


AICA X NVIDIA Cluster GPU 교육 시리즈
4. 분산학습을 통한 가속화
홍광수 박사 (솔루션 아키텍트, NVIDIA))
NVIDIA x AICA Cluster GPU 활용 캠프 (2024/08/26 - 09/05)
•
분산처리의 기본 개념과 알고리즘을 알아본다.
•
딥러닝에서의 병렬처리 알고리즘을 알아본다.
◦
Data / Model / Tensor / Hybrid Parallelism
•
실제 코드에서 분산학습을 적용하는 방법을 알아본다.
분산처리의 기본 개념

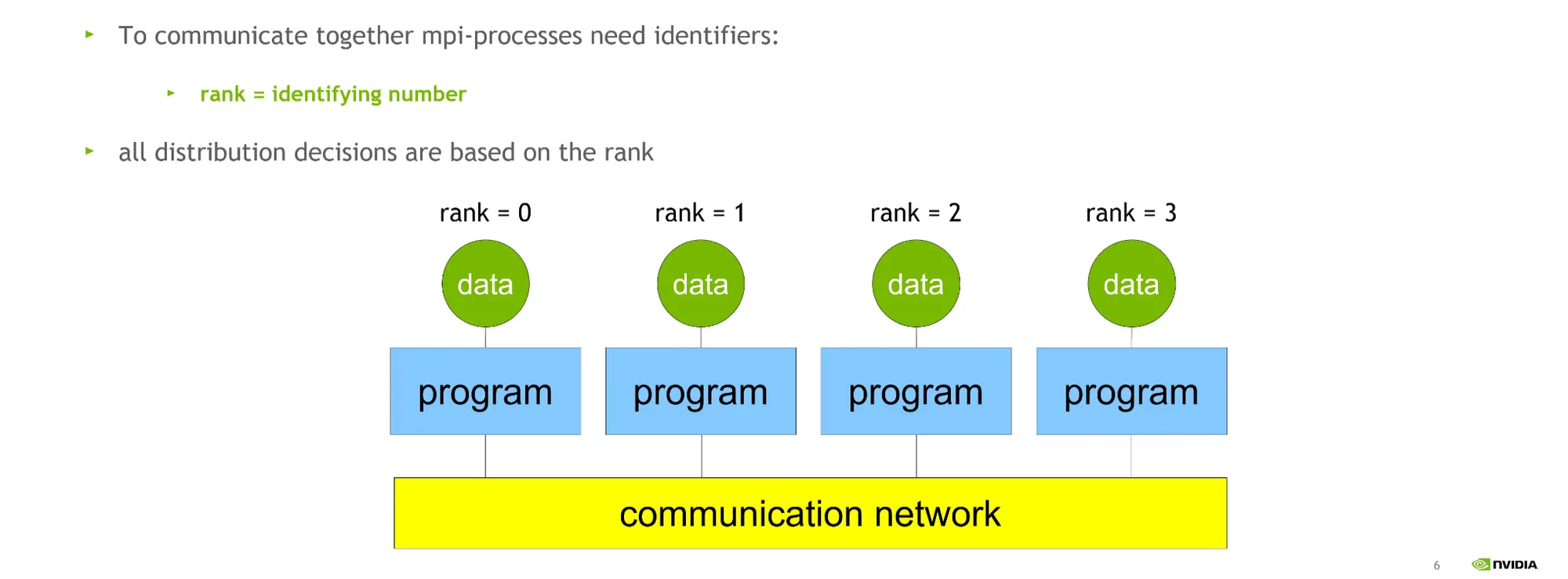
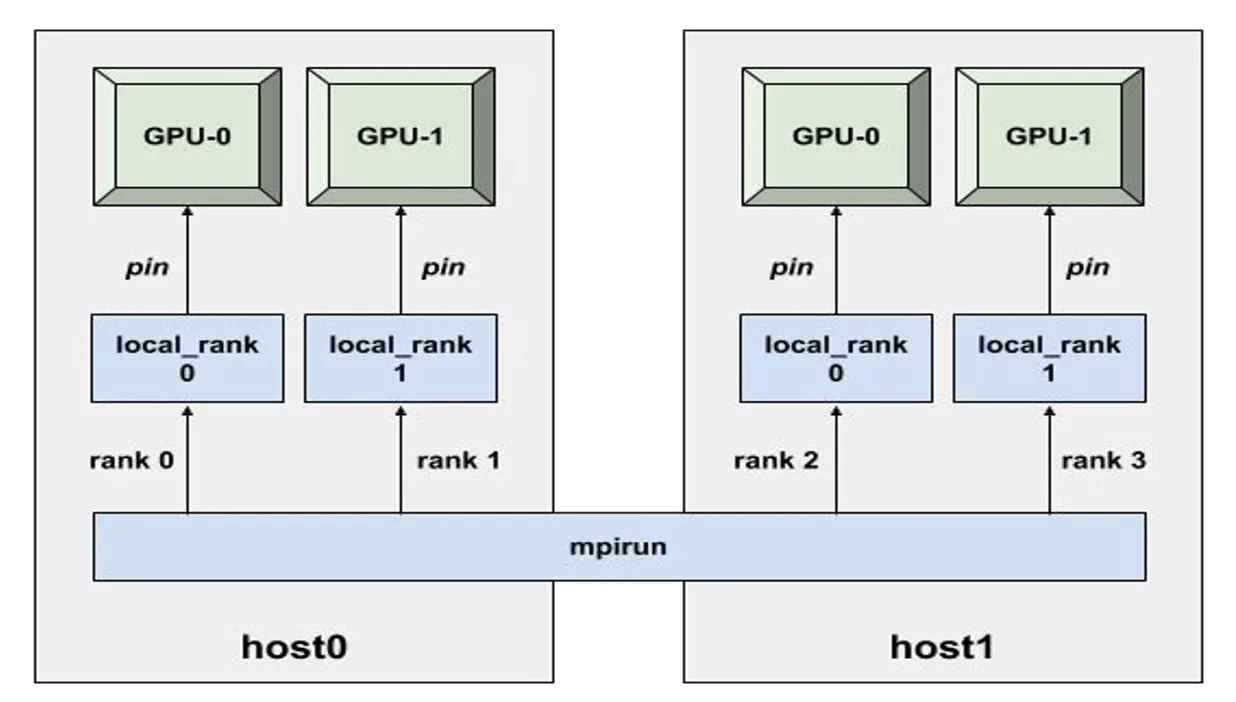
•
서버 2개 (host0, host1) 안에 GPU 2장씩 있다고 가정하면:
◦
local_rank : 로컬 식별자 (local_rank 0)
◦
global_rank: 글로벌 식별자 (rank 0, …, rank 3)
Task 간의 통신: Communication among tasks
•
Point-to-point Communication
◦
Single sender, single receiver
◦
Relatively easy to implement efficiently
•
Collective Communication
◦
Multiple senders and / or receiver
◦
Patterns include broadcast, scatter, gather, reduce, all-to-all, …
◦
Difficult to implement efficiently.
Collective Communication
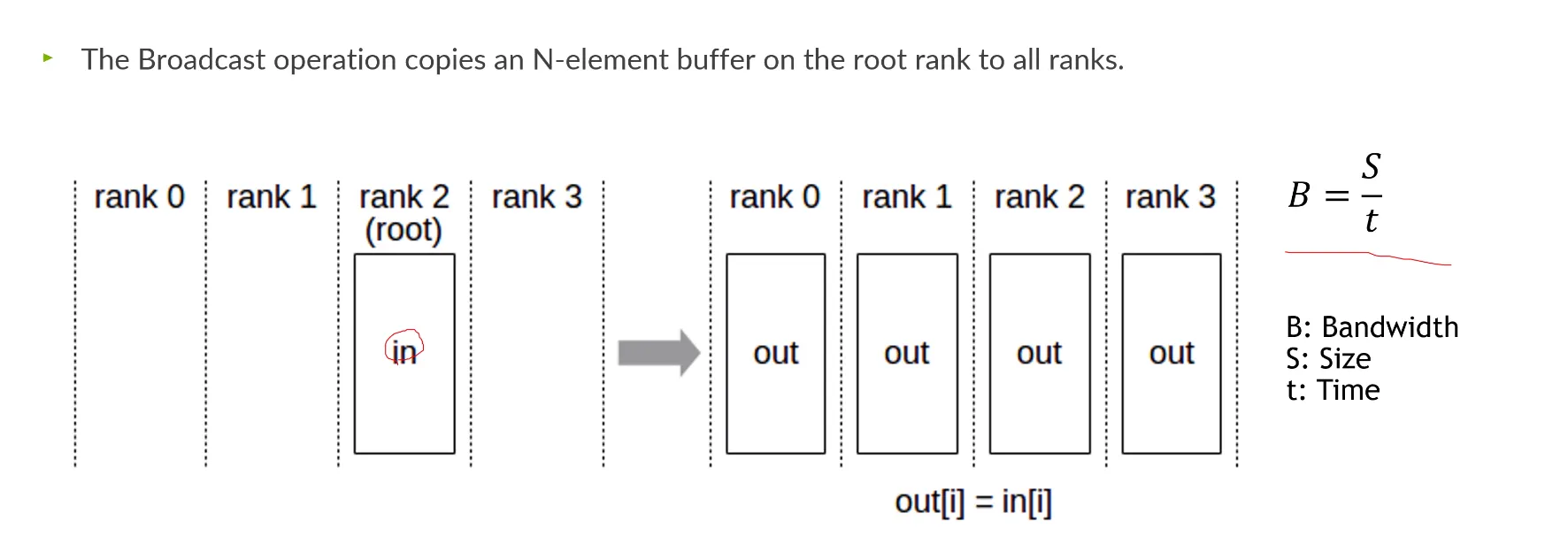
•
Broadcast: 데이터를 전체 rank에 걸쳐서 전송하는 것.
