


AICA X NVIDIA Cluster GPU 교육 시리즈
1. NVIDIA GPU 및 데이터센터 플랫폼 소개
홍광수 박사 (솔루션 아키텍트, NVIDIA))
NVIDIA x AICA Cluster GPU 활용 캠프 (2024/08/26 - 09/05)
•
NVIDIA GPU 기술의 동향과 발전과정 및 소구점을 알아본다.
•
NVIDIA GPU 가속 솔루션의 요점을 파악한다.
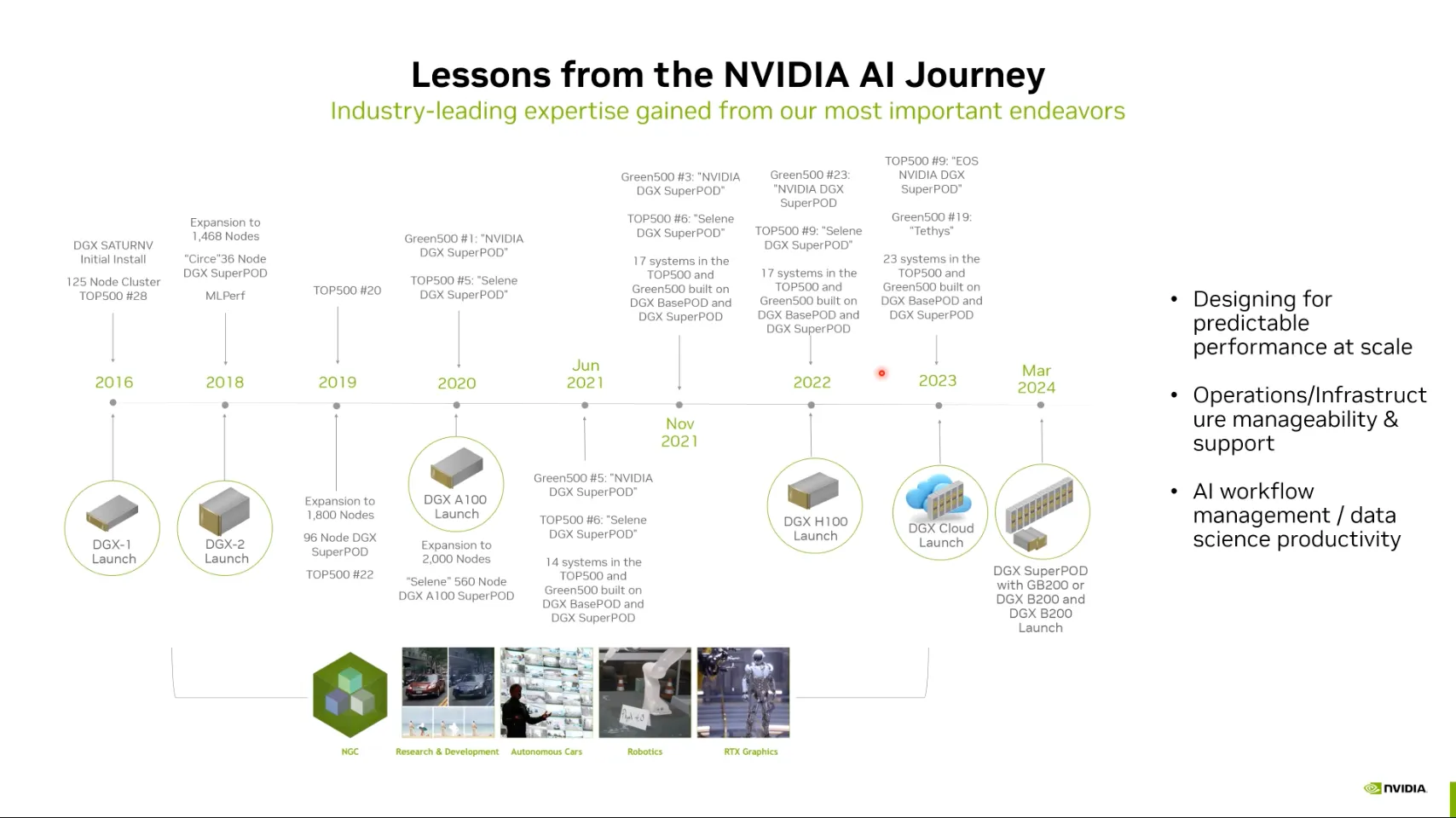
NVIDIA GPU 기술 동향
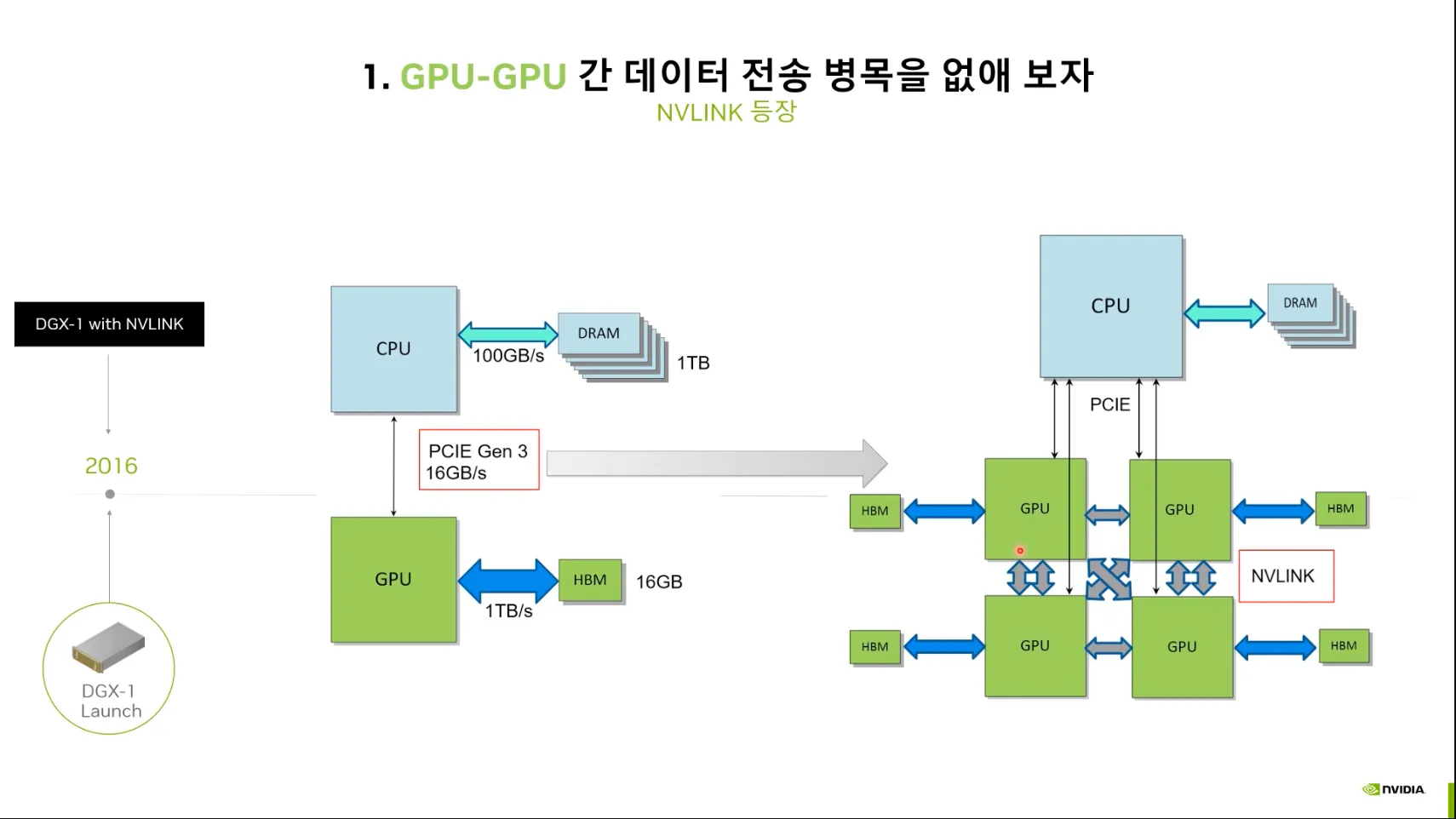
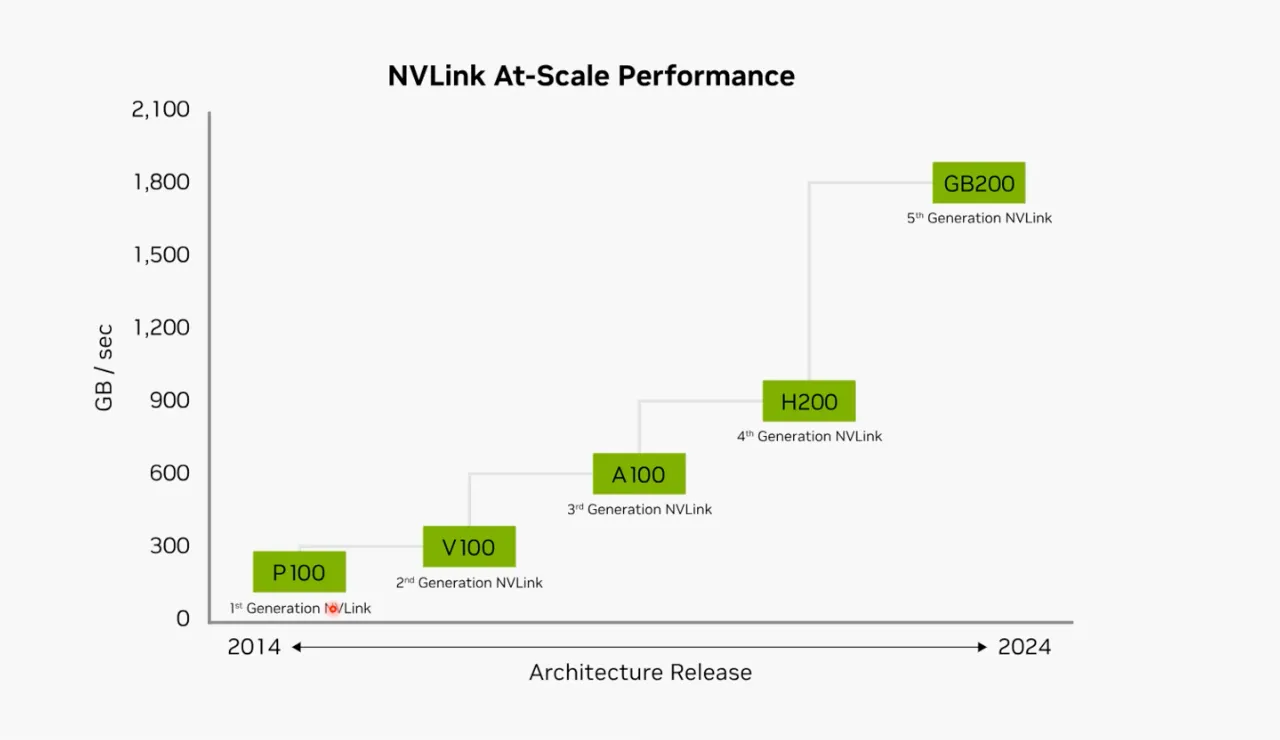
2016 GPU간 데이터 전송 병목 개선
•
NVLink의 등장 - DGX-1
•
PCIE 16GB/s 보다 더 빠른 전송을 위해 NVLINK 도입.
•
그 결과, Bandwidth를 2배씩 향상시키는데 성공함.
