 HPC-SDK가 구축되어있음
AI:
•
Pytorch, Tensorflow: cuDNN, CUTLASS를 통해서 모델연산 최적화
•
cuDNN
RAPIDS ML:
•
cuGraph
•
cuxfilter
•
Viz integration: GPU기반 시각화 라이브러리가 준비되어 있음.
기타:
•
Morpheus: 사이버보안
•
Merlin: 추천시스템, 개인화 등. embedding이 매우 커 pytorch등에서는 한계가 있는데, embedding table을 GPU 메모리상에서 가속화를 함.
Data Analysis

•
기존의 CPU기반 데이터 분석 라이브러리를 GPU가속화 하도록 지원함.
◦
CPU기반 라이브러리: Pandas, scikitlearn, Apache Spark 등
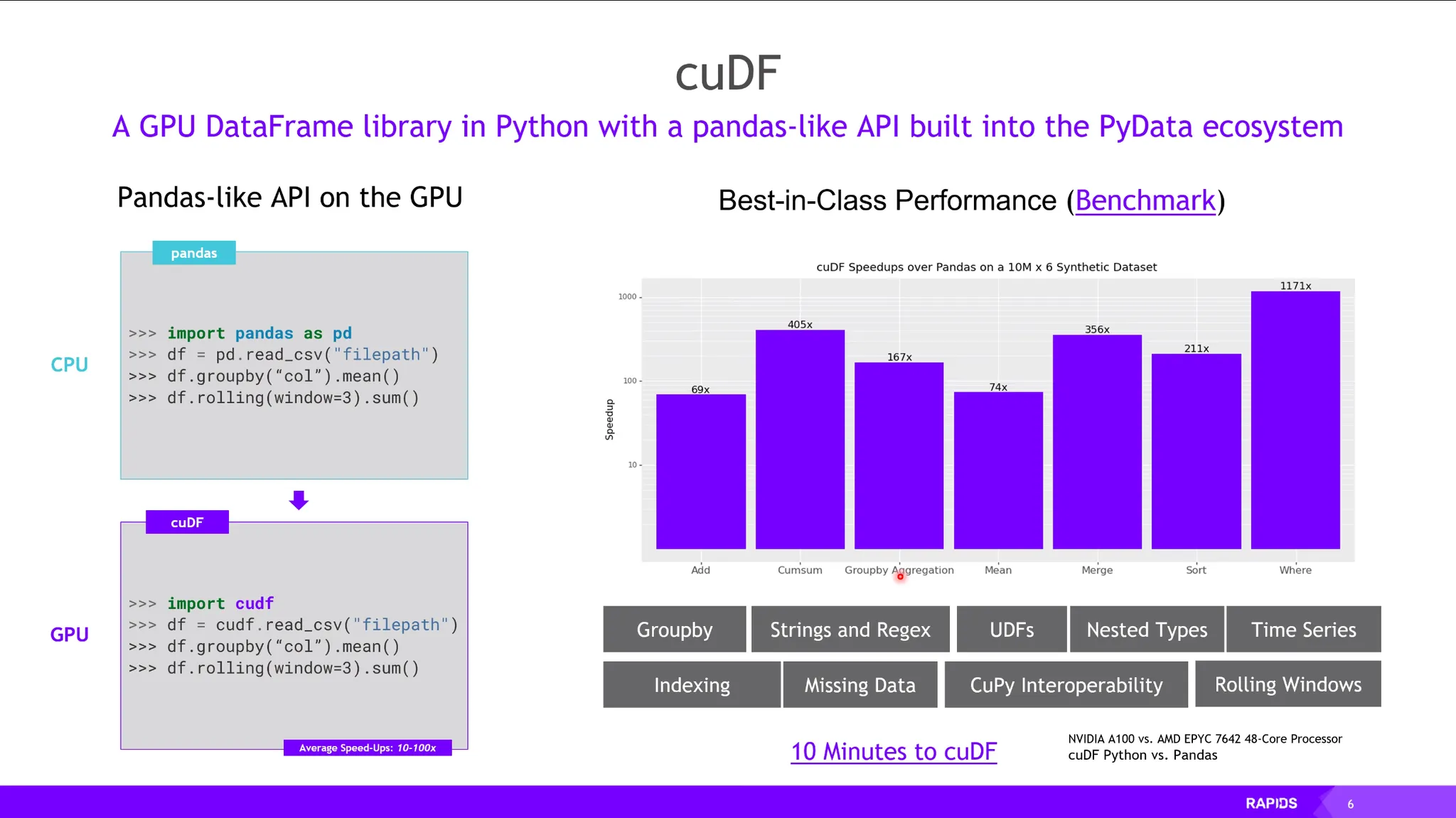
cuDF: DataFrame.
•
Pandas를 GPU기반으로 가속하는 라이브러리. (69x ~ 1171x)
•
Pandas와 똑같은 인터페이스를 제공하여 쉬운 migration 가능.
•
데이터 io 역시 GPU Direct Storage 기술을 활용하여 사용함.
•
라이브러리를 호출하는 것만으로도 하드웨어 가속에 관련된 기술들이 잘 준비되어 있음.

cuML:
•
sklearn을 GPU 가속화한 라이브러리. (48x ~ 9328x)

XGBoost:
•
한줄의 코드 세팅만으로 GPU기반 가속 및 병렬처리 가능.

RAFT: 그래프 기반 ANN 가속화 라이브러리.
•
ANN (Approximate Nearest Neighborhood): Similarity Search.
•
데이터베이스에서 구축된 데이터를 이용해서 LMM을 학습함.
•
쿼리를 요청한 Data에 대해 Retrieval 작업을 할 때 사용.
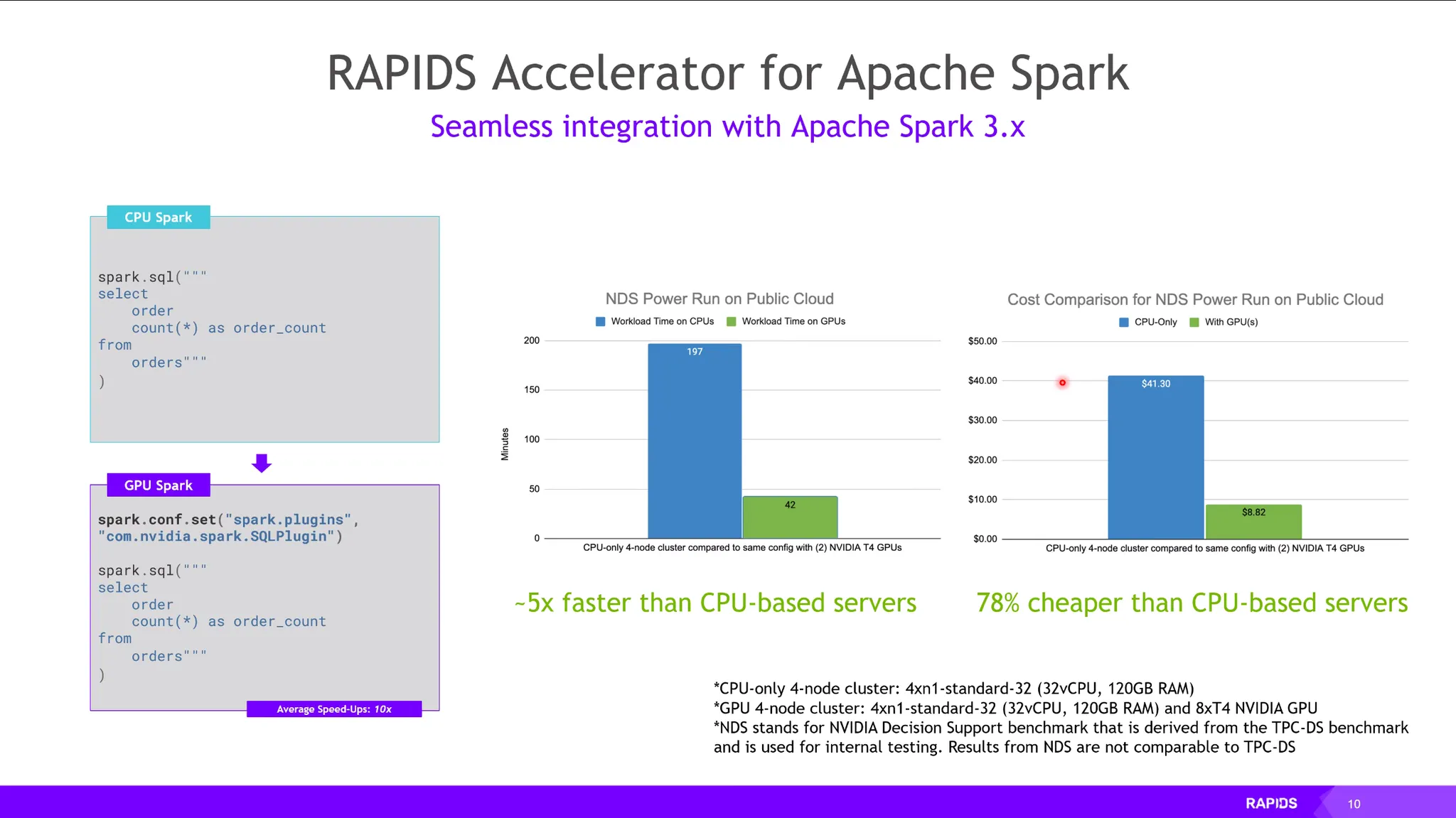
RAPIDS for Apache Sparks:
•
데이터 분석 가속화.