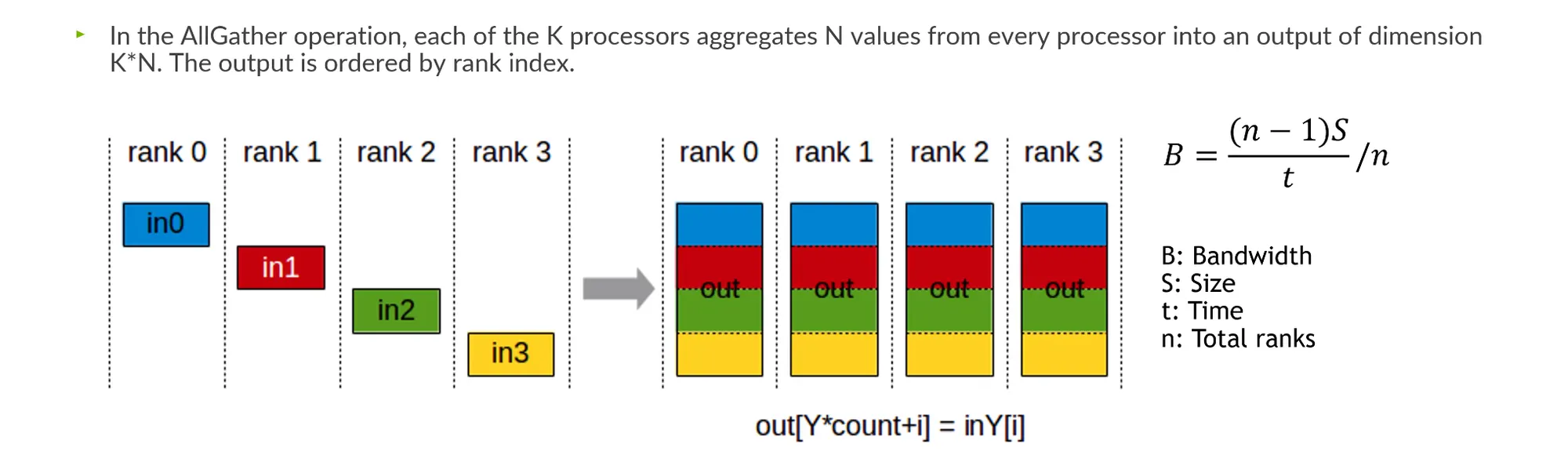
•
AllGather: 각 rank의 데이터를 하나로 합친 후 다시 broadcast 하는 것.
•
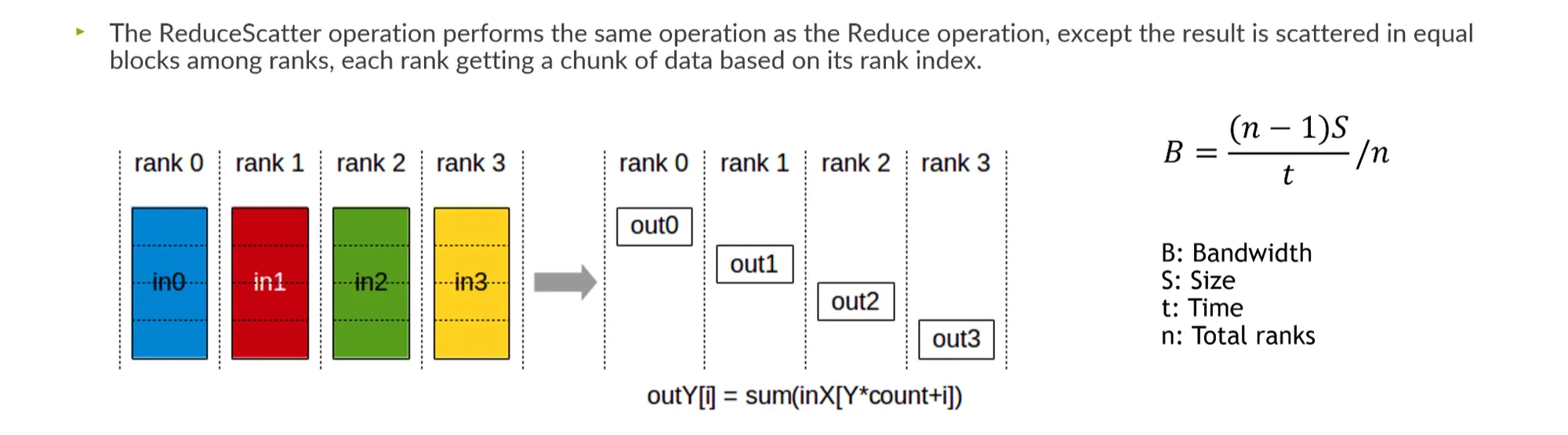
ReduceScatter: 각 위치의 데이터를 rank에 나누어 걸쳐서 전송.
•
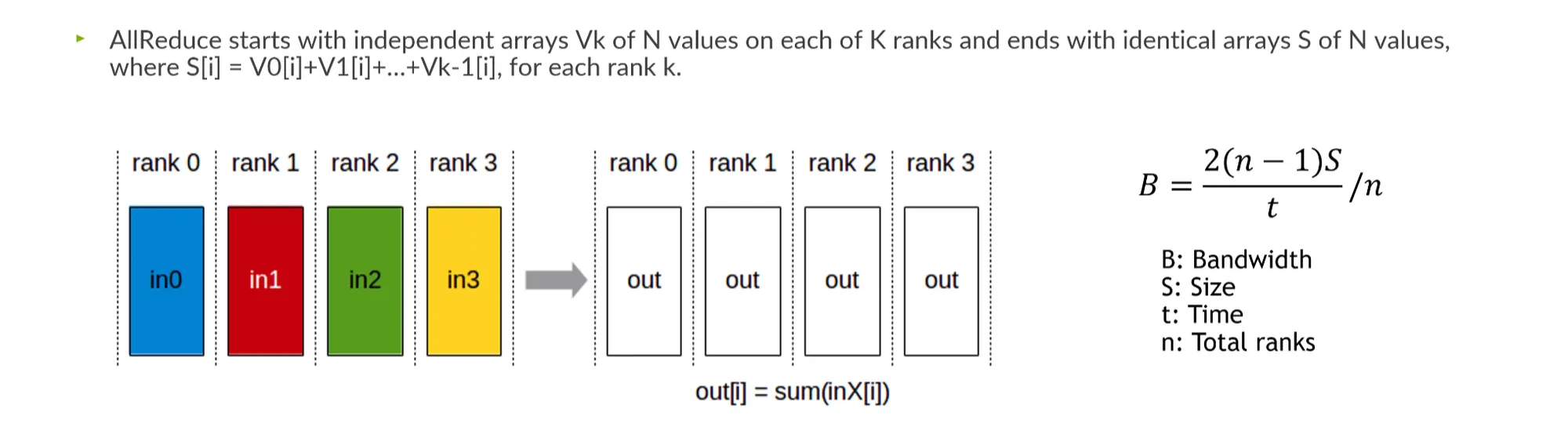
AllReduce: 전반적으로 걸쳐있는 데이터를 summation한 후 broadcast.
그렇다면 어떻게 데이터를 전송할 것인가?