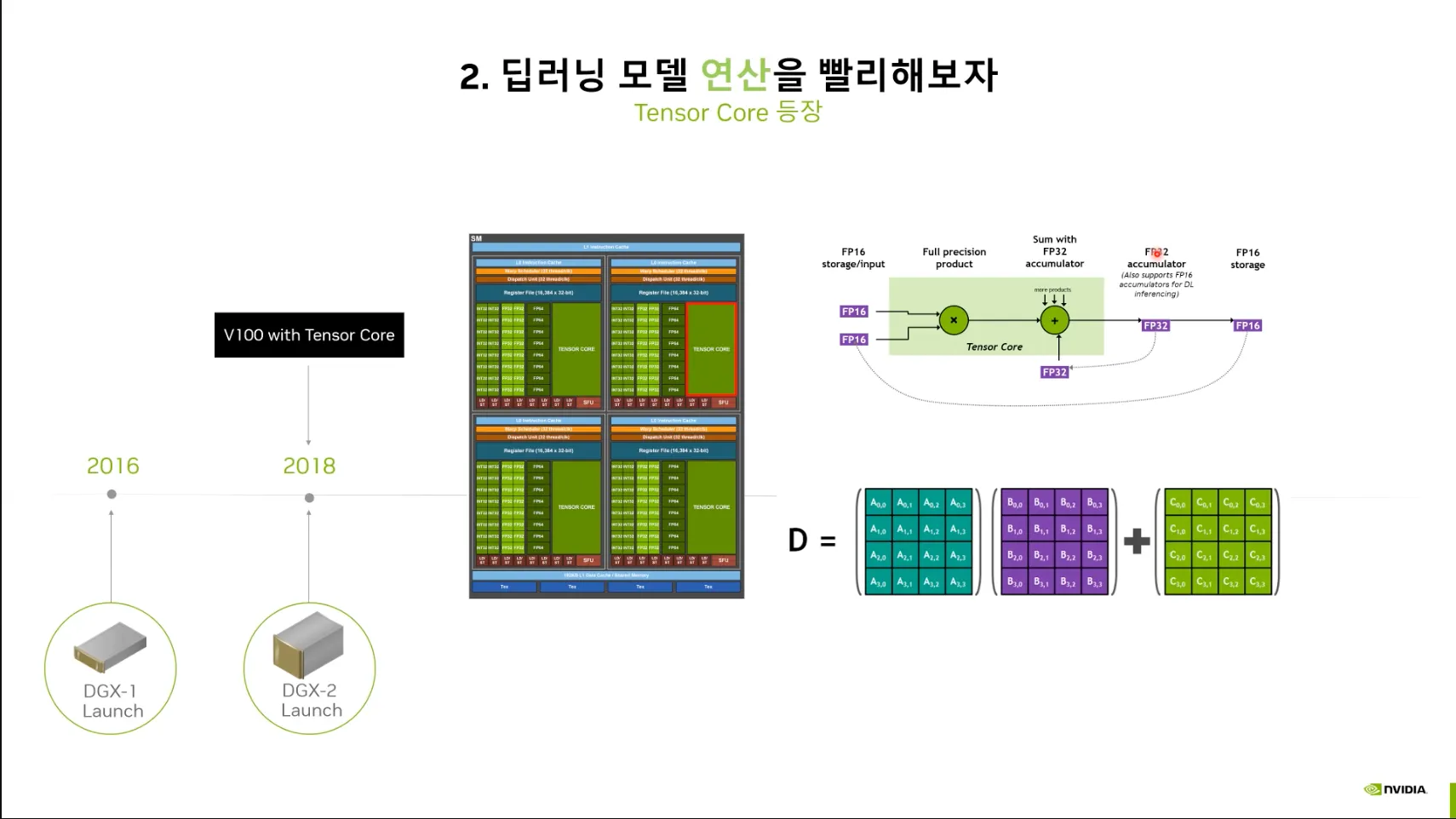
2018 더욱 빠른 연산: Tensor Core의 등장 - V100
•
CUDA Core → Tensor Core 가속화 도입.
•
딥러닝 워크로드에 특화된 가속화.
•
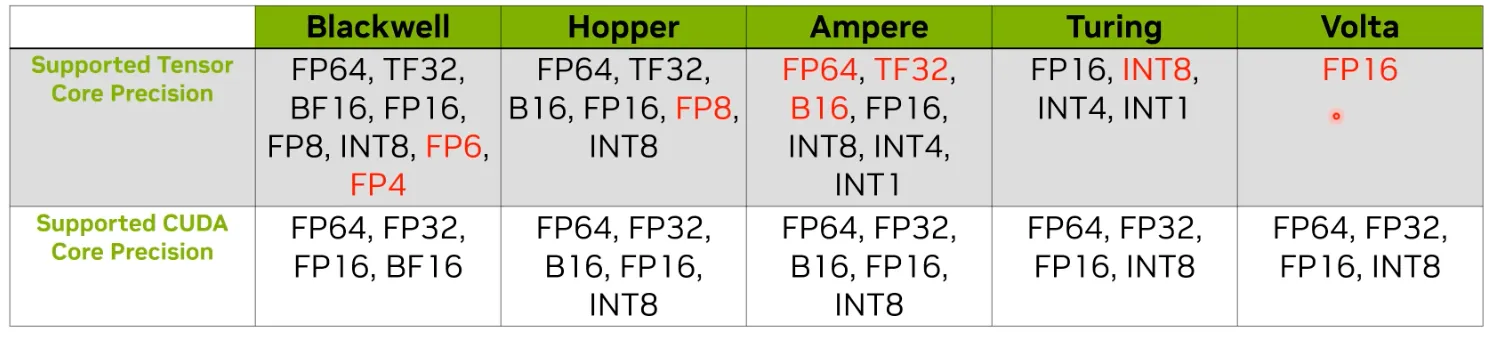
점점 더 많은 Data Type을 지원함.
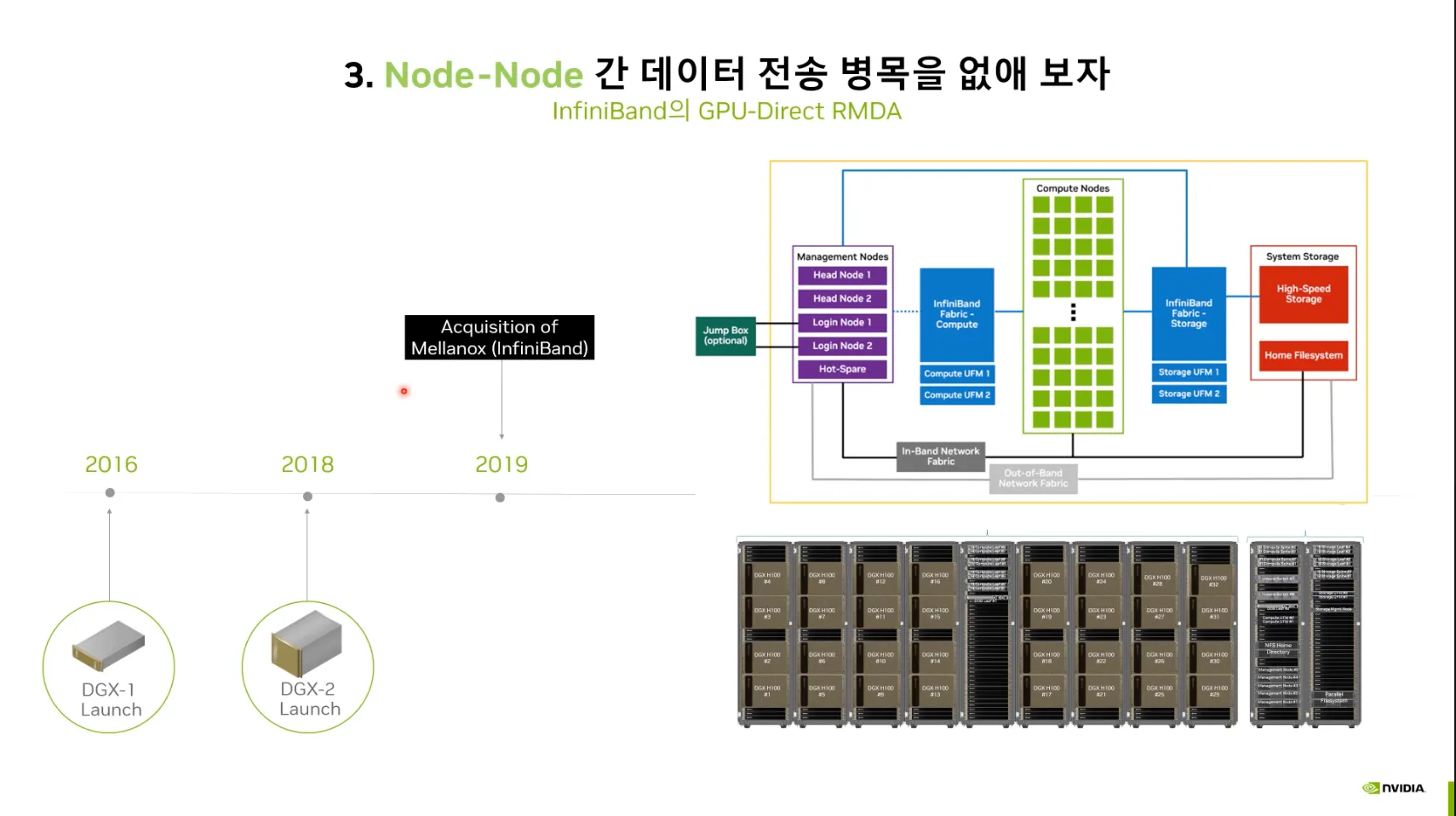
2019 노드에서 클러스터로.
•
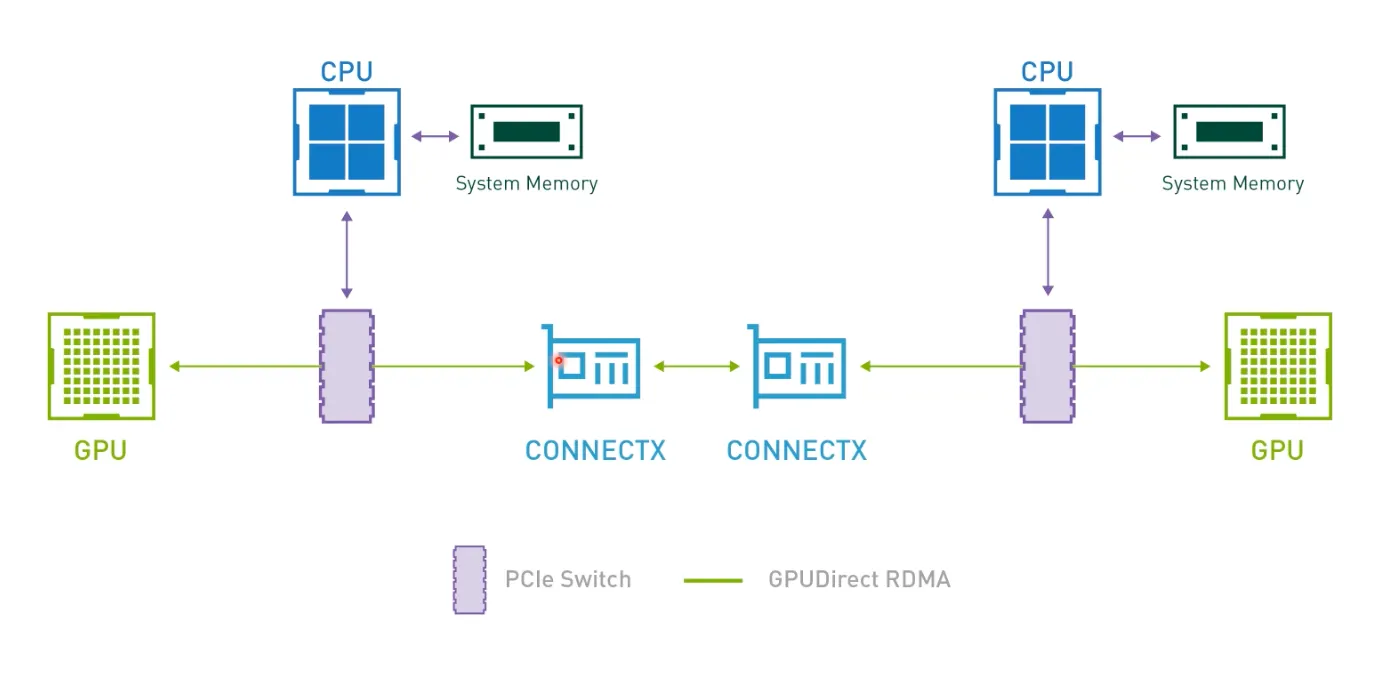
Infiniband의 GPU-Direct RDMA.