•
한줄의 코드 세팅만으로 GPU기반 가속 가능.
•
이때, Sequential하게 처리해야하는 Logic들은 CPU에 할당하고 병렬처리가 가능한 Logic은 GPU에 할당하여 병렬처리하는 Logic이 최적화되어있음.
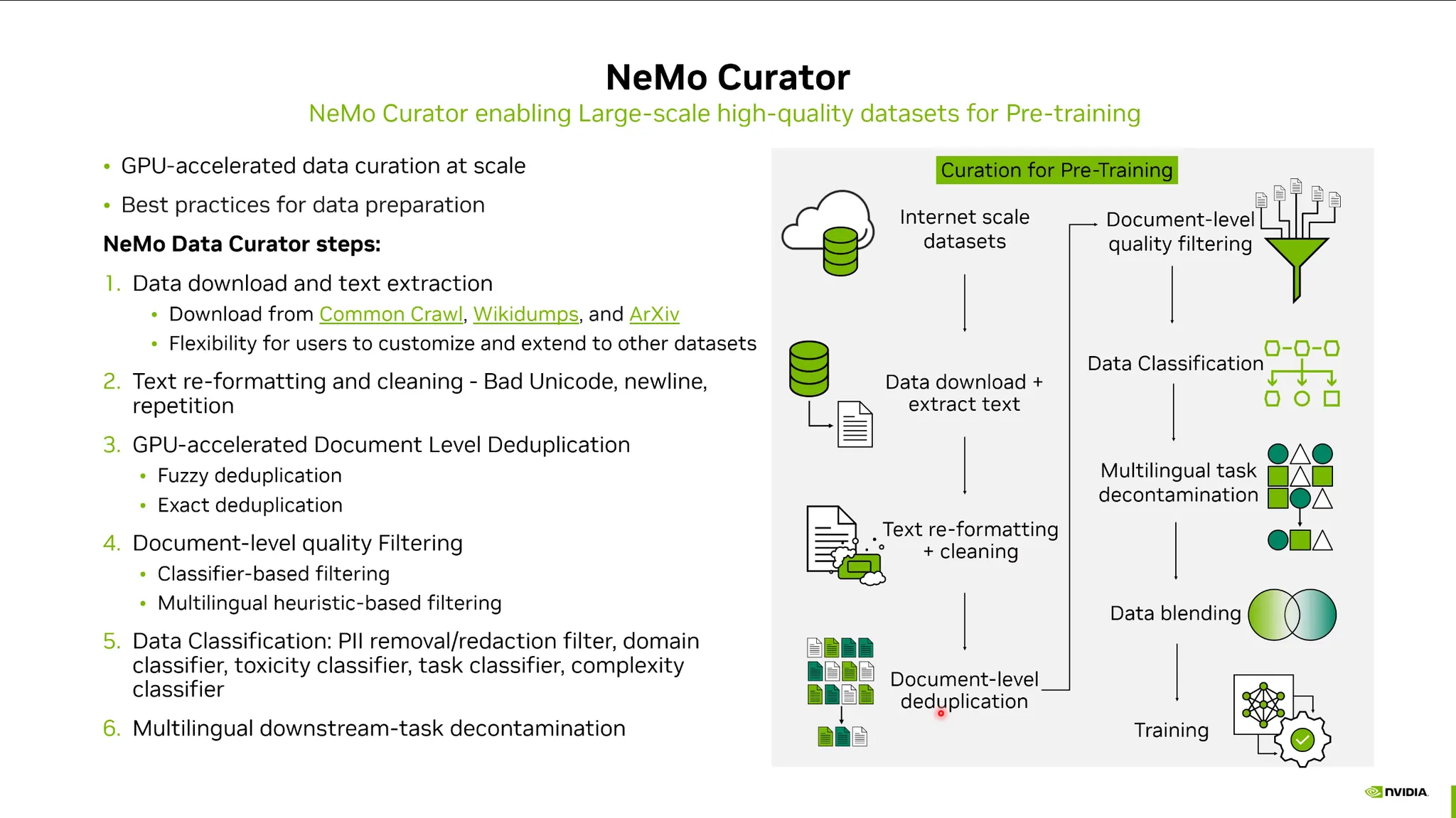
NeMo Curator:
•
GPU 가속화를 지원하는 텍스트기반 데이터 전처리 라이브러리. (LLM)
•
Data Download, Duplication Removal, Customizing, reformatting, cleaning등.
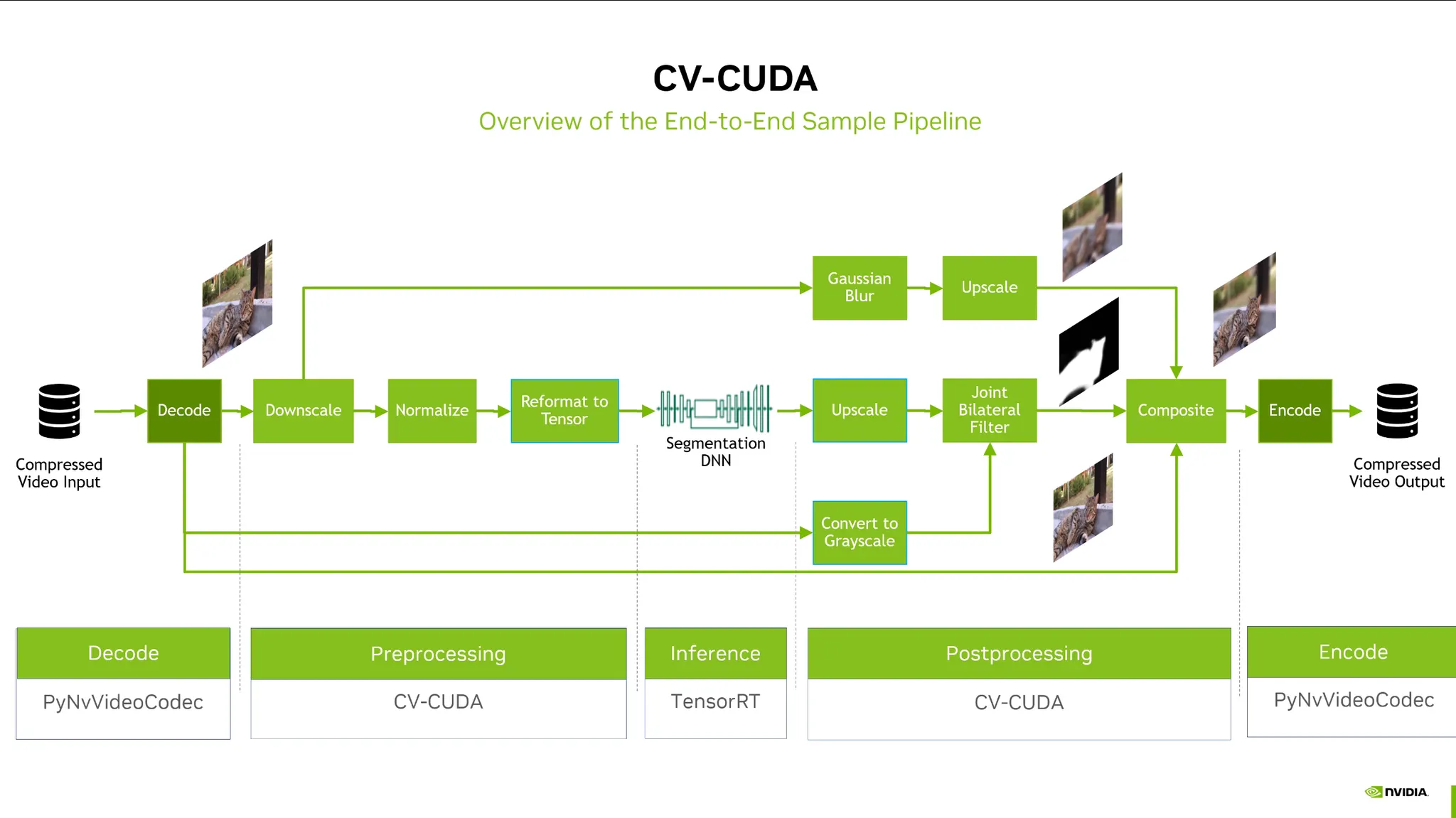
CV-CUDA:
•
Computer vision에서 전처리를 할 때 (Agumentation) GPU 가속화 지원.