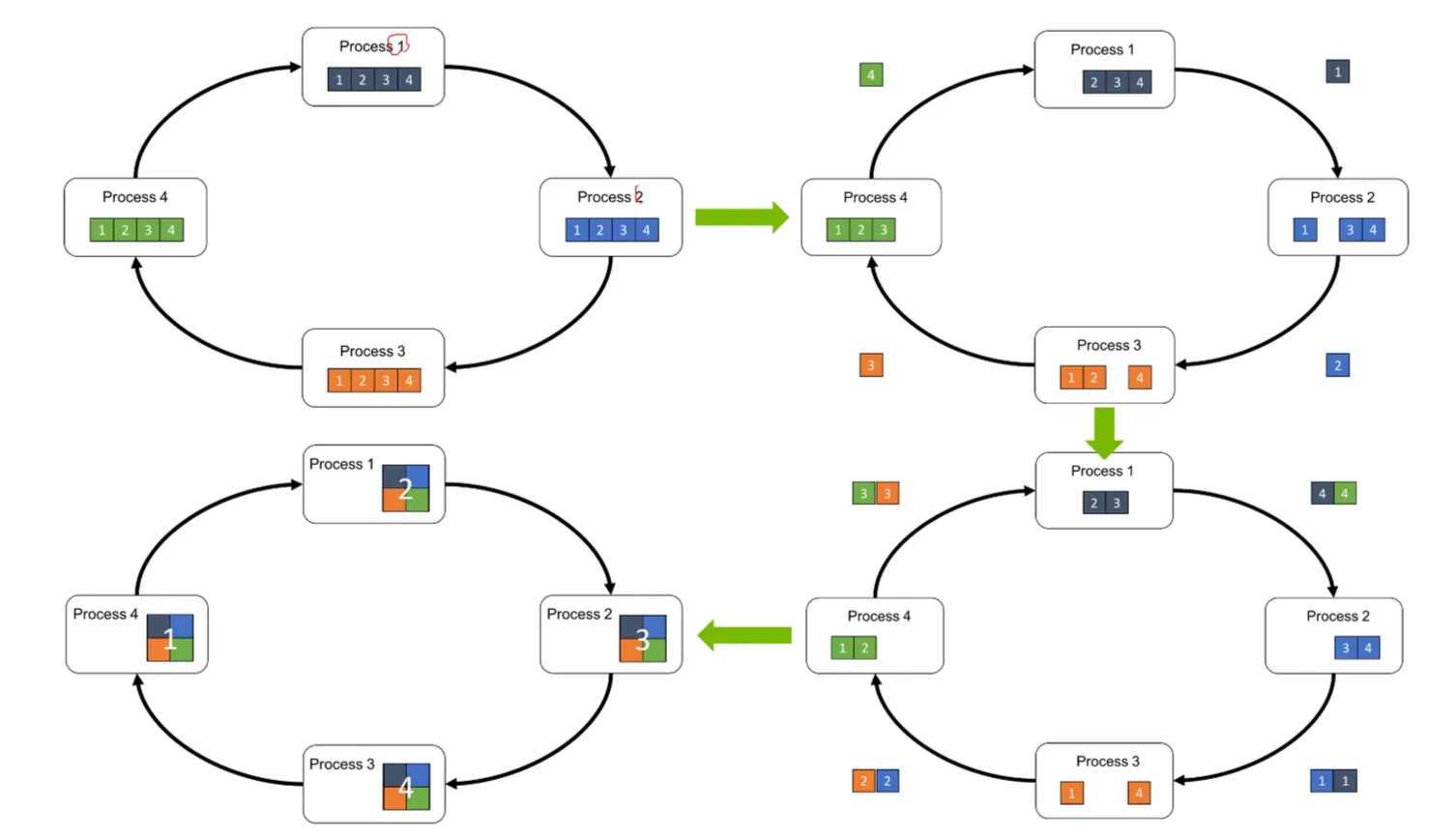
Ring Based All-Reduce:
•
Process 1의 데이터를 2로 옮기고, 3으로 4로 옮겨서 sumation을 한다.
•
전체 index를 골고루 나누어 summation할 수 있다.
•
“Topology를 ring으로 구축한다.”
•
딥러닝 학습 시 이렇게 링으로 구축 후 collective communication을 한다.
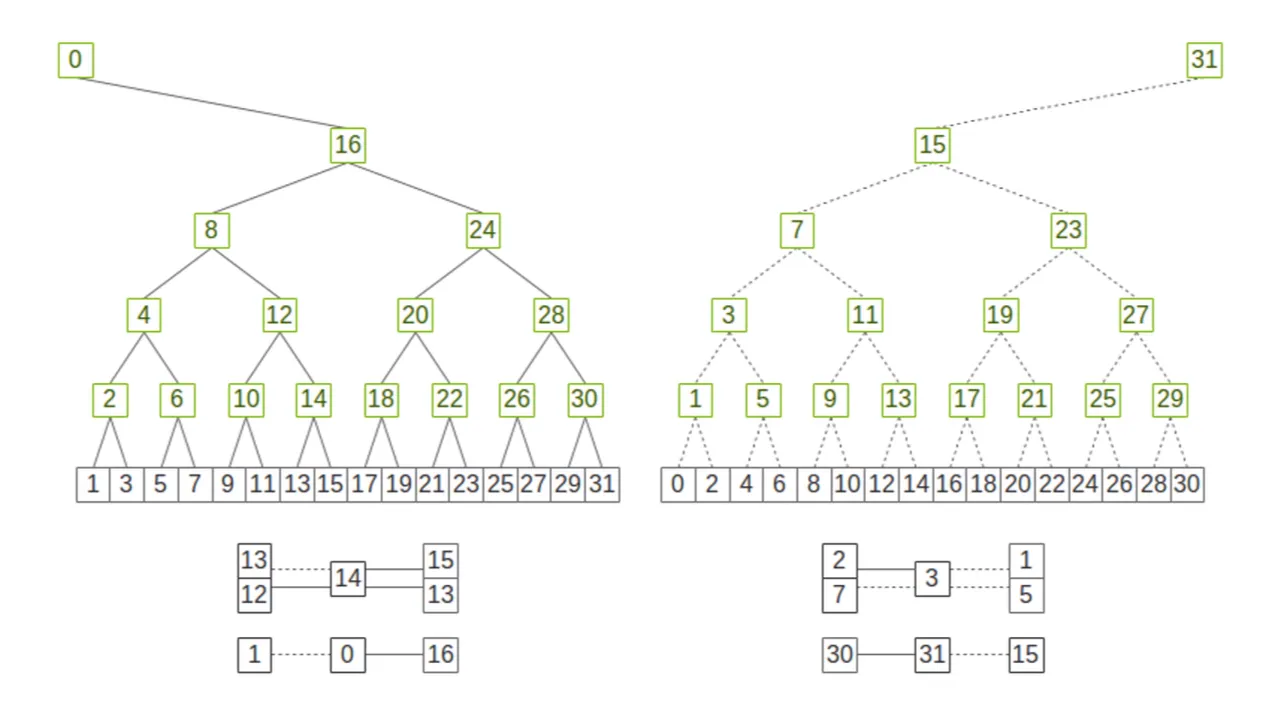
Double Tree Based All-Reduce:
•
트리 기반으로 Topology를 구성한 후 summation한다.
그렇다면 이런 것들을 개발자가 잘 알 필요가 있을까?
→ NCCL 라이브러리 안에 이미 잘 구현이 되어있다!
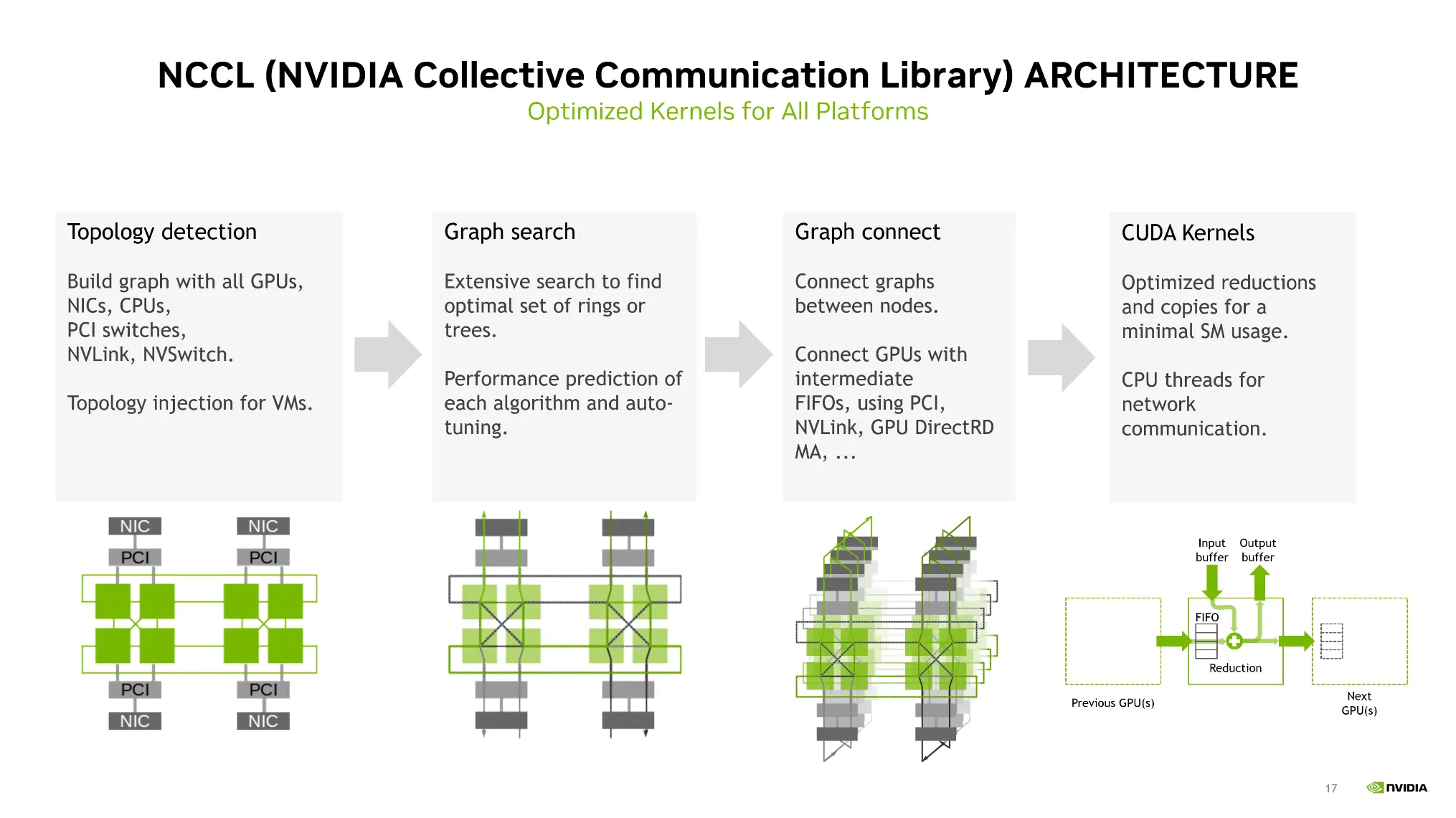
1.