•
GPU간 통신 및 Node간 데이터 전송 병목 개선.
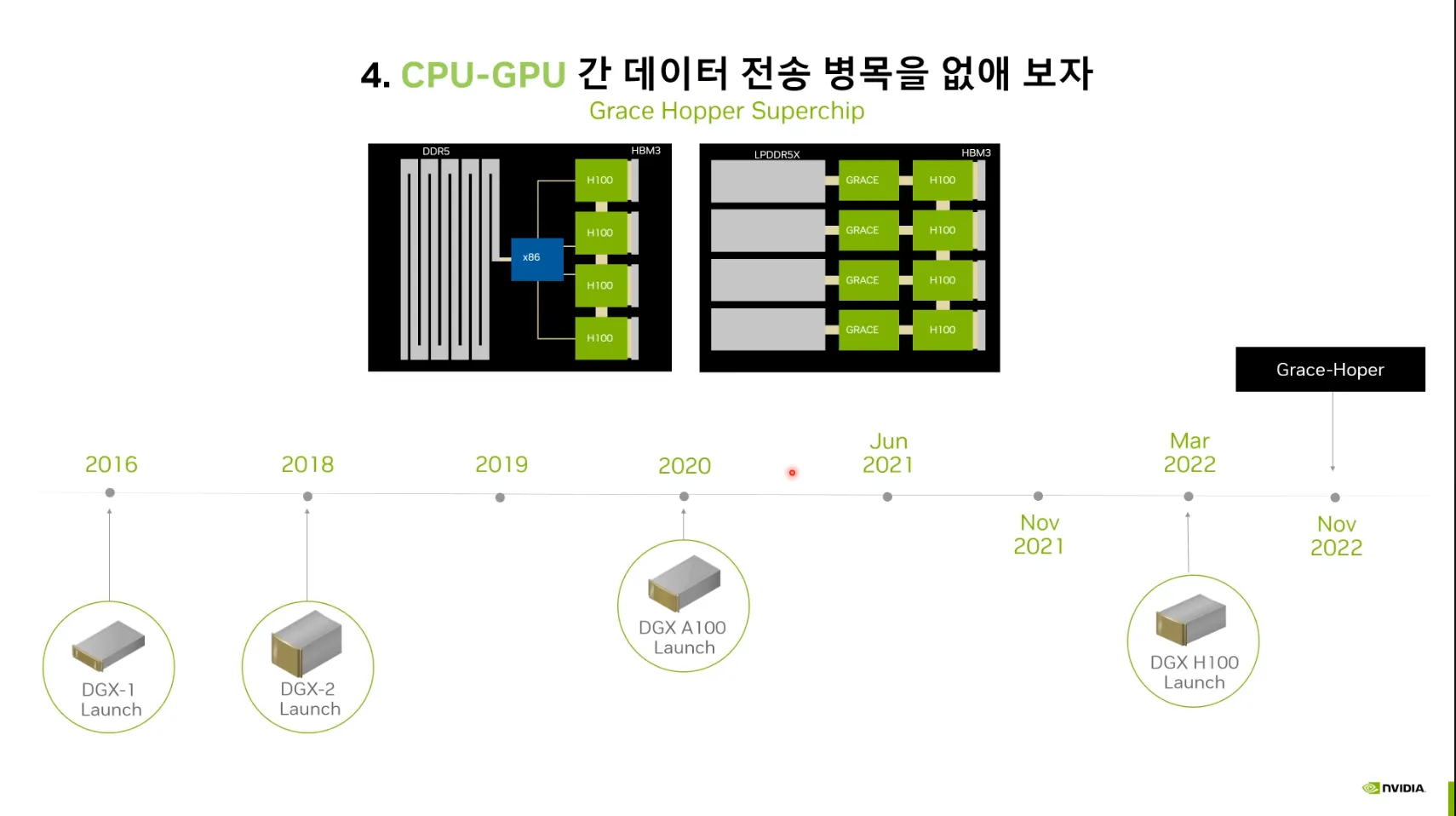
2022 CPU-GPU간 데이터 전송 병목 개선.
•
Grace Hopper Superchip
•
SuperChip 형태로 설계 (PCIE → GRACE)

2024 서버간 데이터 병목 개선 - Cluster를 하나의 노드로.
•
Grace Blackwell - GB200 + External NVLINK.
•
NVLINK의 넓은 Bandwidth를 이용해서 클러스트를 하나의 노드처럼 묶음.
•
기존의 서버단위에서 랙단위로 판매하기 시작함.
NVIDIA Product 목록:
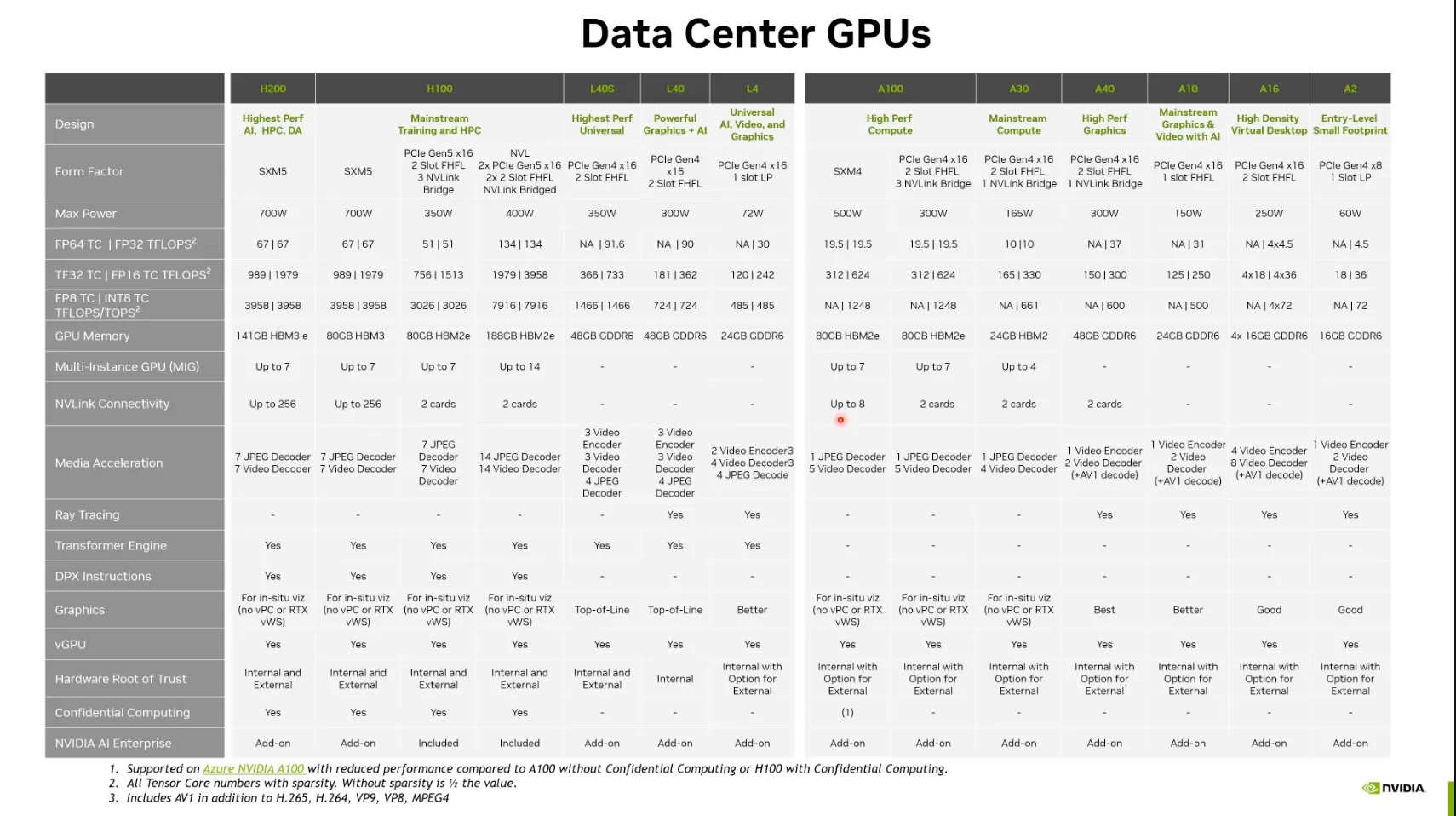
•
네이밍:
◦
알파벳 - 아키텍처 (H : Hopper, L: Light, A: Amphere)
◦
숫자 - 연산량 (100 < 200 < …)
•
제품군:
◦
Train용도와 Inference 용도를 구분해서 설계됨.
◦
H100, H200, A100 - Train용도에 적합
◦
L40, A40, A10, A2 - Inference 용도에 적합.
◦
A16 - GPU 메모리가 16GB X 4개가 들어있는 특이한 Product. VDI Remote VGPU 기술용. (Multiuser)
폼팩터 (Form Factor):

•
PCIE, SXM (NVLink)로 나누어짐.
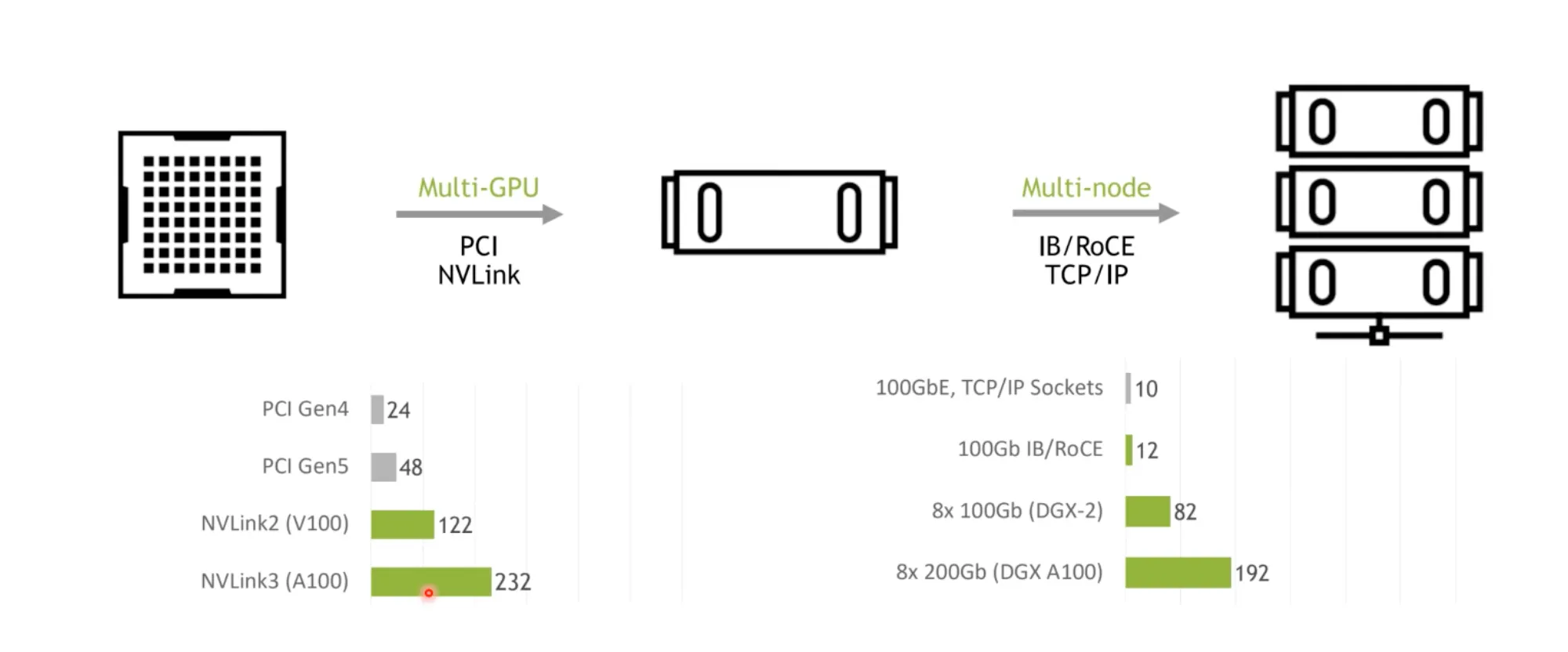
•
NVLink의 Bandwidth는 매우 파워풀함.