•
JPEG, AVI등 하드웨어 디코더 제공
AI Training

•
RAPIDS와 general frameworks의 연동 및 가속.
•
NVIDIA는 Pytorch등에 많은 contribution을 했기때문에 GPU 가속화를 잘 지원함.
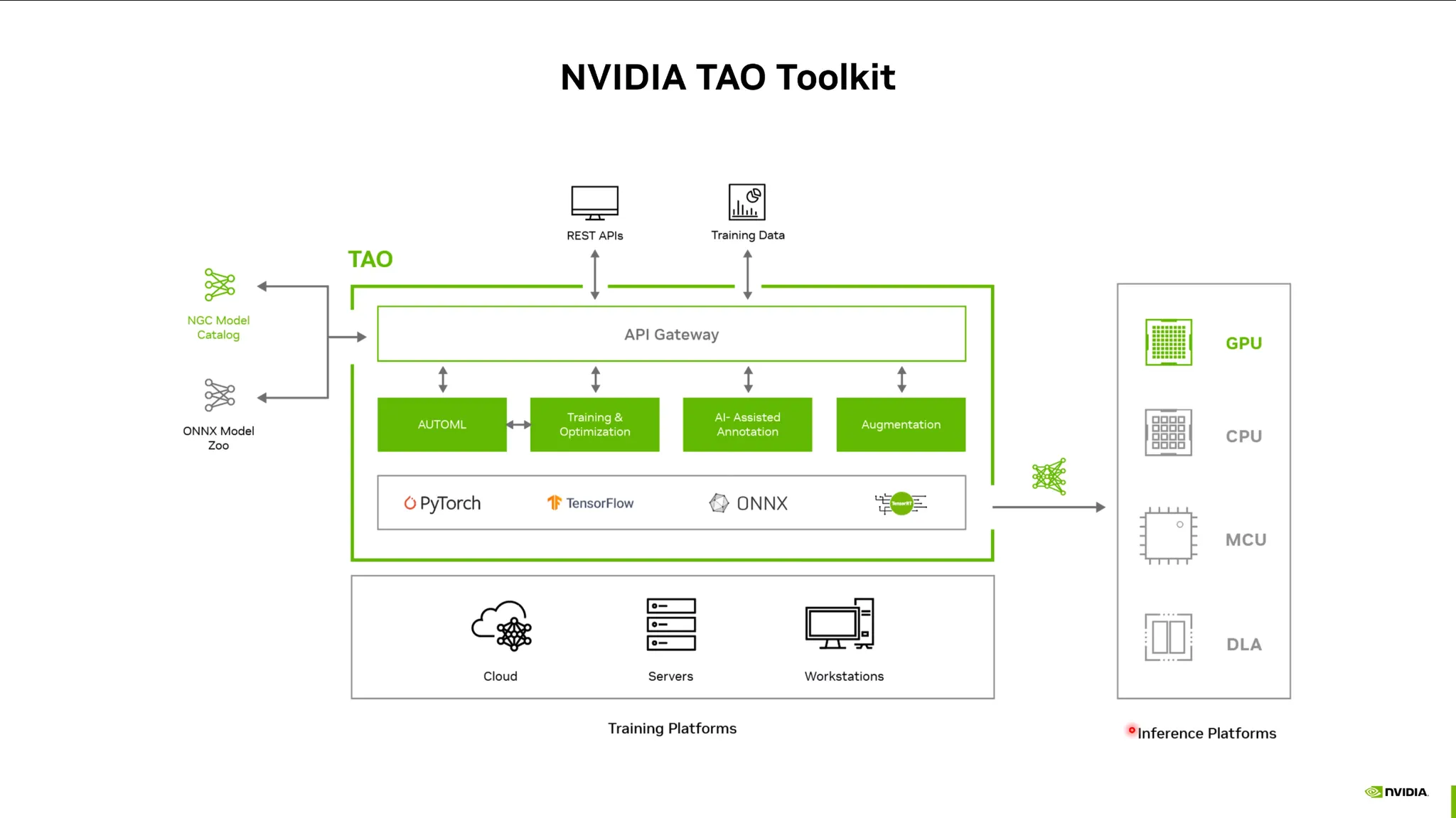
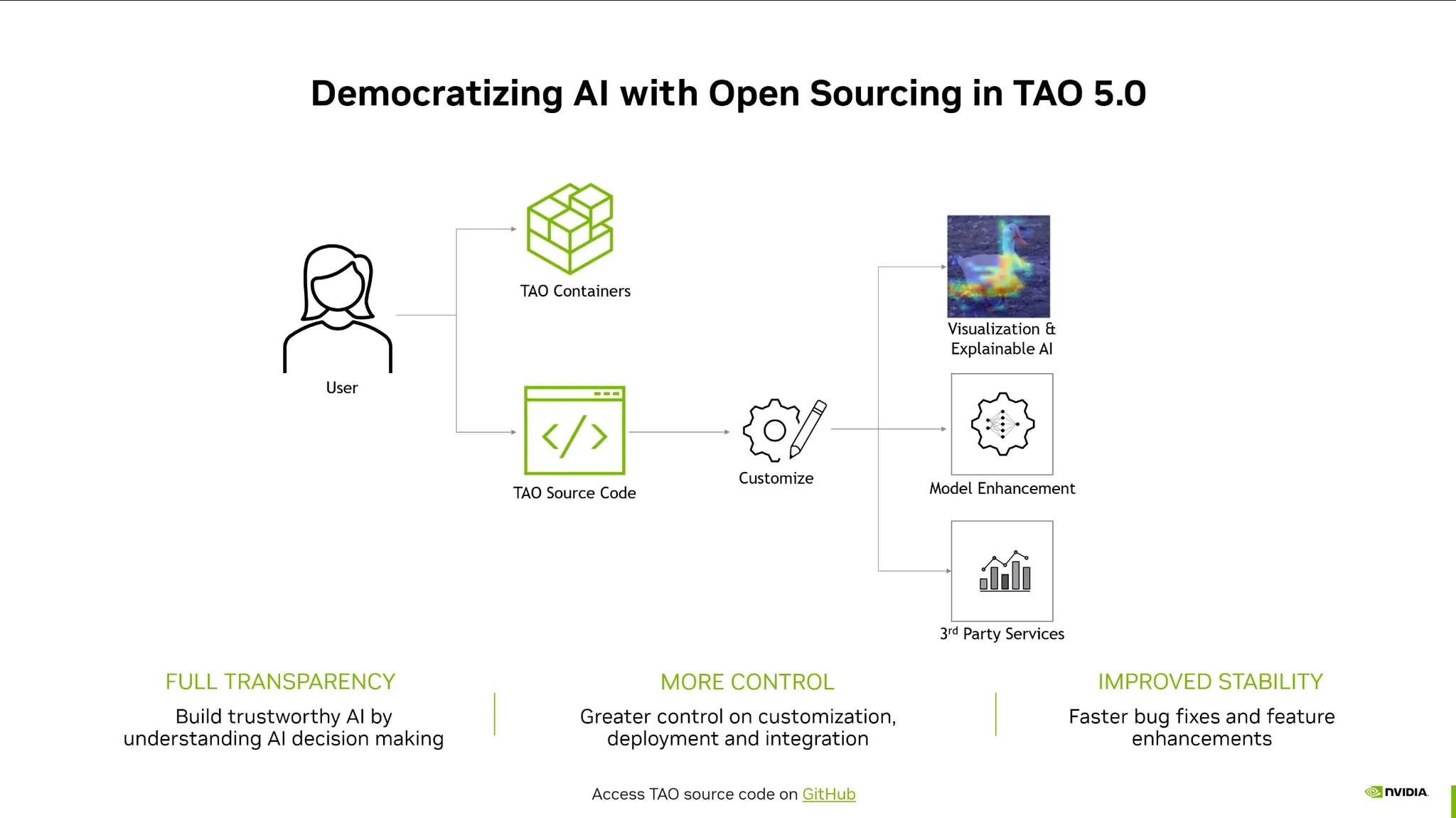

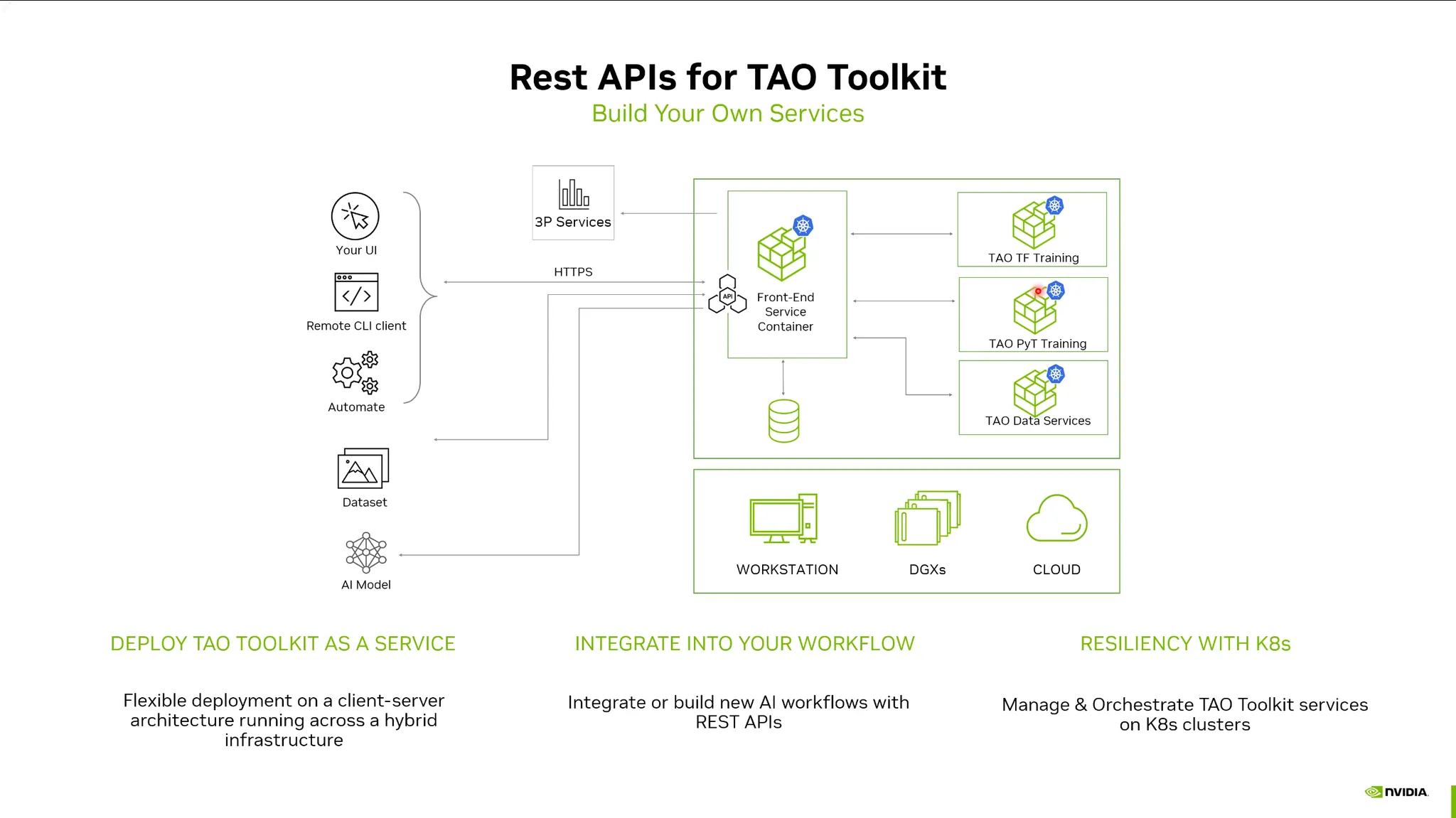
NVIDIA TAO Toolkit: (Train Adapt Optimization)