Topology Detection: 하드웨어의 구성이나 연결성을 탐색하여 Topology를 구성한다.
2.
Graph Search: 어떤 통신량이 적고 효율적인지 탐색한다.
3.
Graph Connect
4.
CUDA Kernels
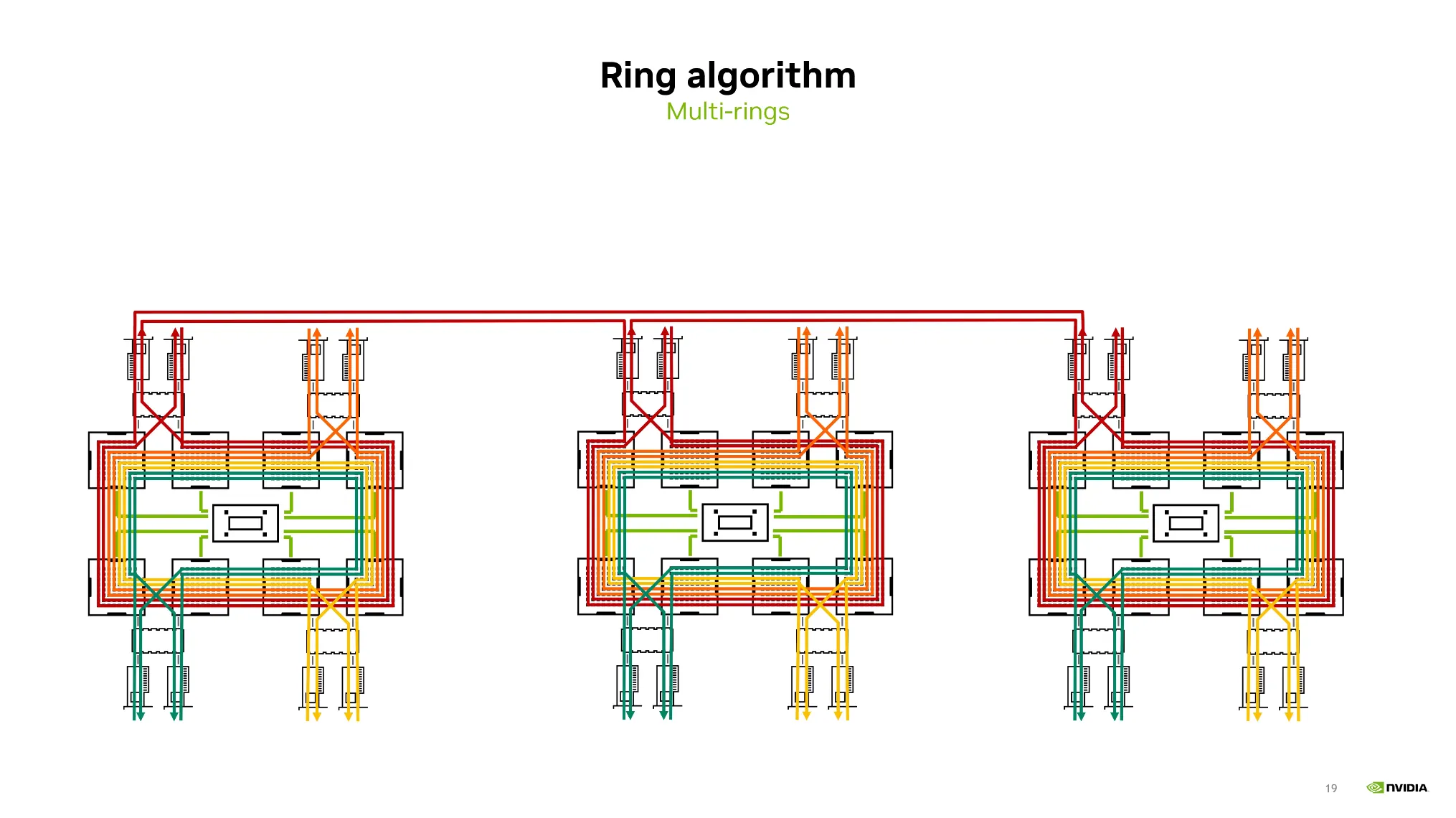
•
링 알고리즘을 기반으로 multi-ring을 구축한 후 Node간 통신을 구축한다.
•
사실 개발자는 코드 한줄로 해결이 되지만 개념은 이해하는 것이 필요하다.
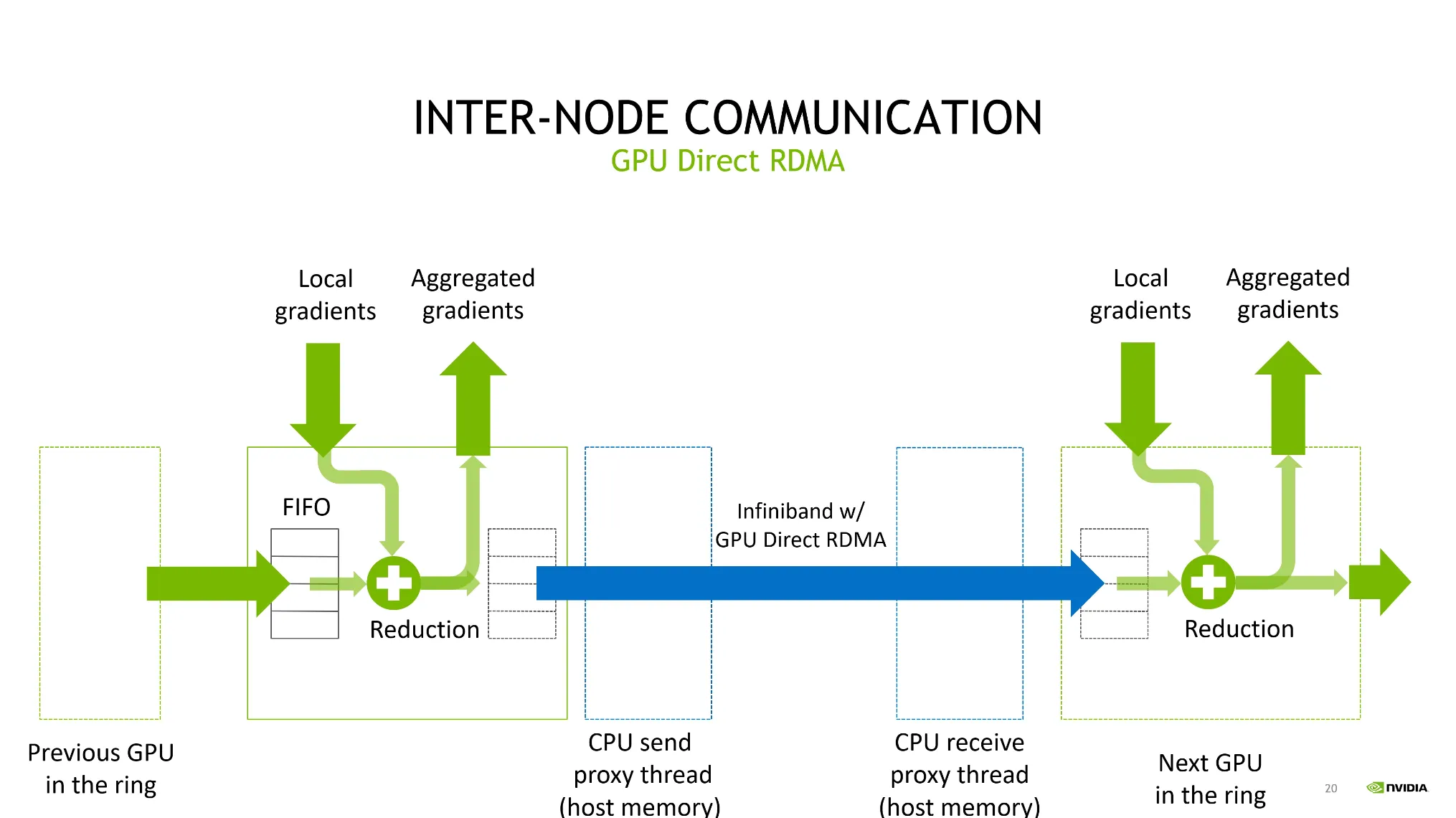
•
NCCL을 사용하면 GPU Direct RDMA 기술을 자동적으로 사용할 수 있다.