DGX H100 System Topology:
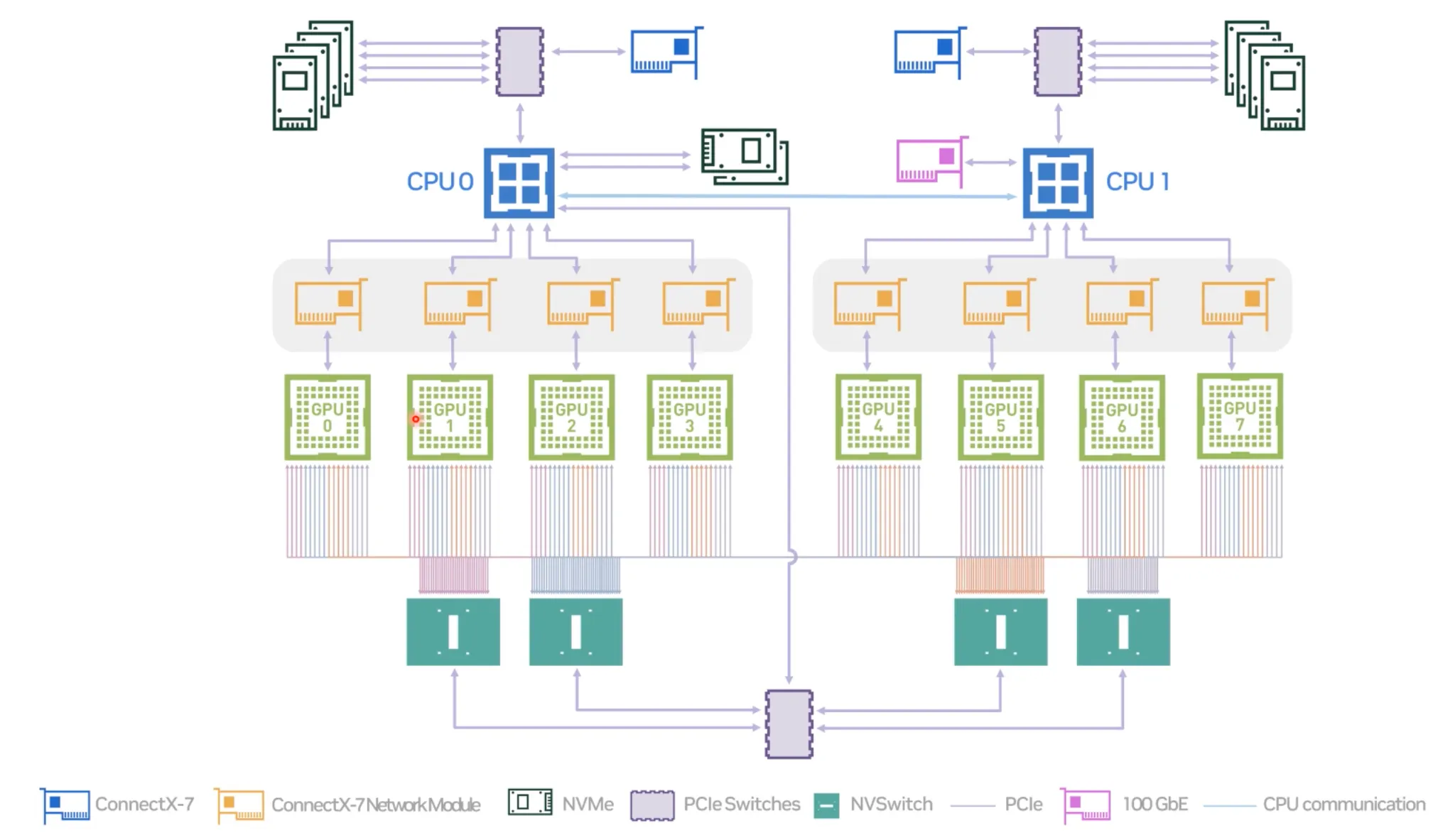
•
NVLink + Mick 카드로 구성됨.
•
서버간 더 빠른 커뮤니케이션 가능
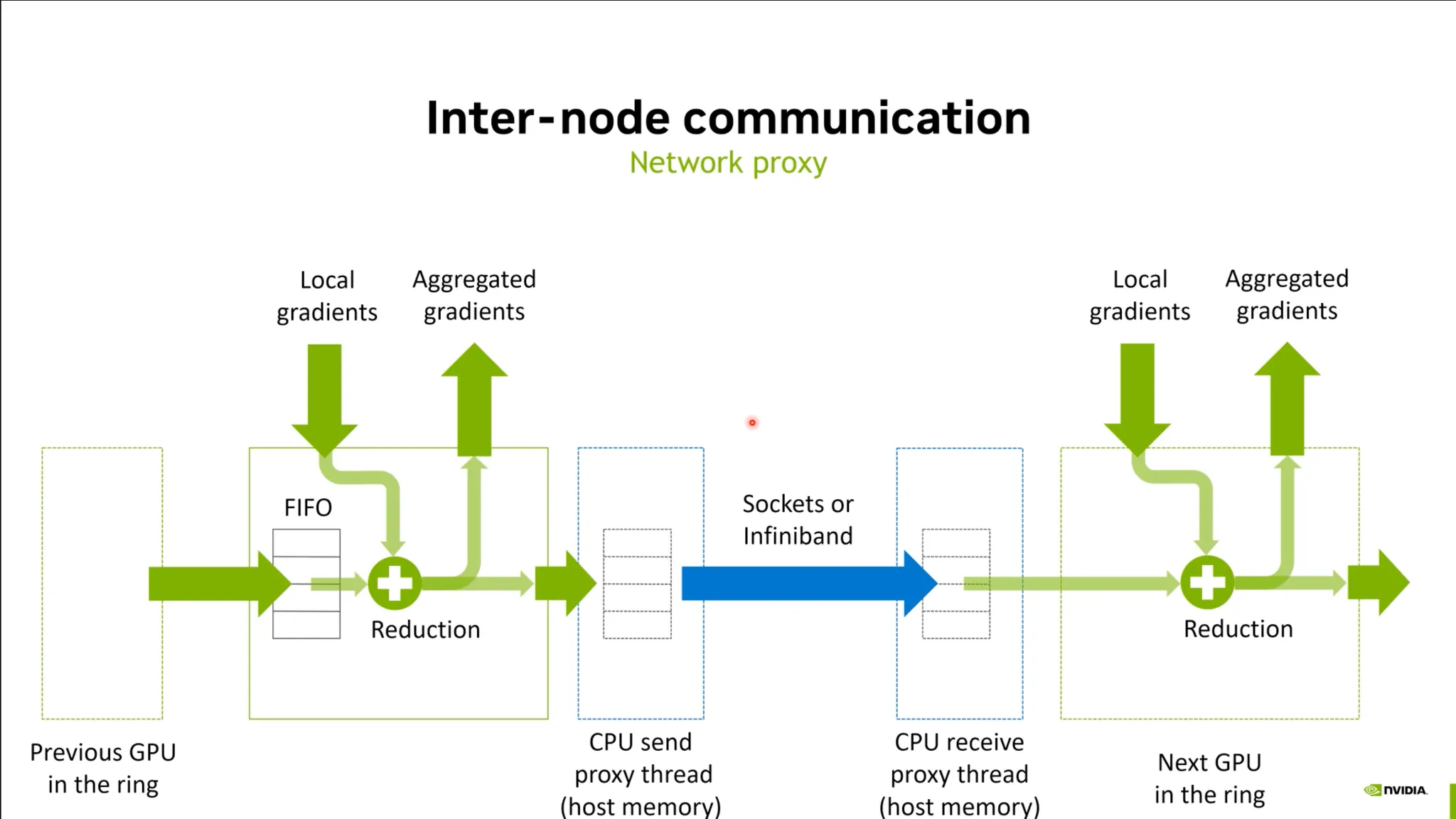
•
IDMA이라는 기술을 활용함.
•
원래 원격으로 메모리를 읽고 쓰는 기술이었음.
•
시스템의 메모리를 직접 Access하는 것이 아니라 GPU의 메모리에 접근함.
Computing Resource (Tensor Core)
Hopper Architecture
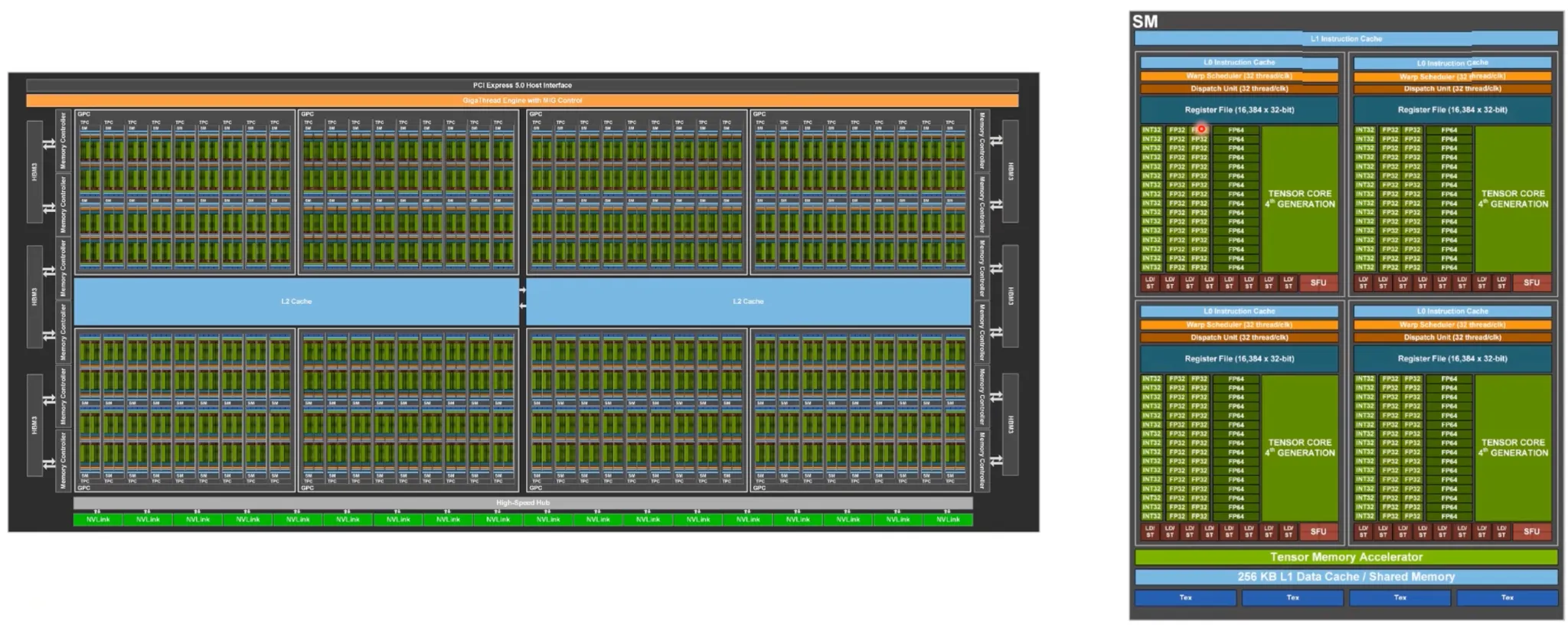
•
작업을 분배하는 스케줄러 내장
TensorCore
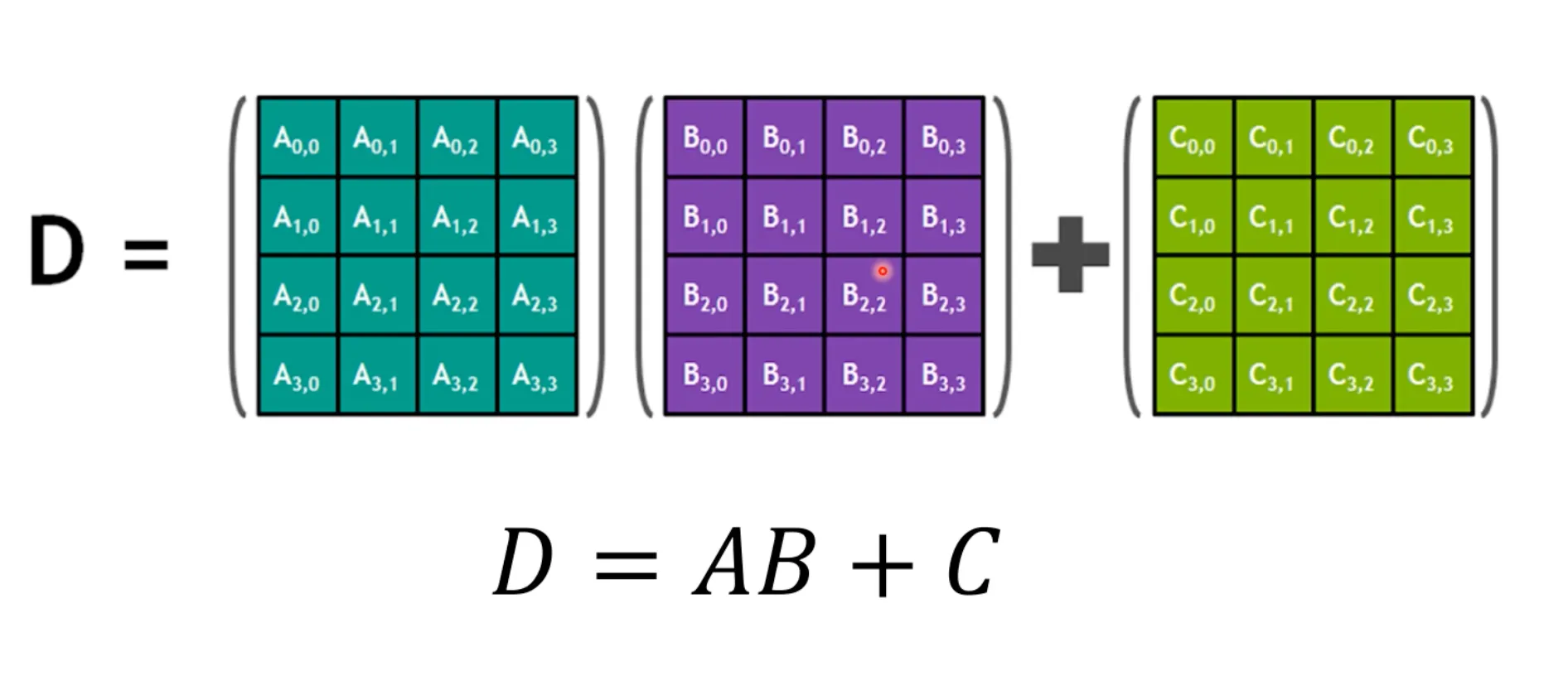
•
Matrix 곱을 하나의 Instruction으로 처리함.