•
Pretrain모델을 fine-tuning할 때, 이를 쉽게 할 수 있는 툴킷.
•
베어메탈 뿐 아니라 컨테이너기반 REST APIs를 제공.
•
pytorch등 프레임워크의 이해가 없어도 손쉽게 finetuning 가능.
•
TAO Toolkit github에 많은 예제와 스크립트가 제공되어 있음.
Inference
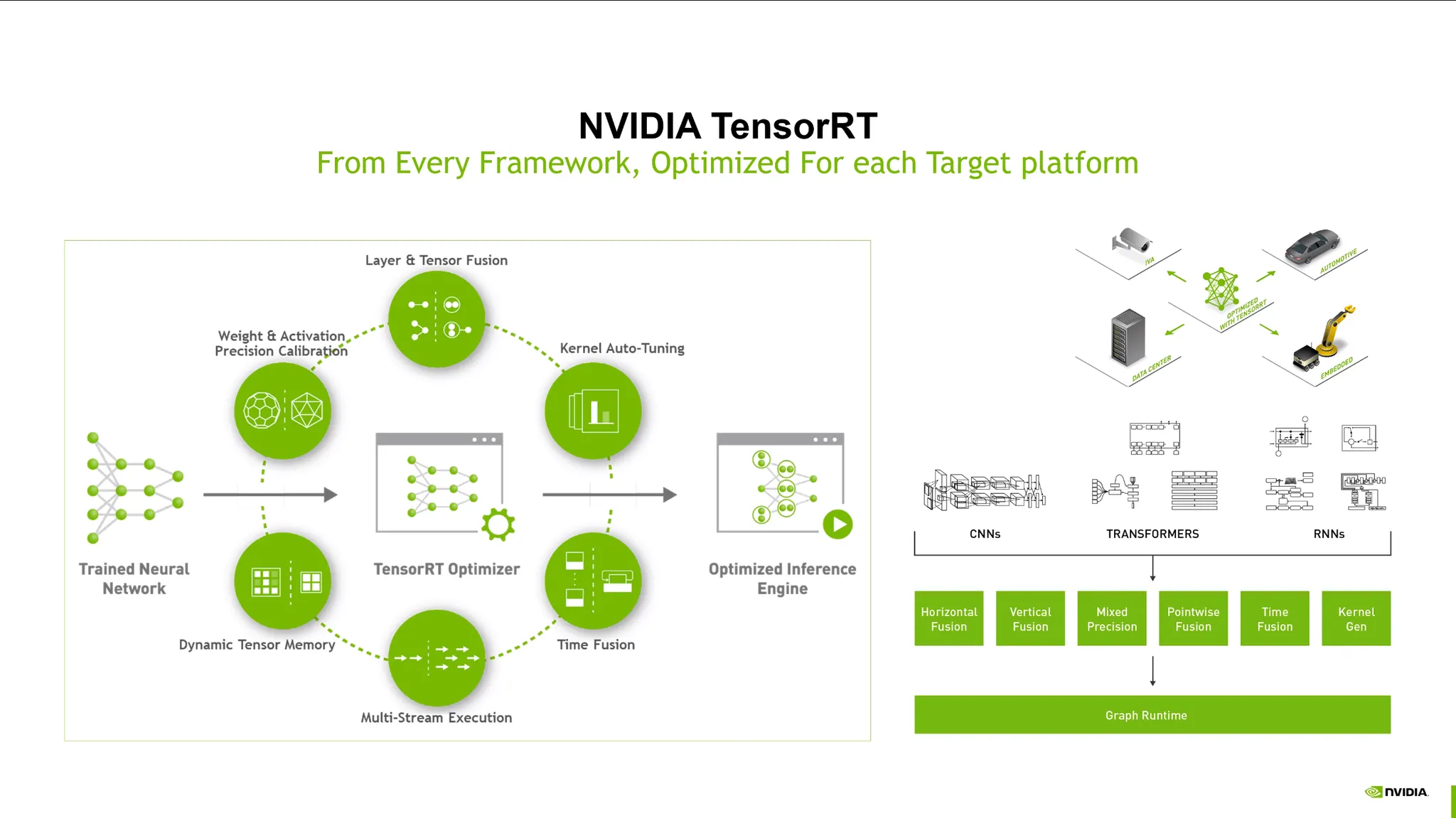
TensorRT:
•
학습된 모델을 deploy할 때 다양한 target hardware 플랫폼에 최적화된 모델 엔진을 만드는 플랫폼.