Distributed Processing in Deep Learning
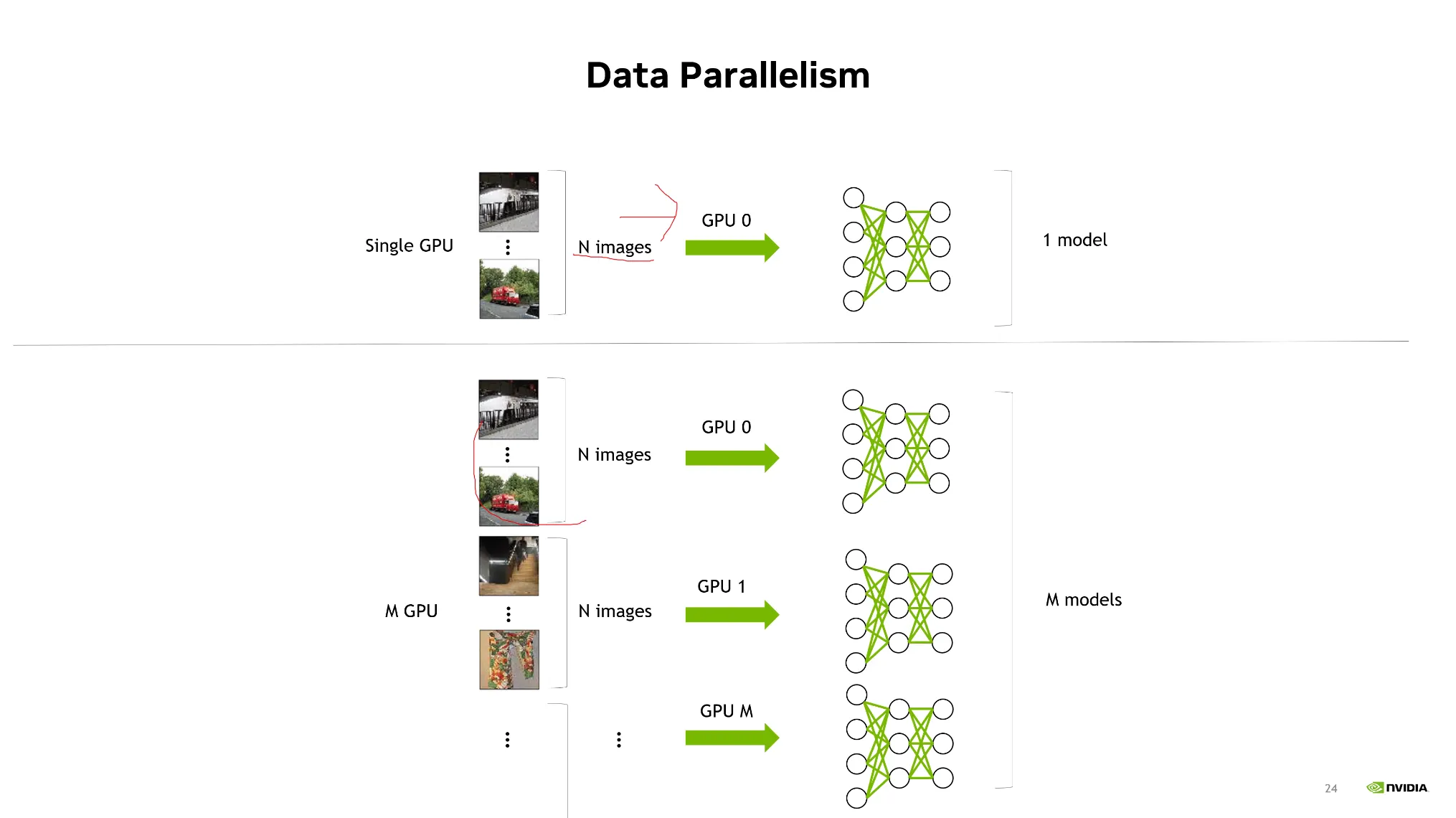
Data Parallelism
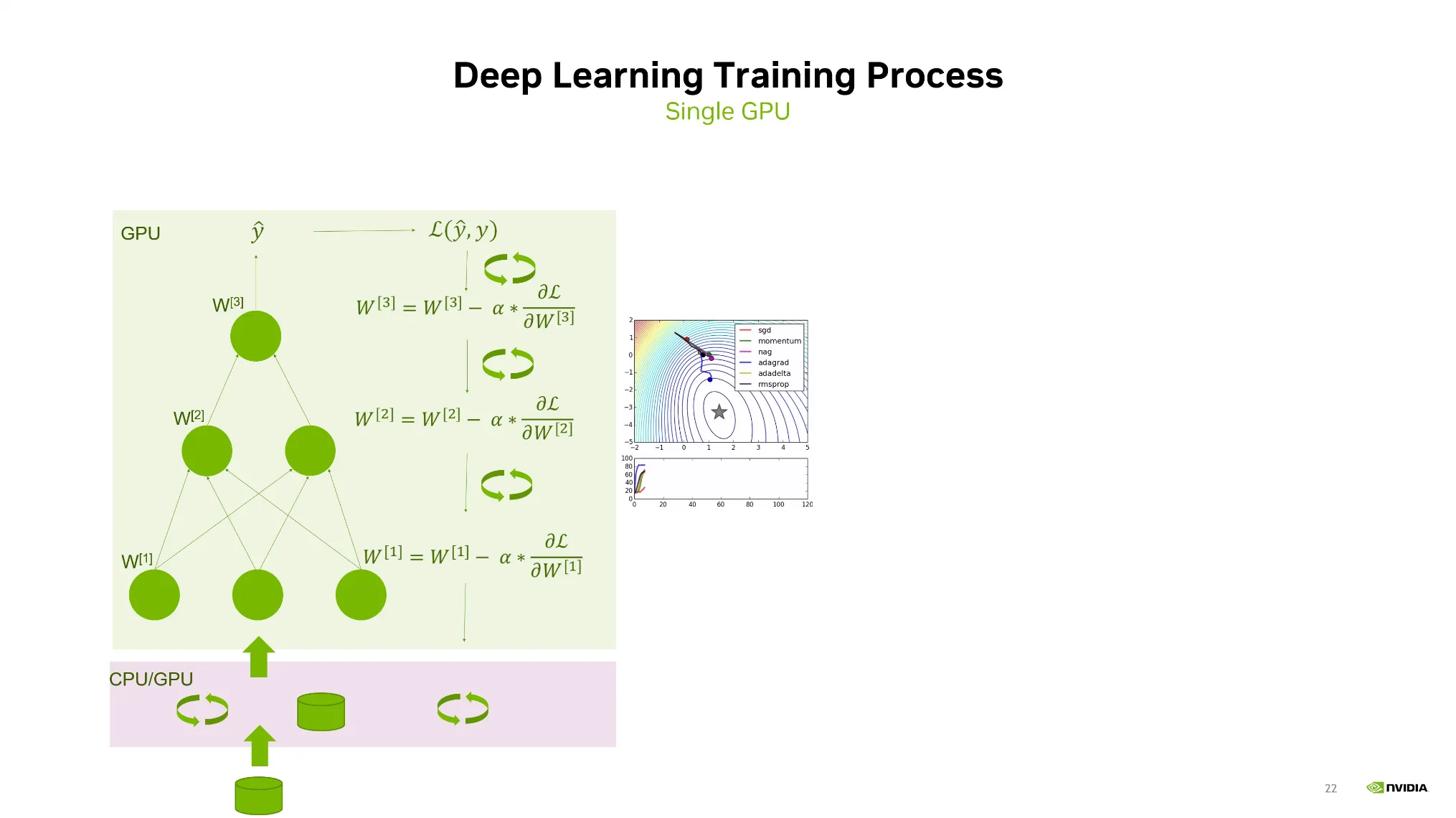
•
딥러닝의 학습은 Forward pass, loss computation, gradiant back propagation 과정을 거치며 이는 single GPU를 기반으로 구축되어있다.
•
Data Parallelism의 개념은 하나의 GPU로부터 여러개 GPU로 쪼개서 동시에 학습을 진행하는 것.