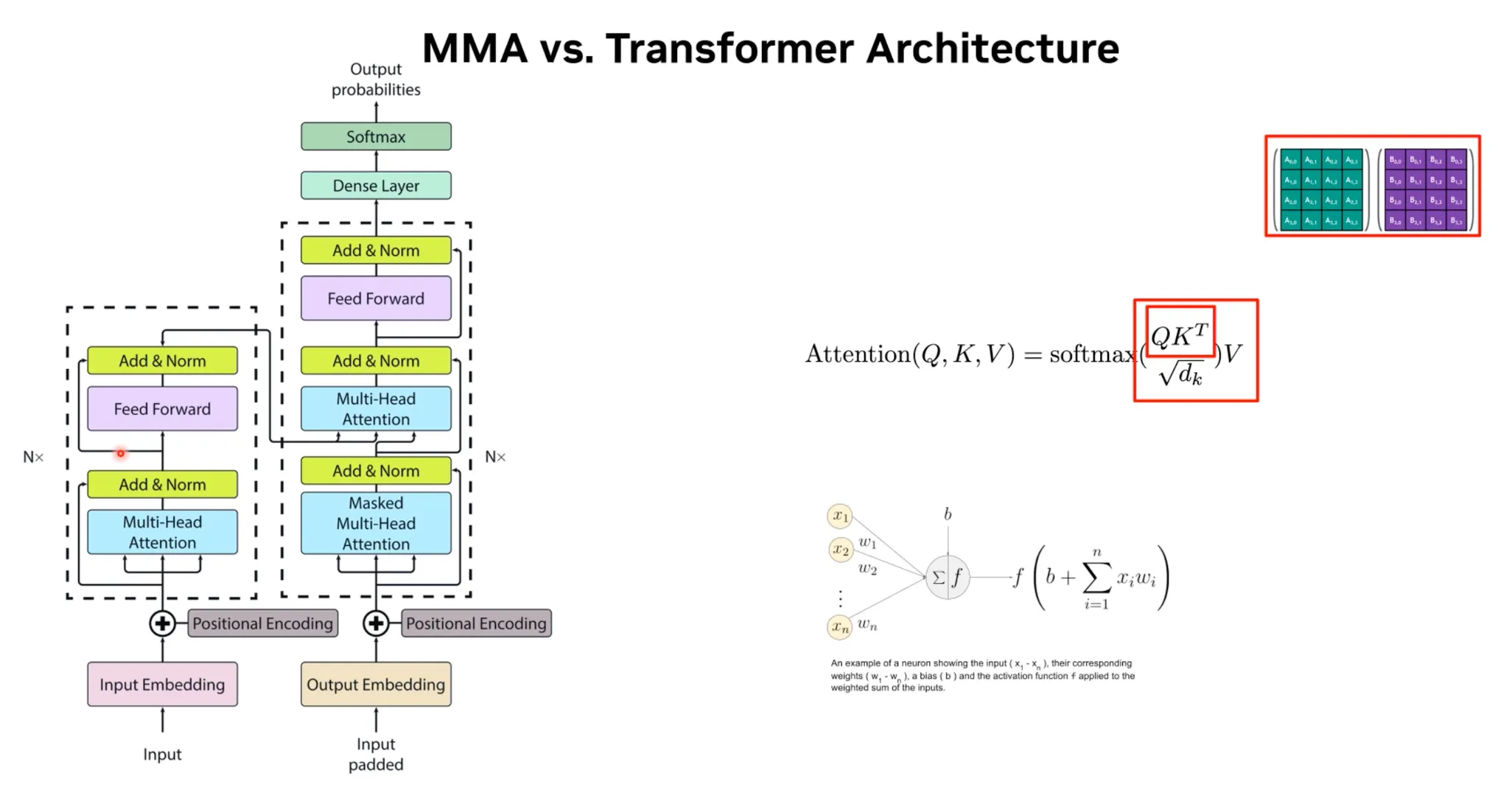
•
Tensor Core는 Transformer Architecture를 많이 가속화 시킬 수 있음.

•
Data Type의 Precision을 낮추면 가속화 여지가 더 많아짐.
Data Type의 Precision을 낮추는 이유:
Trade-off of Low Precisions:
•
장점:
1.
FLOPs를 더욱 증가시킬 수 있음.
2.
메모리 사용량과 Bandwidth workload를 감소시킬 수 있음.
•
단점:
◦
표현가능한 범위가 적음.
◦
작은 값에 대해서 overflow가 발생함.
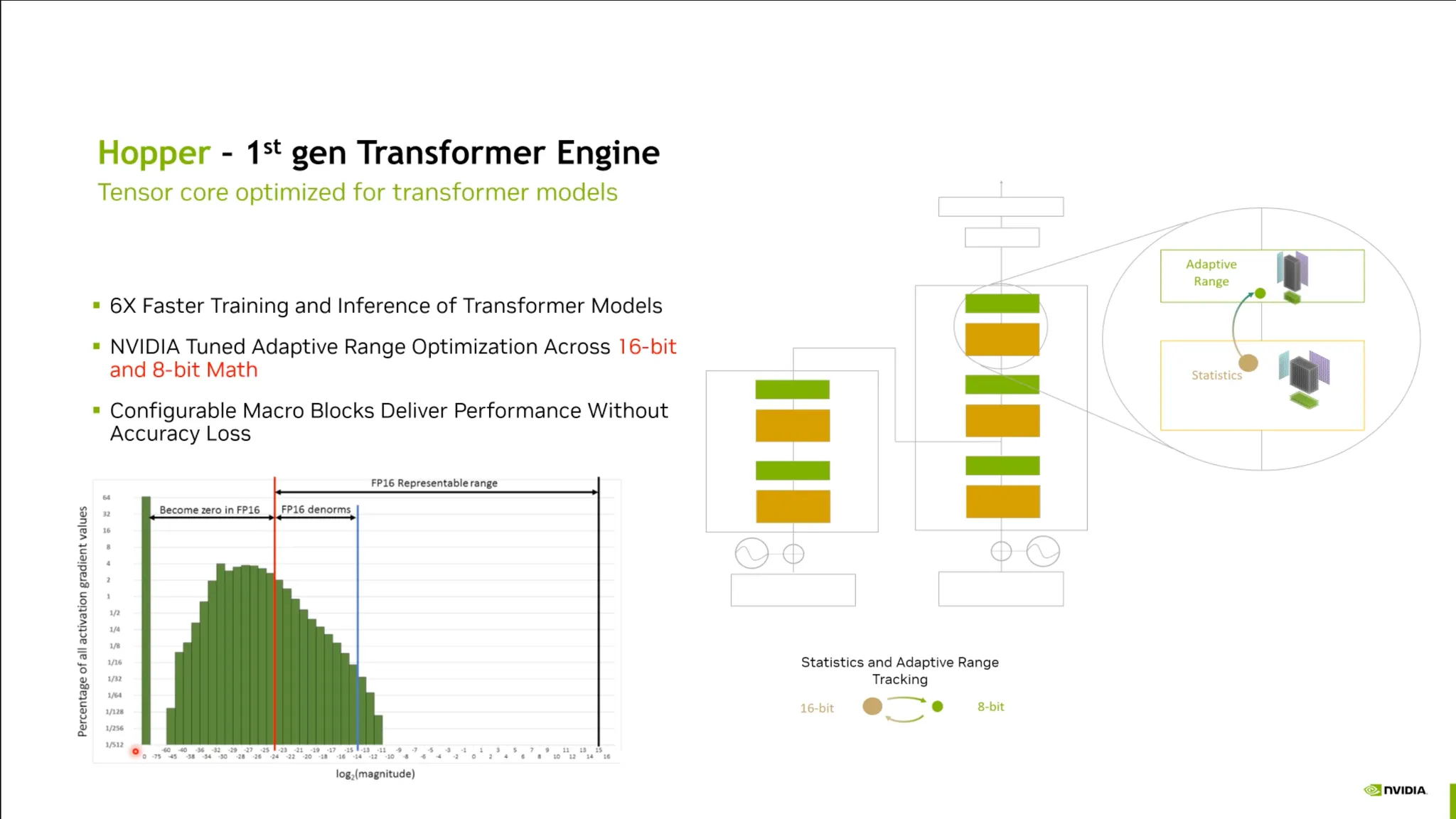
Hopper 아키텍처:
•
이런 단점들을 해결할 수 있는 문제가 솔루션안에 녹아있음. (Mixed Precision Training)
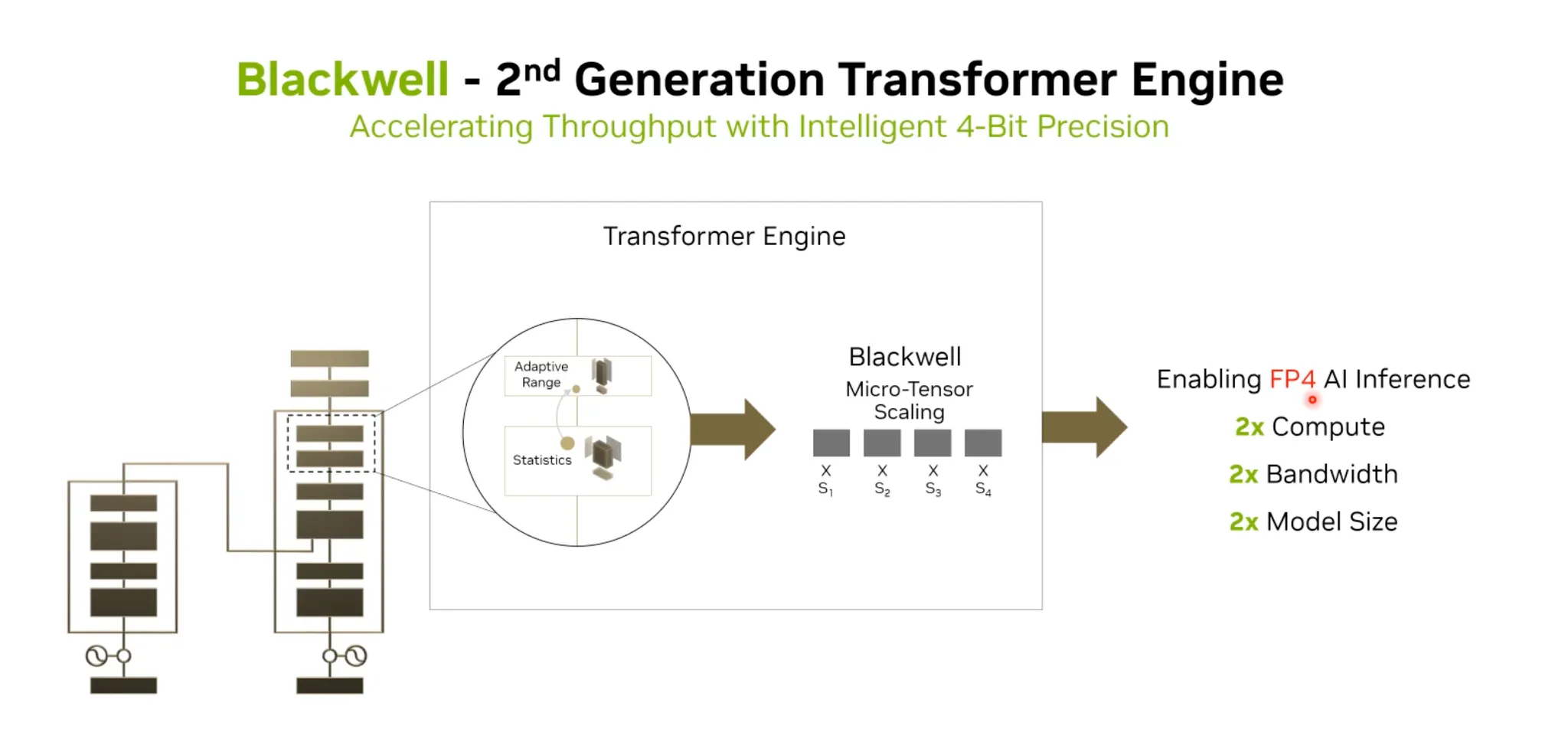
Blackwell 아키텍처:
•
FP4까지 더욱 낮은 Precision을 지원함.