•
이를 쉽게 도와주는 라이브러리. 레이어 및 텐서 퓨전, precision 최적화 등.

TensorRT-LLM:
•
TensorRT + LLM에 특화된 기능들. (KV Cashe 최적화 등)
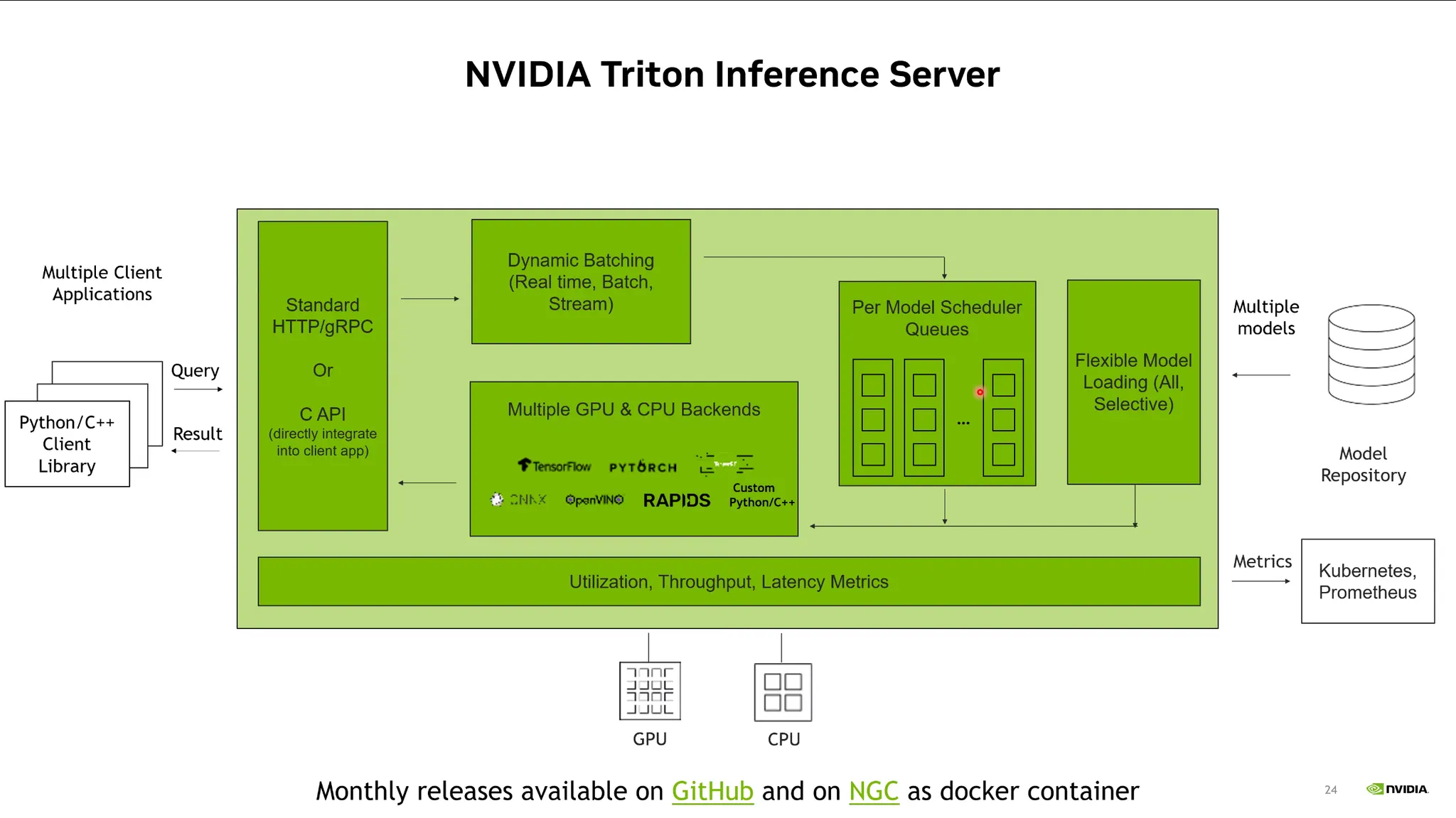
TensorRT Inference Server:
•
서버 안의 다양한 로직들과 모델들을 구축해놓고 최적화된 파이프라인 구축을 도와주는 라이브러리.
•
클라이언트에서 query를 HTTP등으로 날려주면, 스케줄러를 통해 적절한 GPU 프로세스에 request를 날리고 응답을 받아줌. 또한 다양한 GPU & CPU Backend를 지원함.
•
이를 통해 효율적인 Model Inference가 가능함.
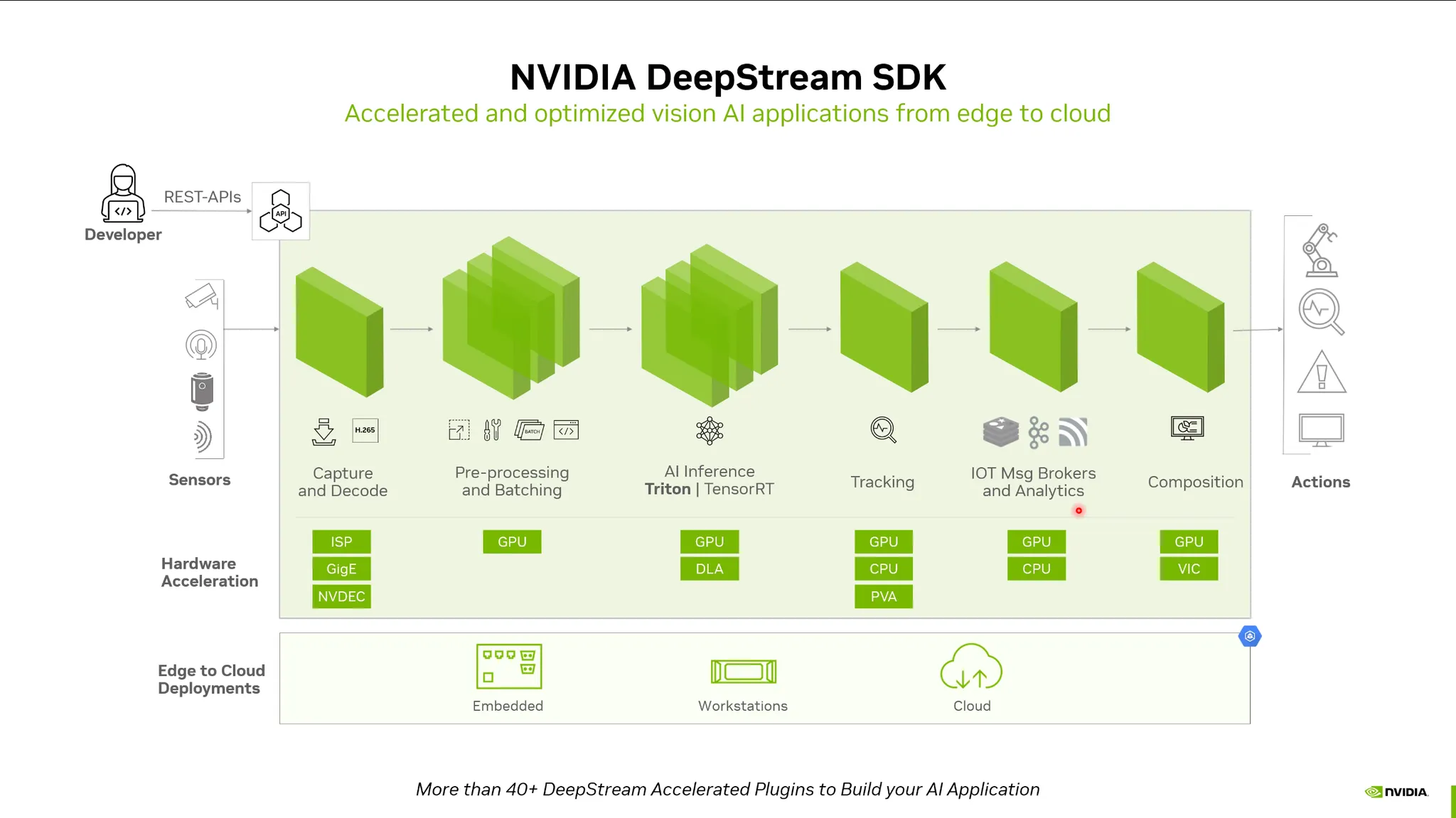
DeepStream SDK:
•
비디오처리를 위한 프레임워크.