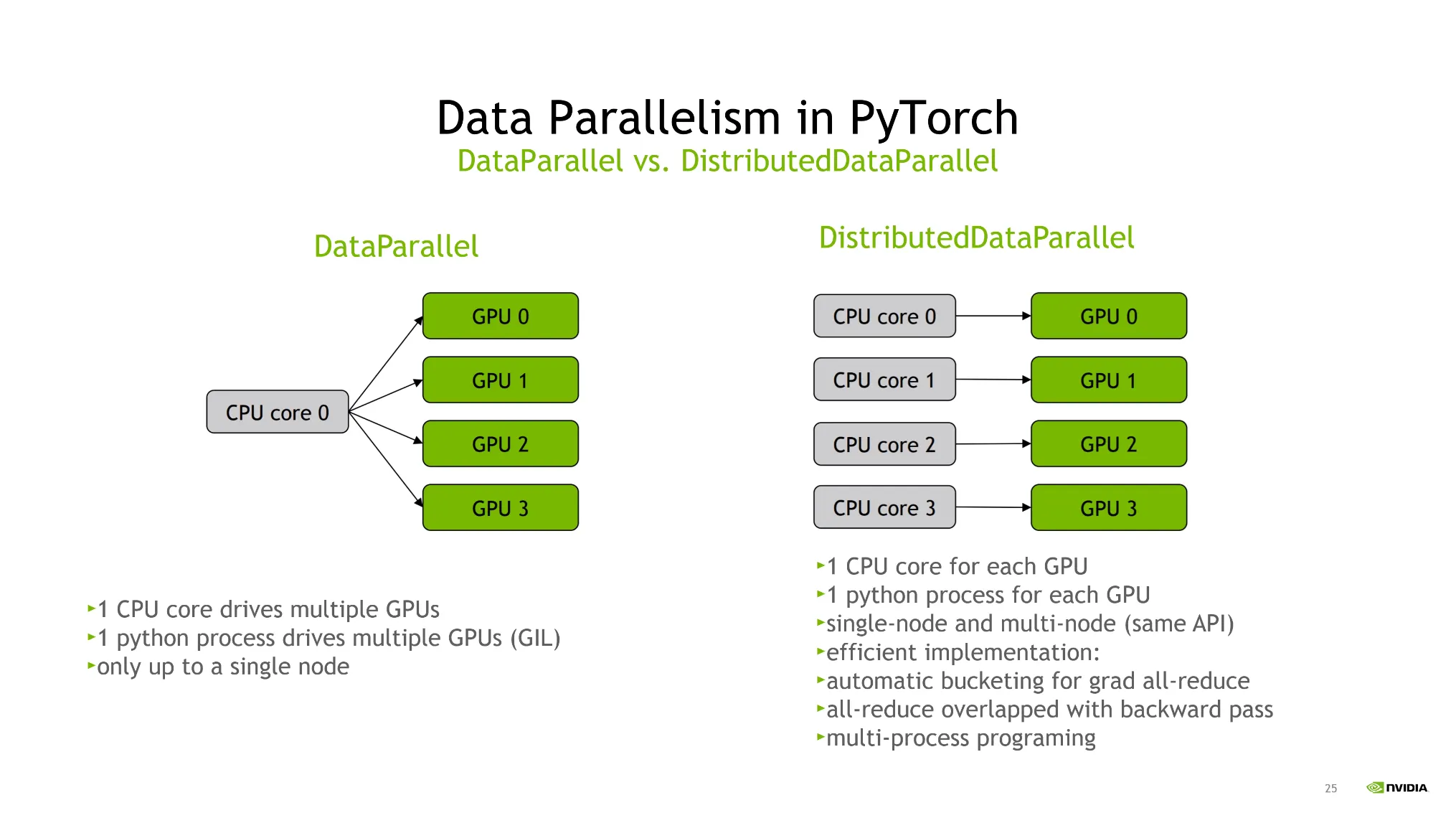
Pytorch에서 어떻게 구축되어있는가?
1.
DataParallel
•
CPU 코어 하나만 사용해서 여러개의 GPU를 처리한다.
2.
DistributedDataParallel
•
하나의 process에 하나의 GPU가 연결되어 병렬처리가 가능함.
이 때, 학습 패러다임이 완전히 달라지게 된다.
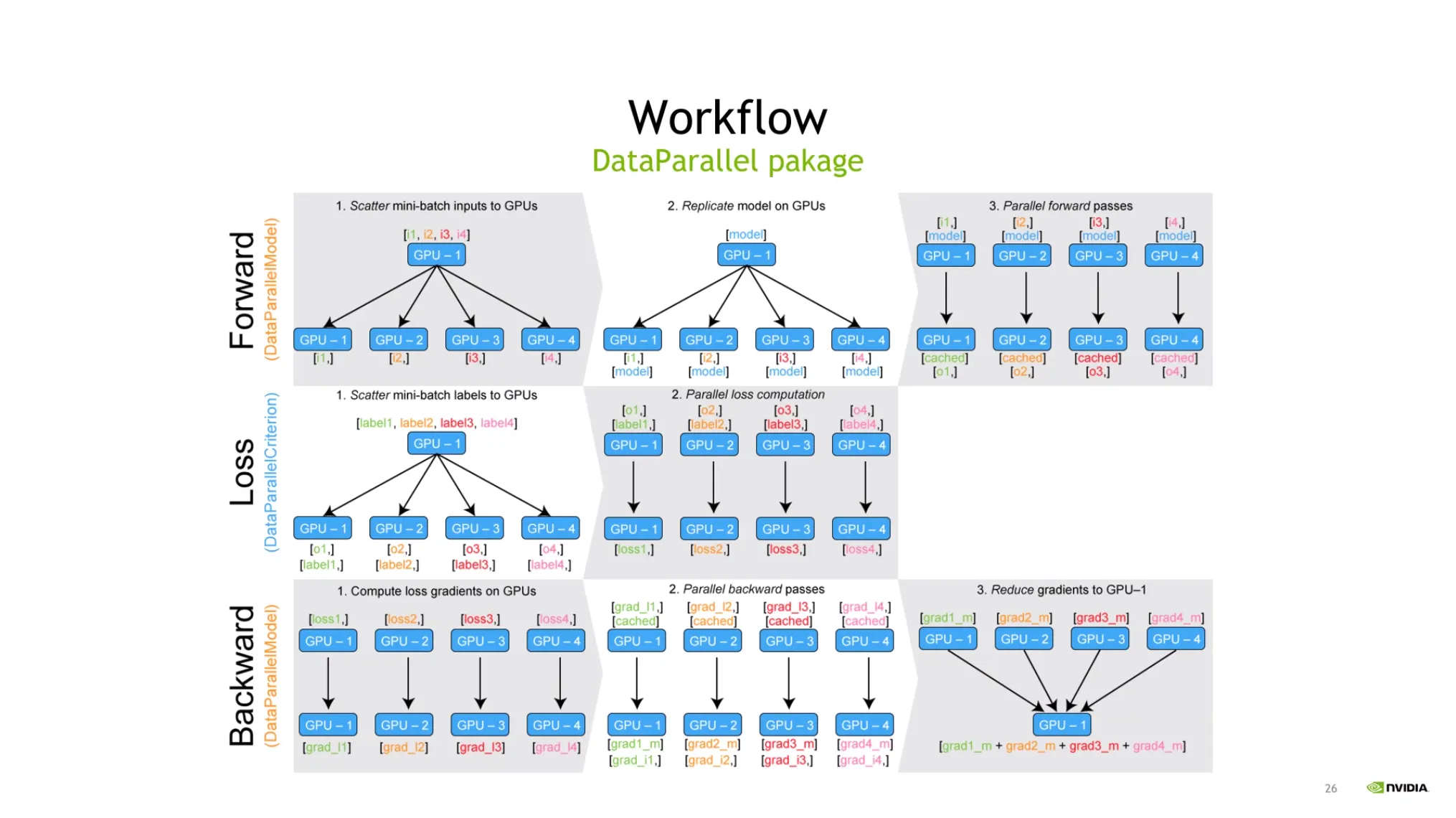
DataParallel Workflow:
•
각 GPU에 데이터를 쪼개고, 모델을 복제하고, loss와 gradiant를 계산 후 gradiant를 accumulation 시켜서 weight를 업데이트한다.
•
이때, 매 iteration마다 모델을 복제한다.
◦
모델사이즈가 적으면 이 과정이 어렵지 않다.
◦
하지만 모델사이즈가 커지면 매우 부담이 되는 과정이다.