MIG: GPU를 더 쪼개보자.

하드웨어 인코딩 및 디코딩 기술
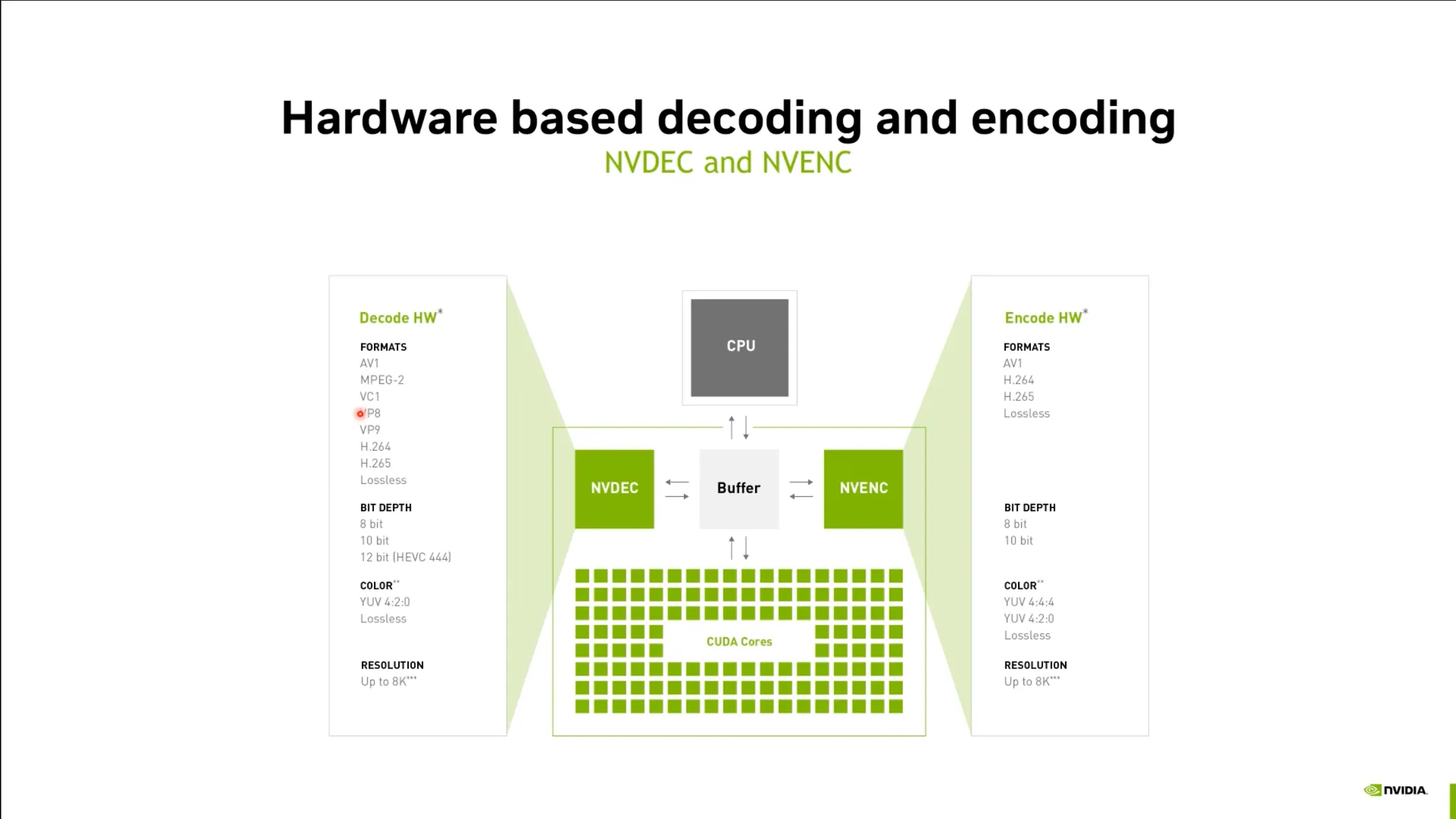
•
비디오 디코딩을 하드웨어에서 처리함.
•
비디오 스트리밍등의 속도 개선.
렌더링 가속화 기술: Ray Tracing
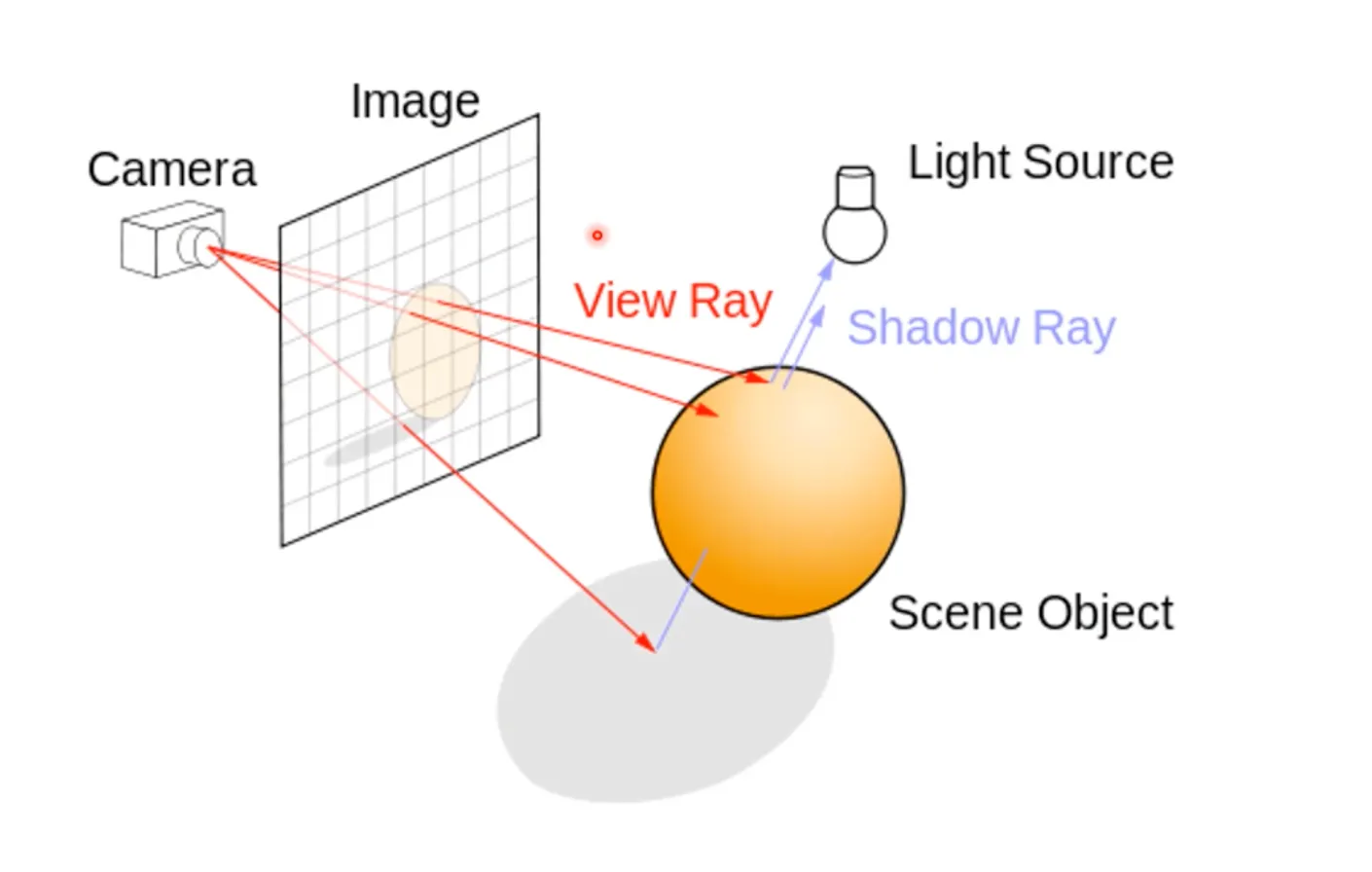
•
렌더링 속도: 얼마나 많은 Vertex를 연산할 수 있는가?
◦
예전에는 사실적 렌더링을 위해 몇일 ~ 몇주가 소요되었음.
•
Ray Tracing: 빛의 경로를 역추적하는 기술.
◦
현실 세계에서 사람이 보는 것을 사실적으로 표현함.