•
네트워크 data stream을 받아 하드웨어 디코딩, GPU 메모리 할당, Inference 등을 손쉽게 구축.
Omniverse Platform
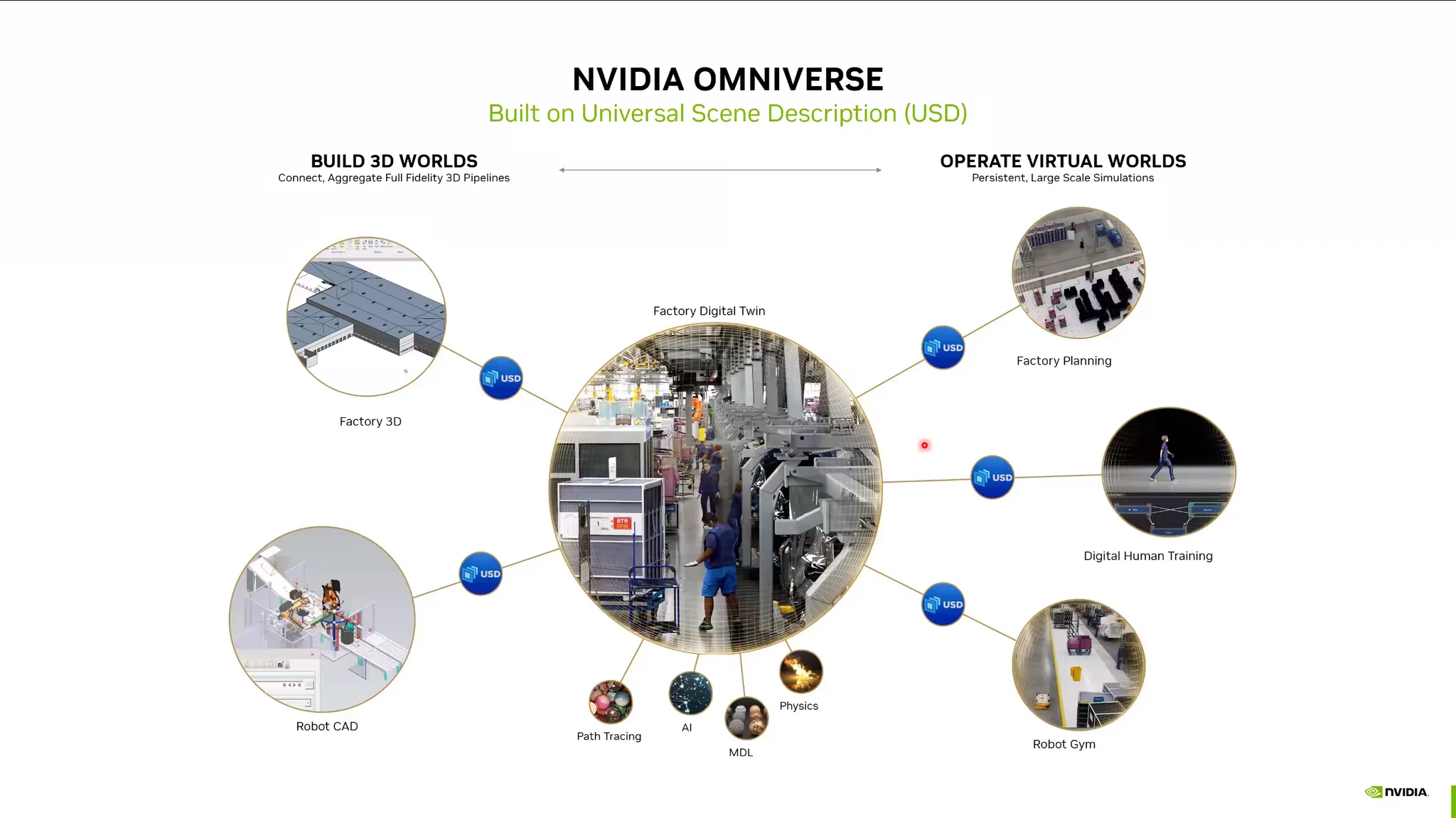
•
가상 공간 + AI (Digital Twin / Digital Human) 플랫폼.
•
가상의 공간을 만들고 피드백으로 다시 수정하는 일련의 과정에서 Bottleneck이 걸림.
•
이를 USD (Universal Scene Description) 포멧으로 통합하여 3D 로직을 처리할 수 있음.