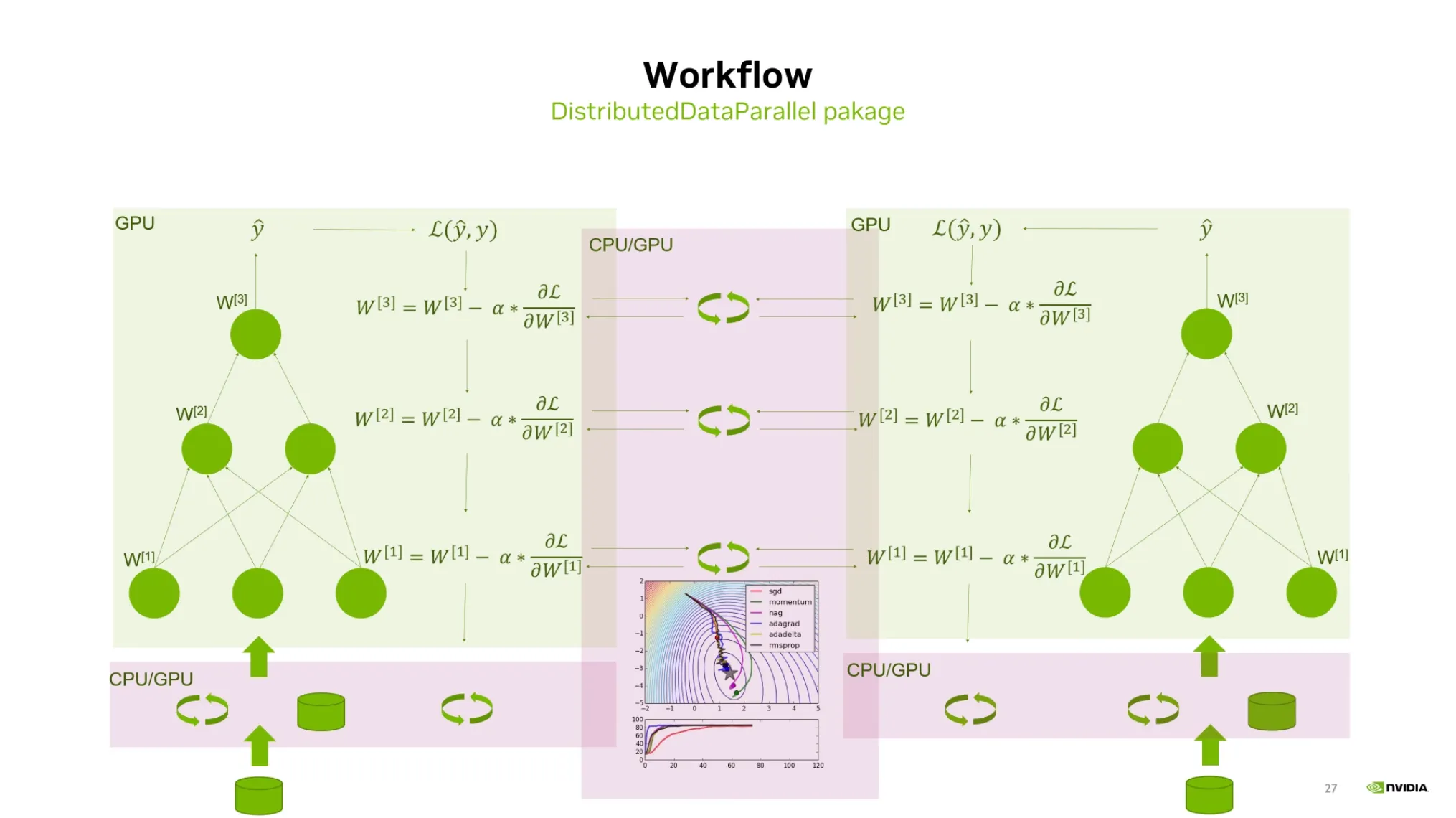
DistributedDataParallel Workflow:
•
모델을 복제하지 않고, 각 GPU에 모델을 가지고 있다.
•
이 때, 똑같은 모델을 업데이트하기 위해 gradient를 동기화시켜주는 작업이 필요하다.
•
DDP는 Backward 작업을 하면서 매번 gradient sync를 하게 된다.
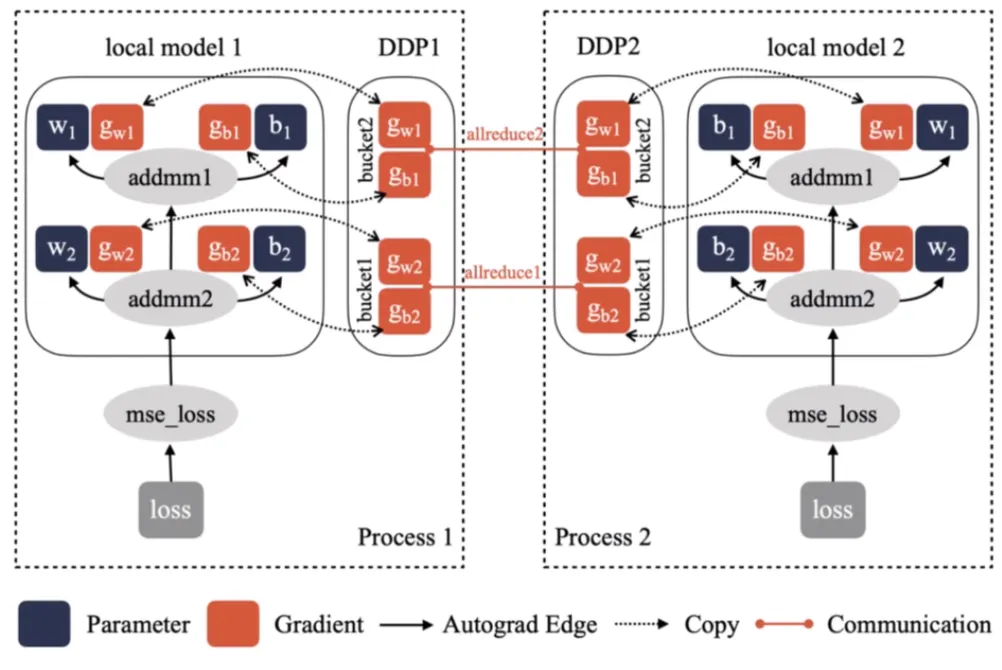
•
이때, Pytorch는 이를 효율적으로 수행하기 위해 효율적인 로직을 가지고 있다.
•
예를 들면 AllReduce가 비효율적이기 때문에 이를 개선하는 알고리즘 등이 있다.
Model Parallelism
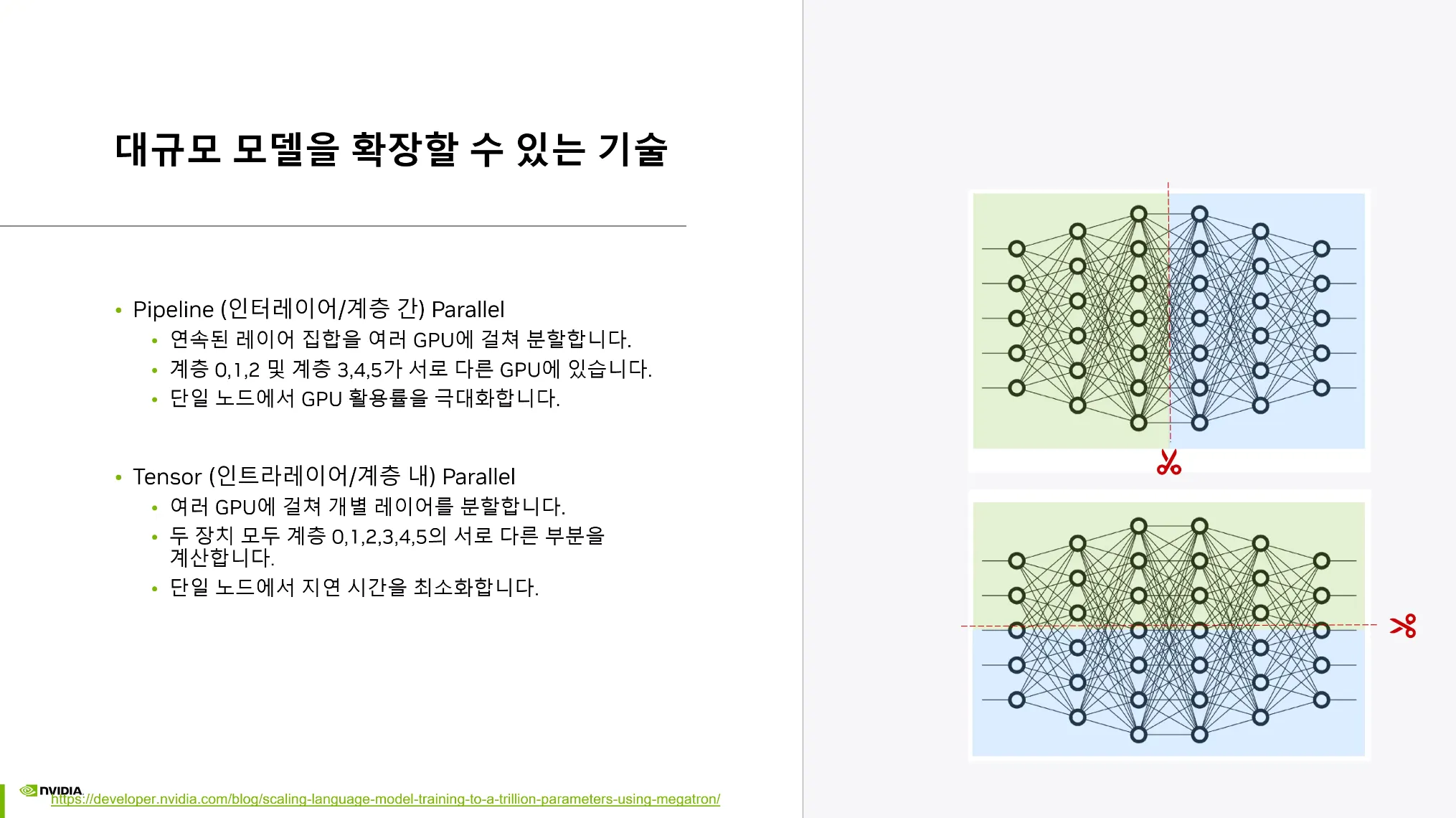
•
GPU메모리에 올라가지 않는 큰 모델을 쪼개서 학습을 시키는 기술
1.