◦
Bounding Volume Hierarchy 알고리즘 도입
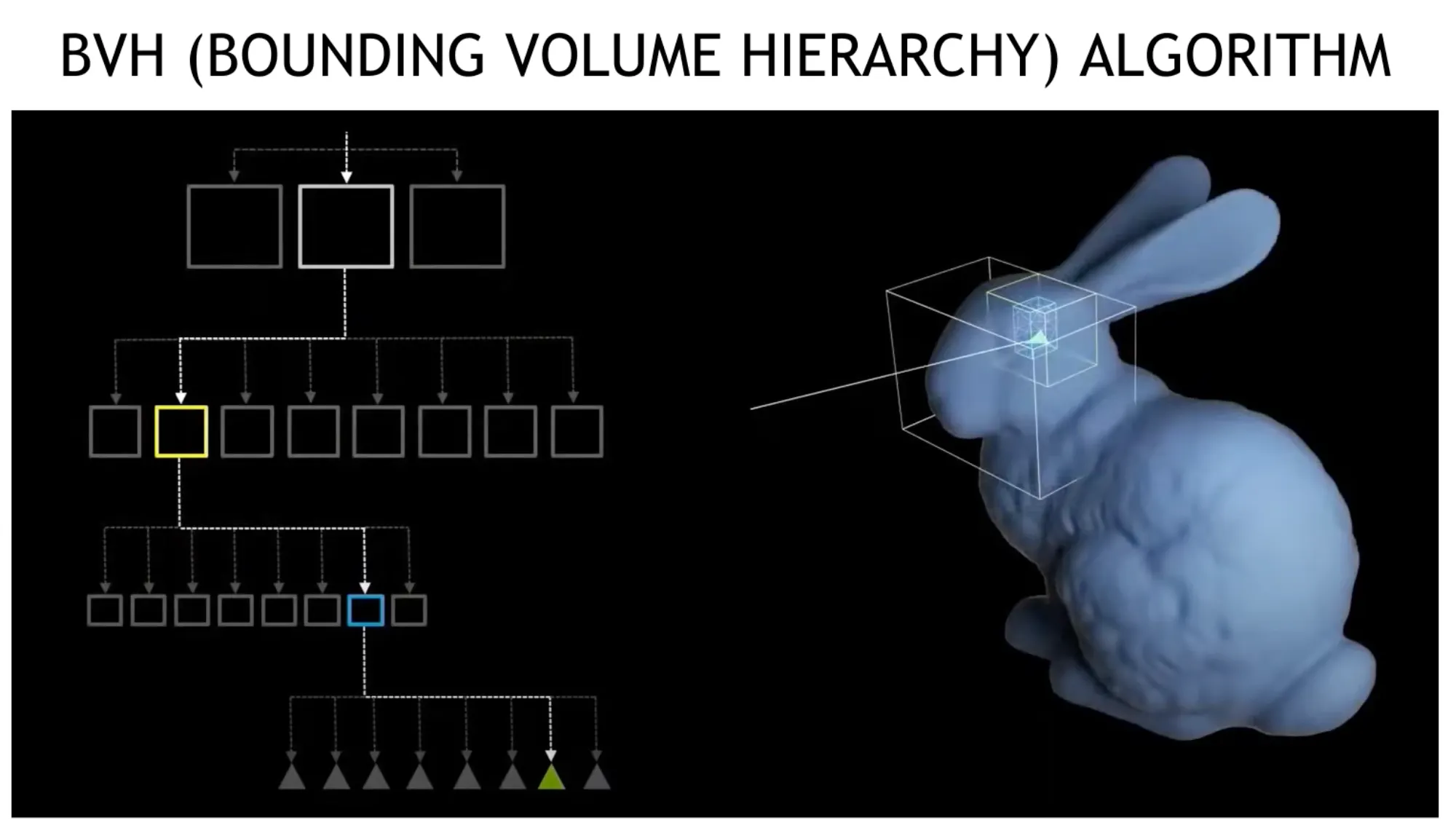
•
트리를 만든 후 빛의 경로를 추적함.
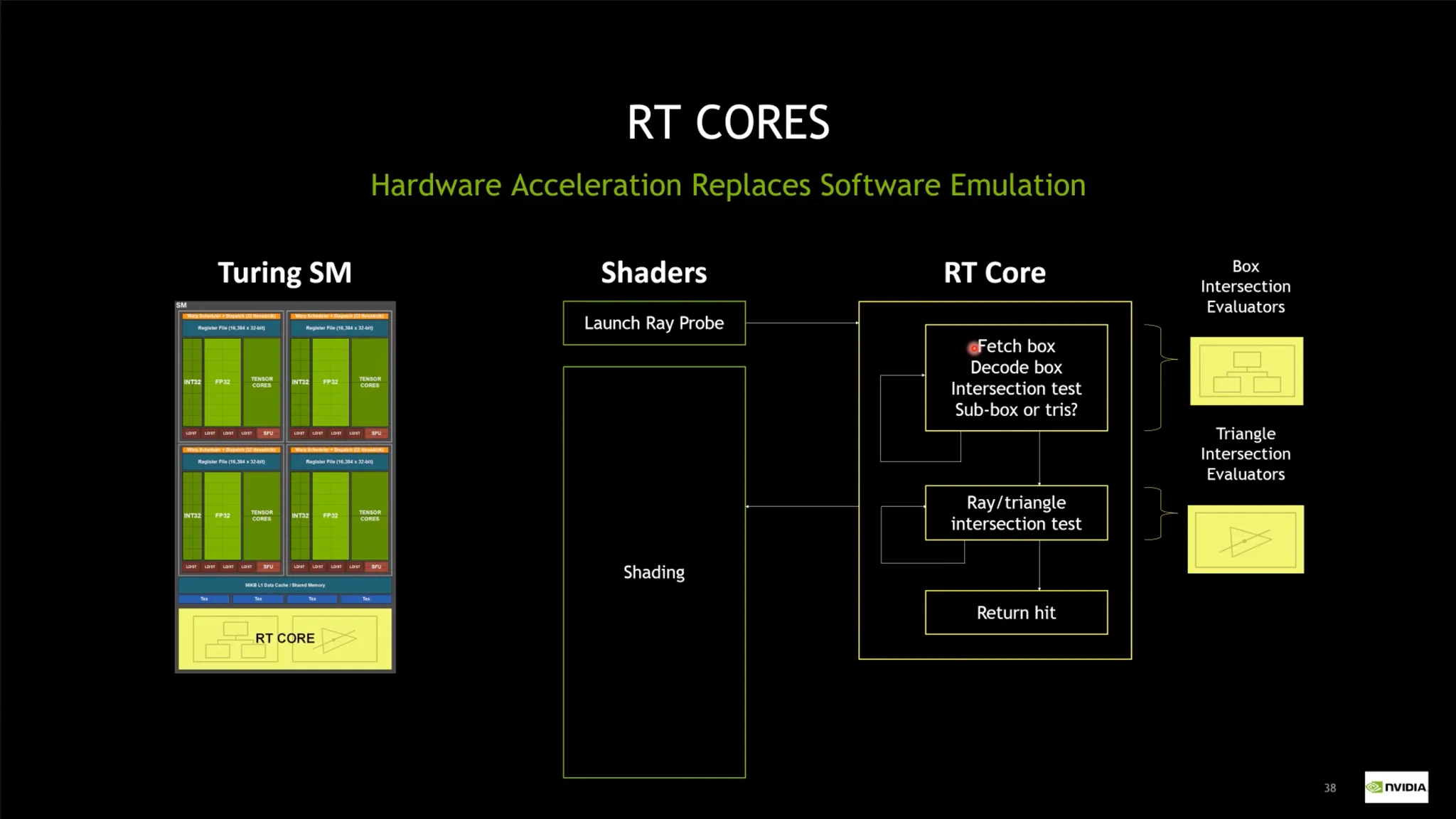
•
RT Core - 렌더링 시 BVH를 효과적으로 처리할 수 있는 워크로드.
◦
해당 기술은 L40등에 적용되어 있음. (H100에는 미적용)
NVIDIA AI Enterprise 라이선스
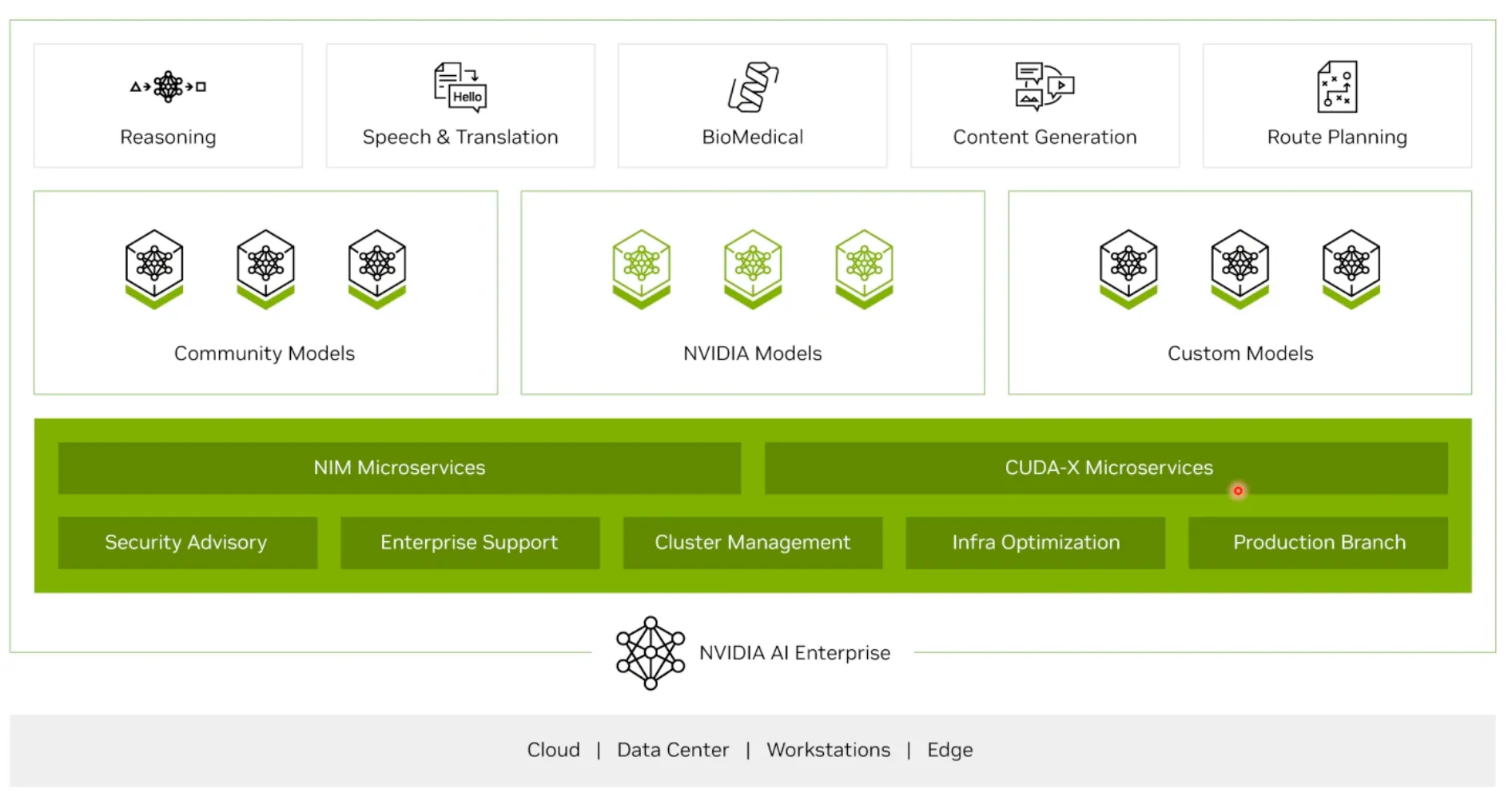
•
Urgent한 Issue가 생겼을때, 지원을 빠르게 받을 수 있음.
•
다양한 Software Stack들에 대해서 지원을 받을 수 있음.