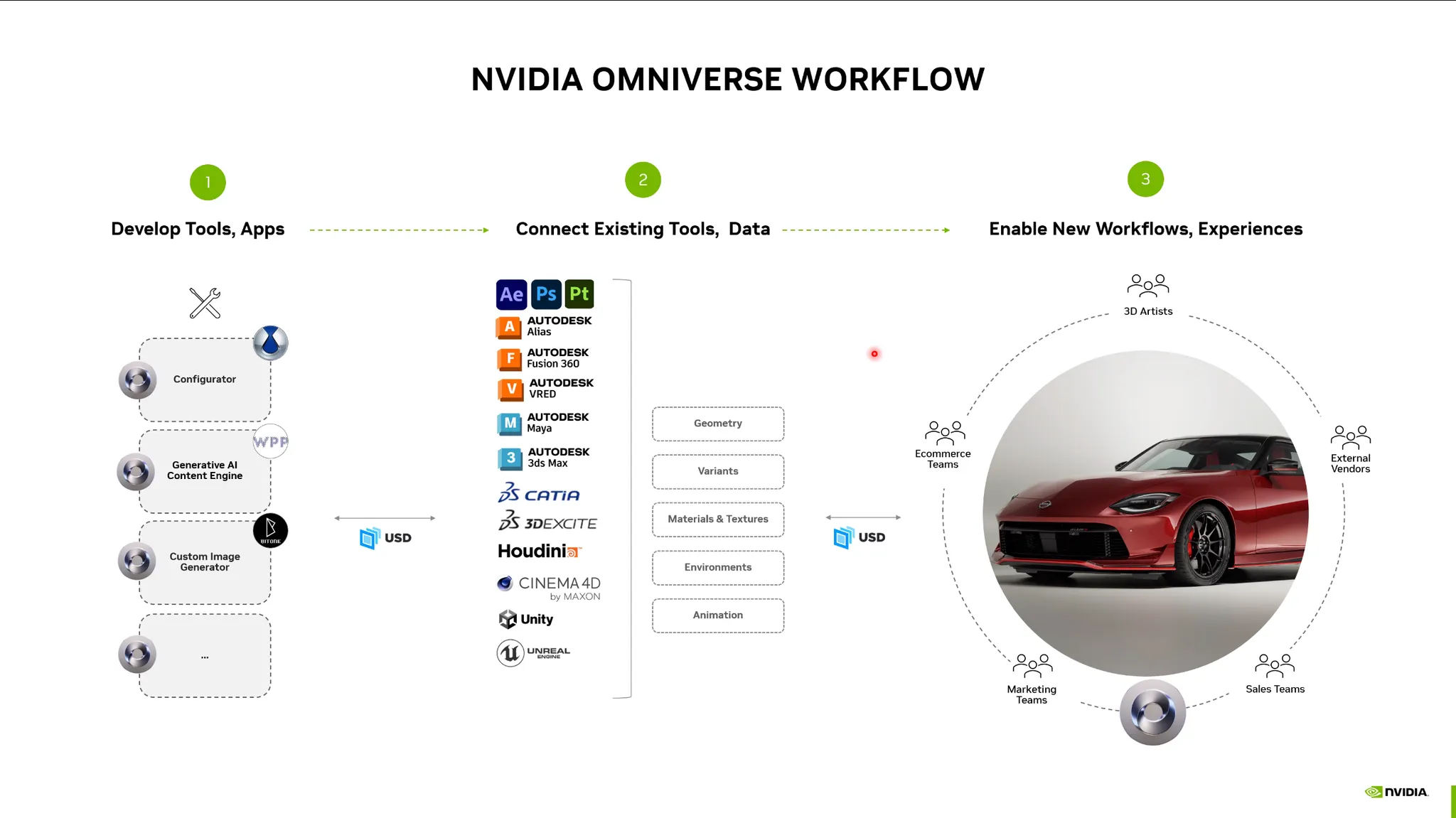
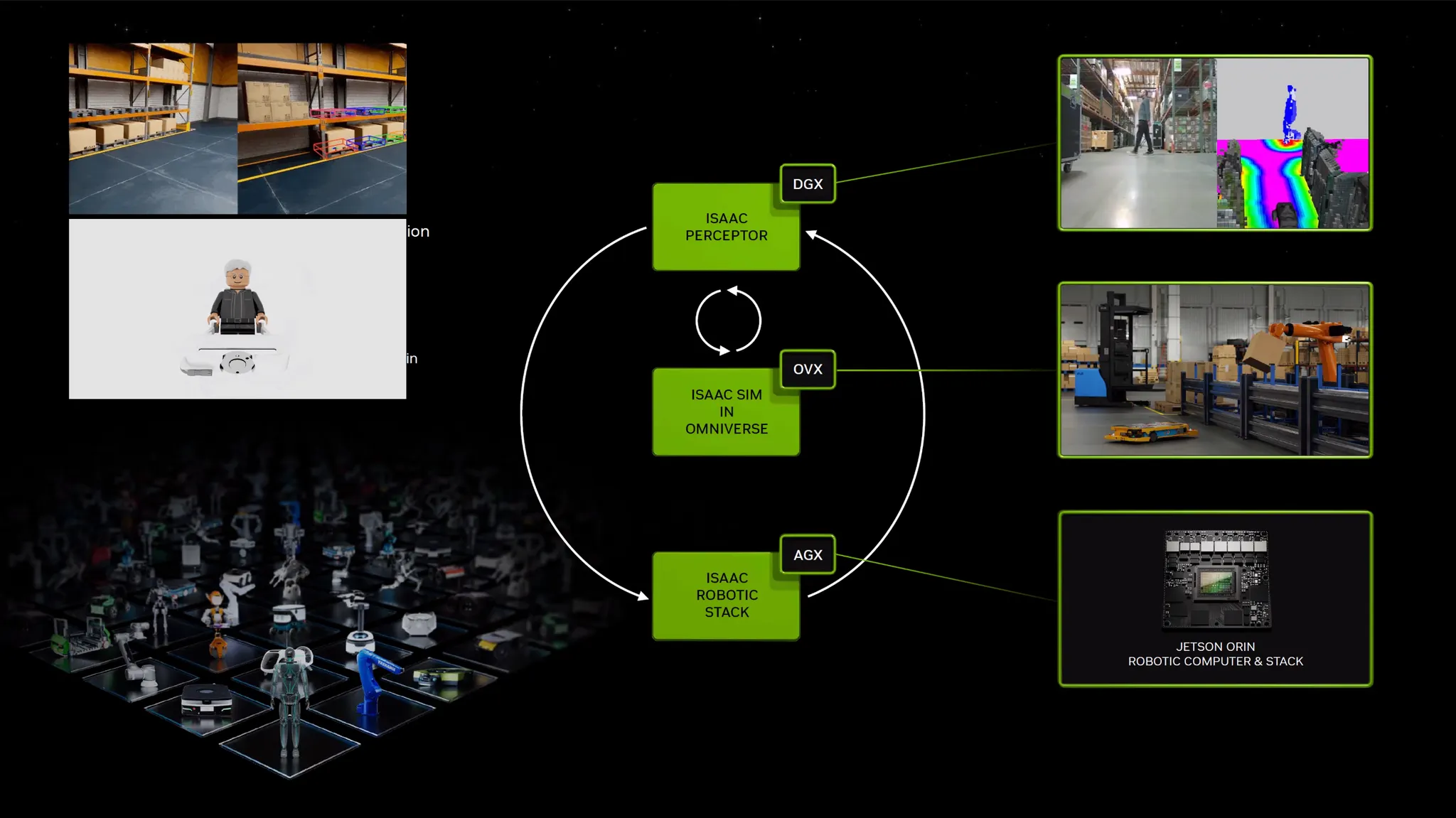
•
가상공간을 옴니버스로 시뮬레이션하고 AI 모델을 시뮬레이션 할 수 있음. (로보틱스, 자율주행)
Application Framework
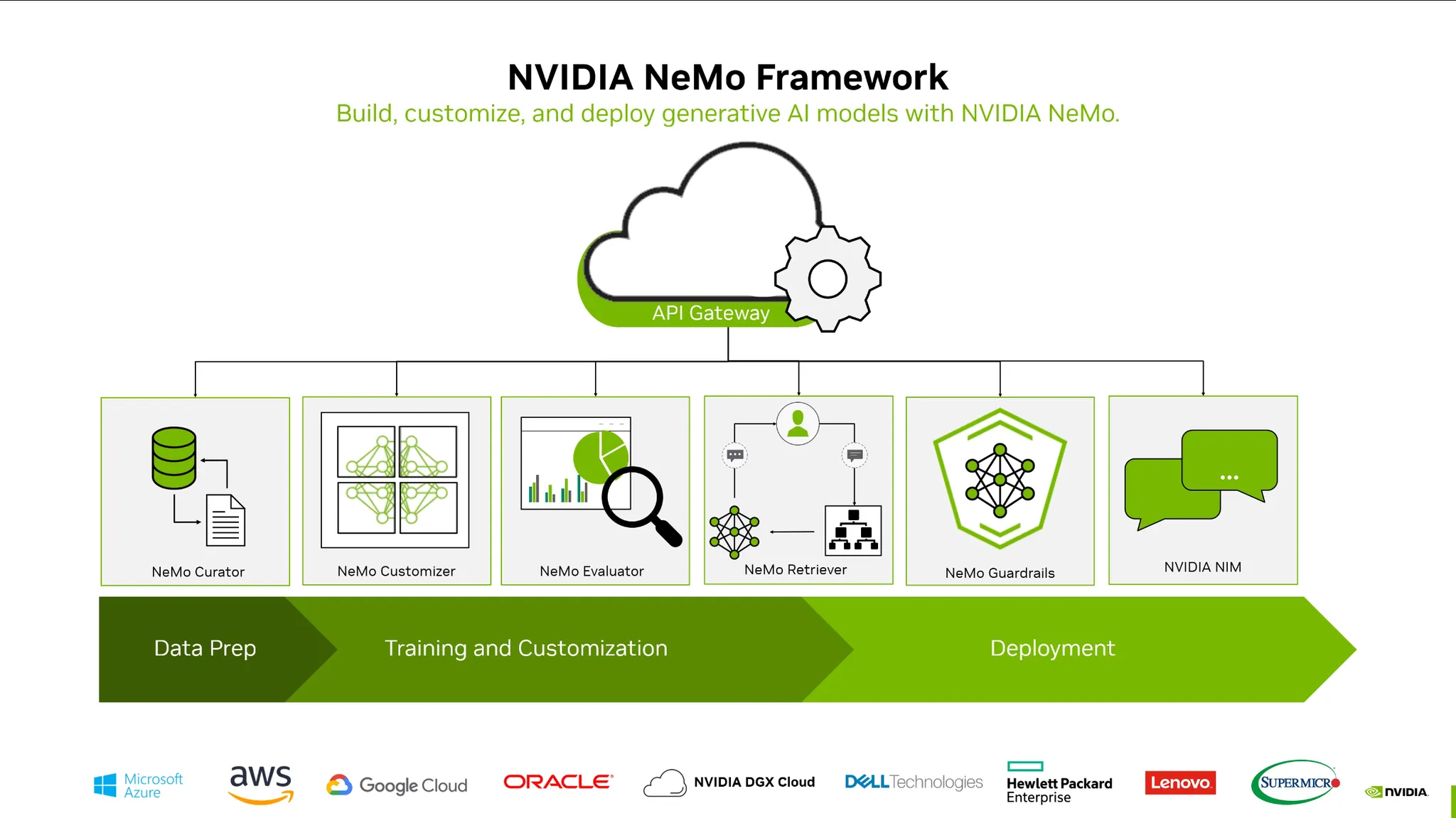
NeMo Framework:
•
Data 준비부터 학습, 디플로이까지 통합하는 프레임워크
•
비전 및 멀티모달 분야에 적용.