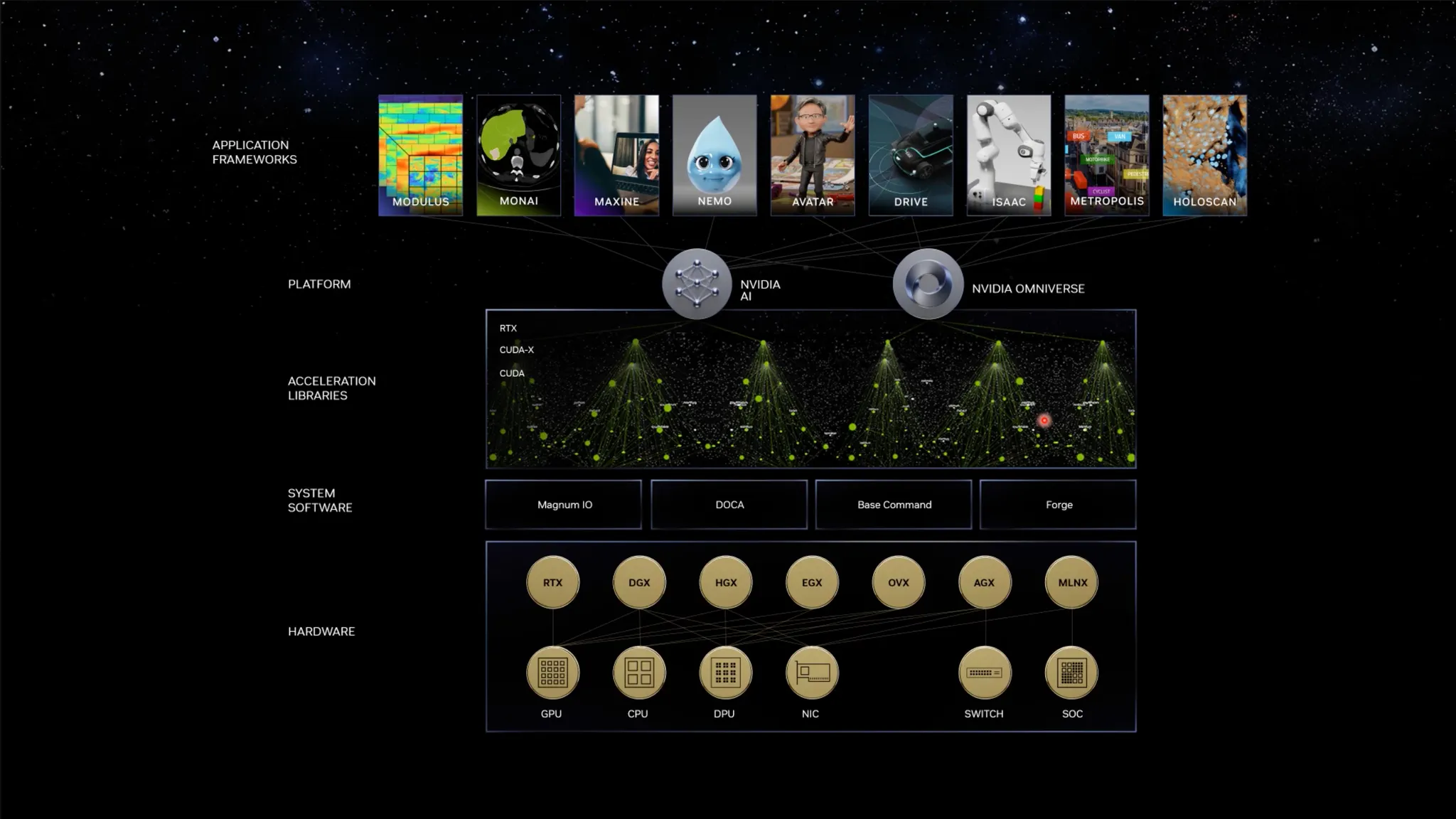
•
하드웨어 기반 가속화 솔루션 개요.
Beyond GPU
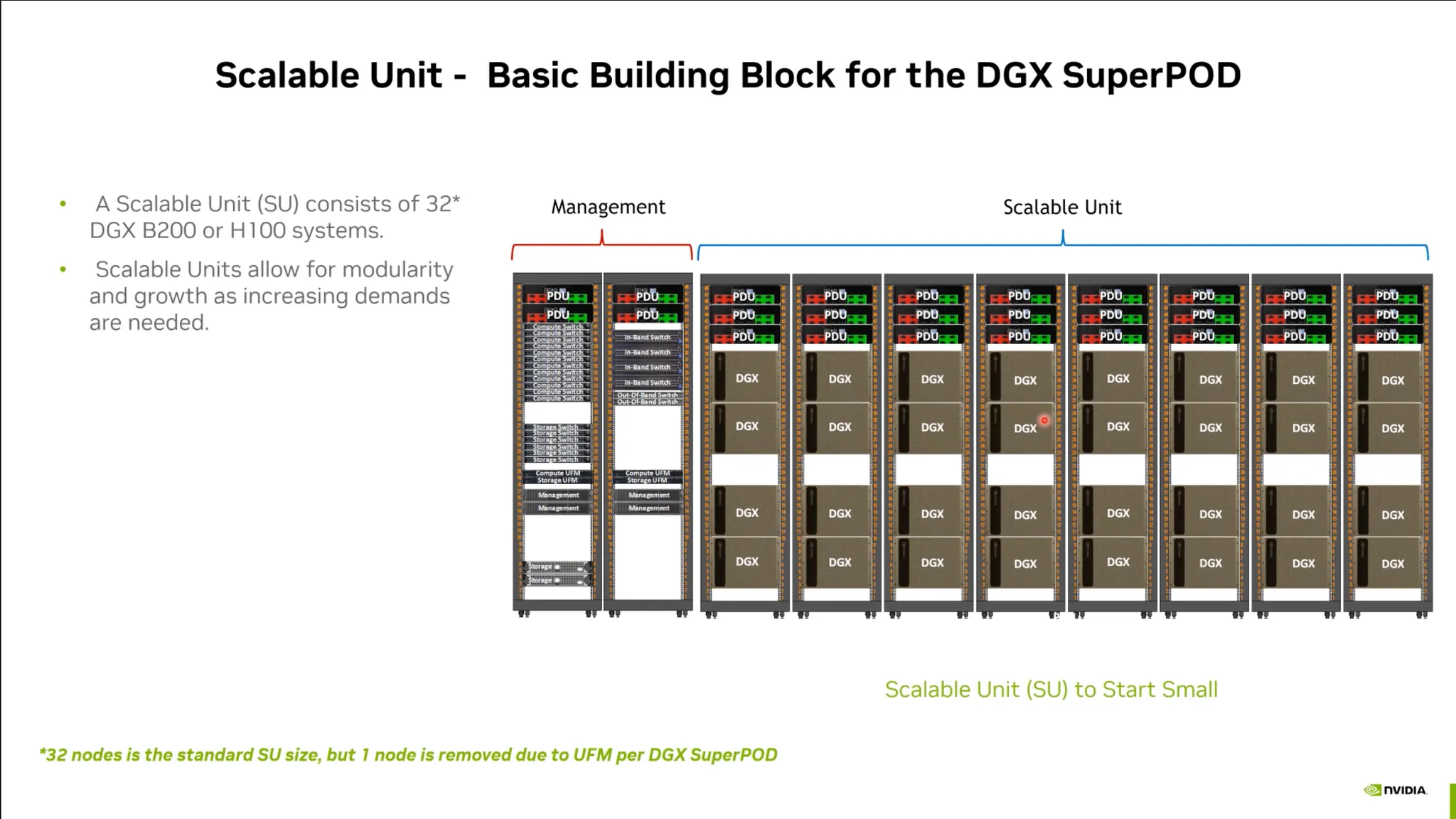
•
클러스터 단위의 솔루션
◦
네트워킹, 전력 등을 추가로 고려해야 함.
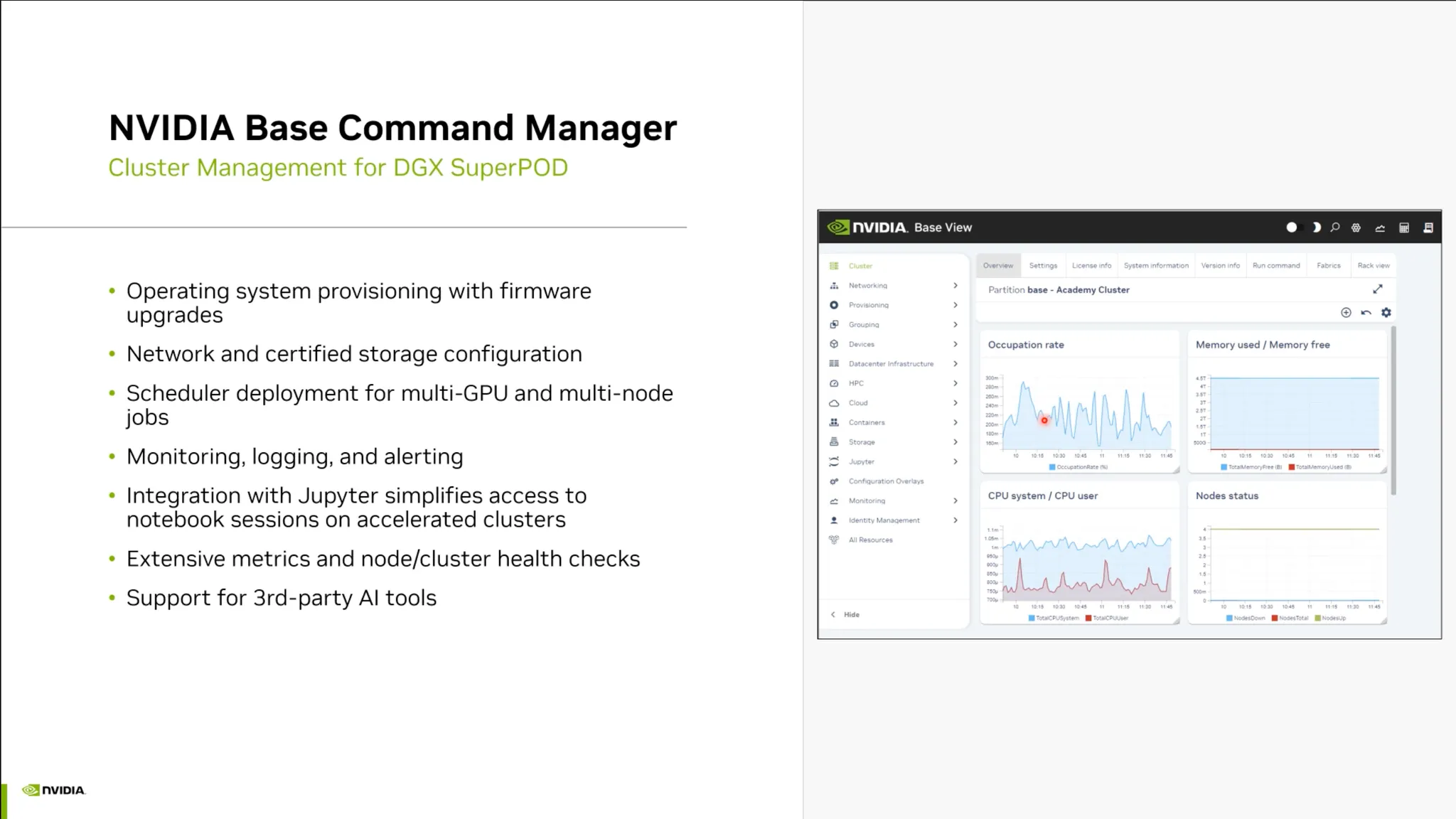
•
매니지먼트 소프트웨어 역시 중요함.
◦
Backend.ai 등의 솔루션.

•
NVIDIA는 “Platform” 이라는 표현을 씀.
•
하나의 플랫폼은 GPU 뿐 아니라 NVLink, NIC등의 요소들을 포함.
Data Center의 비용 함수:

•
최적의 Data Center 구축을 위해서는 Workload의 Throughput과 Utilization을 높이는 기술이 필요함.