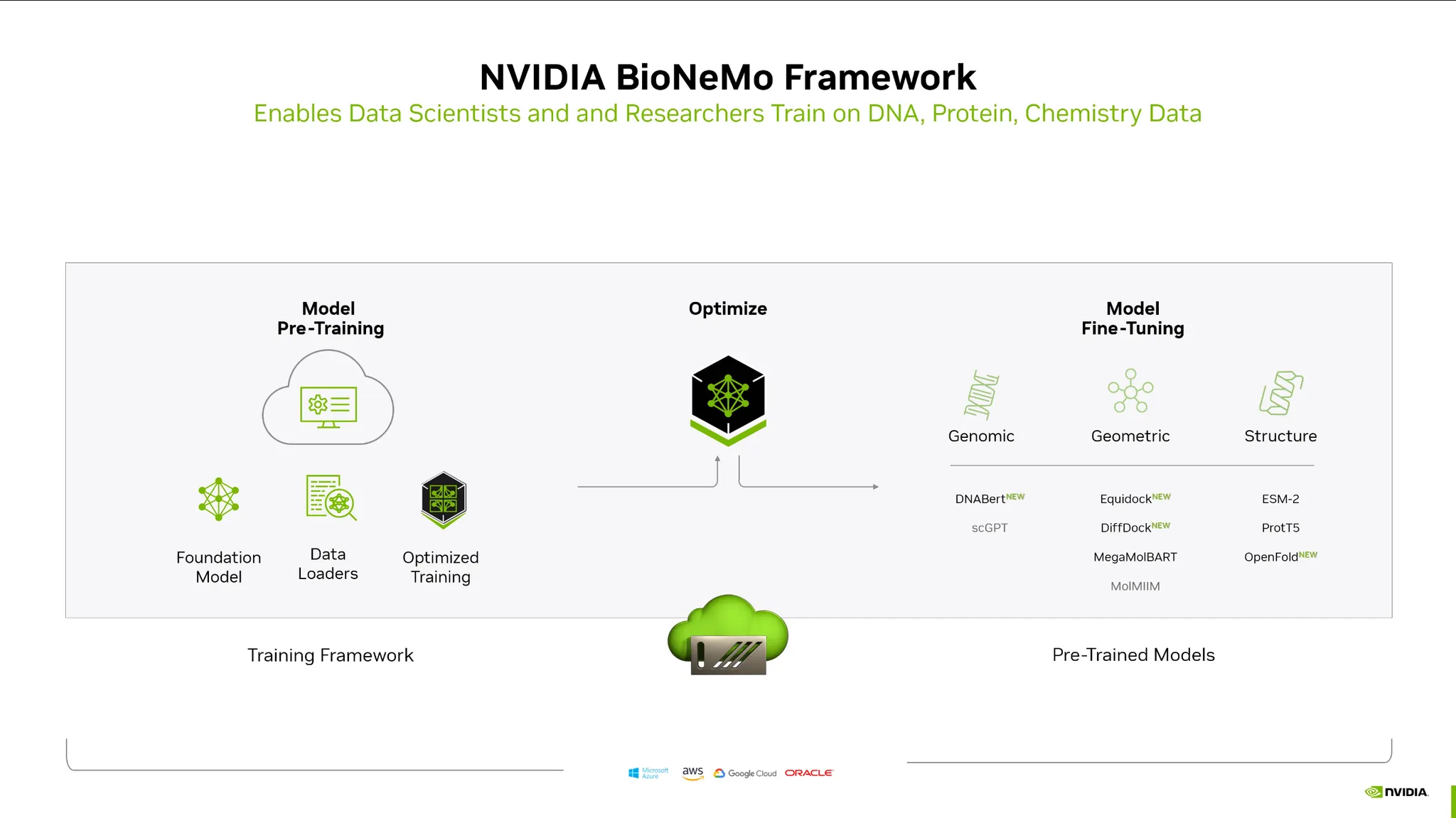
BioNeMo Framework:
•
Bio쪽에 최적화된 프레임워크
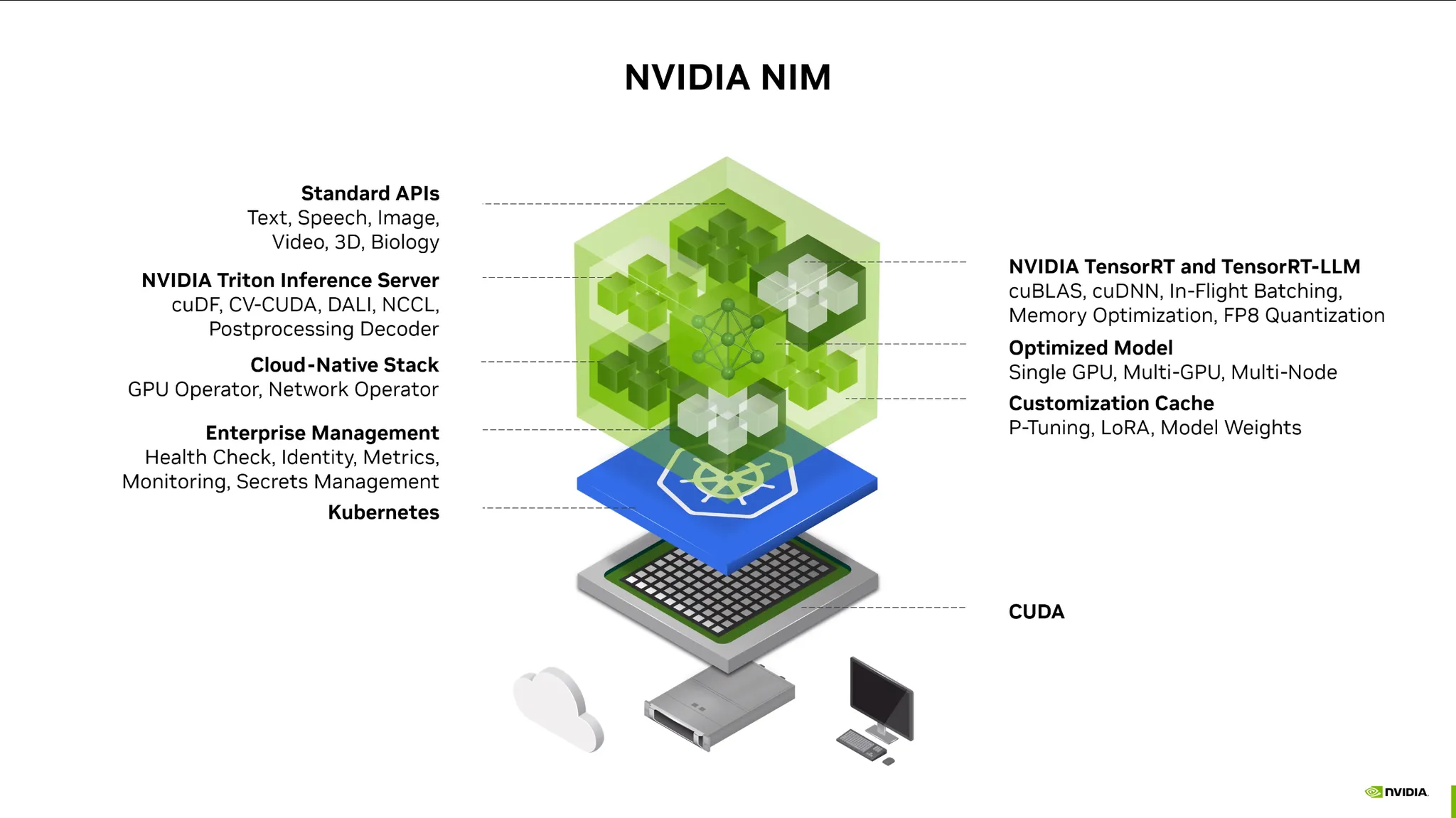


•
다양한 오픈소스와 라이브러리를 컨테이너화시킨 라이브러리.
•
엔드포인트만 노출이 되어있어서 API를 호출하는 것처럼 사용할 수 있음.
•
컨테이너를 실행시키면 하드웨어에 맞게끔 모델과 라이브러리를 다운받아 최적화를 시킴.
•
NIM for LLM등 다양한 도메인에 걸쳐서 NIM을 제공하고 있음.