Pipeline Parallel: 파이프라인을 쪼개는 것
2.
Tensor Parallel: 매트릭스를 쪼개는 것
Tensor Parallel
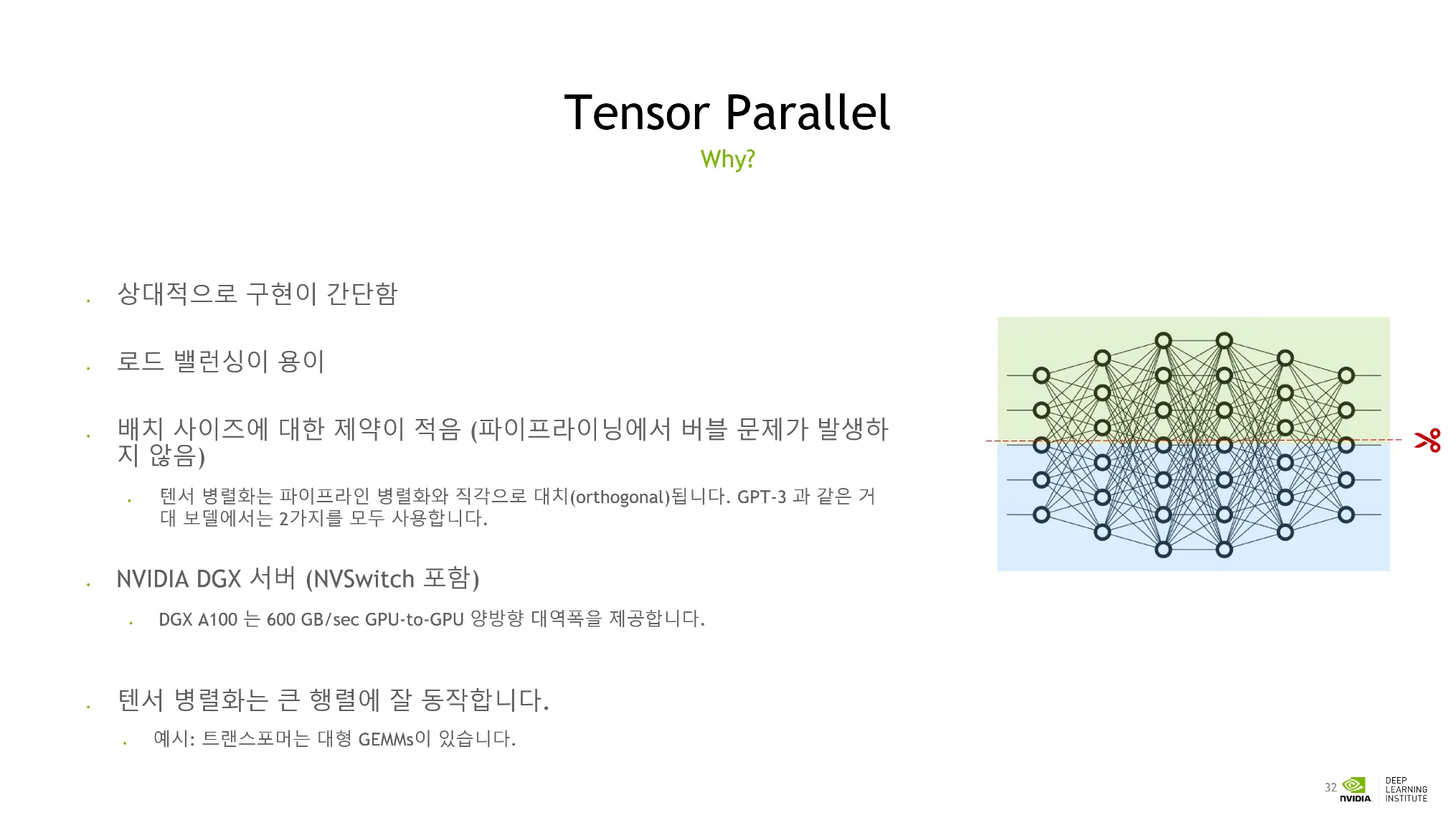

•
Communication Burdon이 크므로 하드웨어 제약을 생각해야 한다.
•
텐서를 너무 작게 분할하면 효과적인 학습이 안된다.
•
Intensity Metric을 고려하여 GPU리소스를 충분히 활용하는지 확인해야 한다.
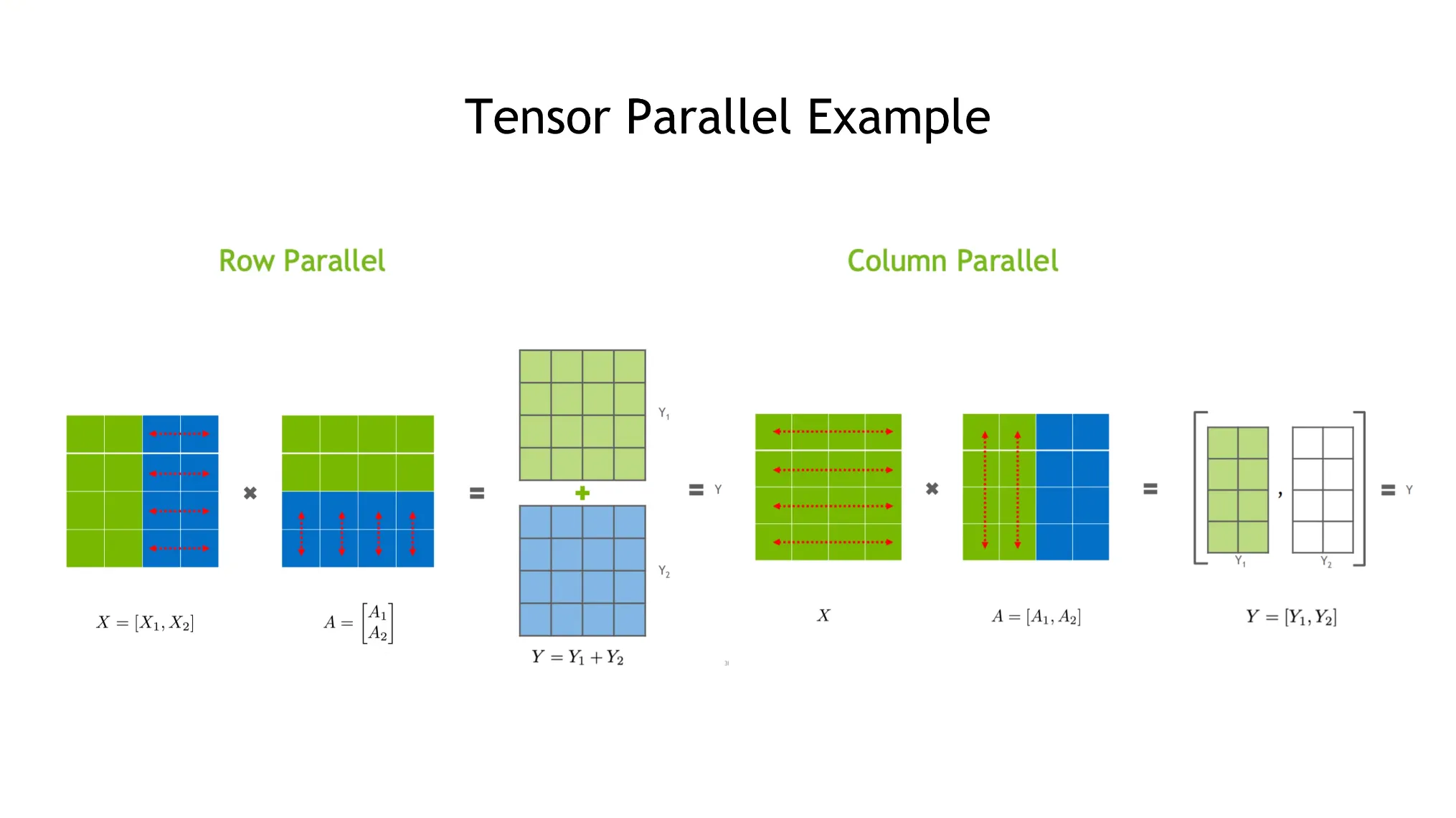
•
두가지 종류가 있다. 하나는 가로로 쪼개고, 다른 하나는 세로로 쪼개는 것.
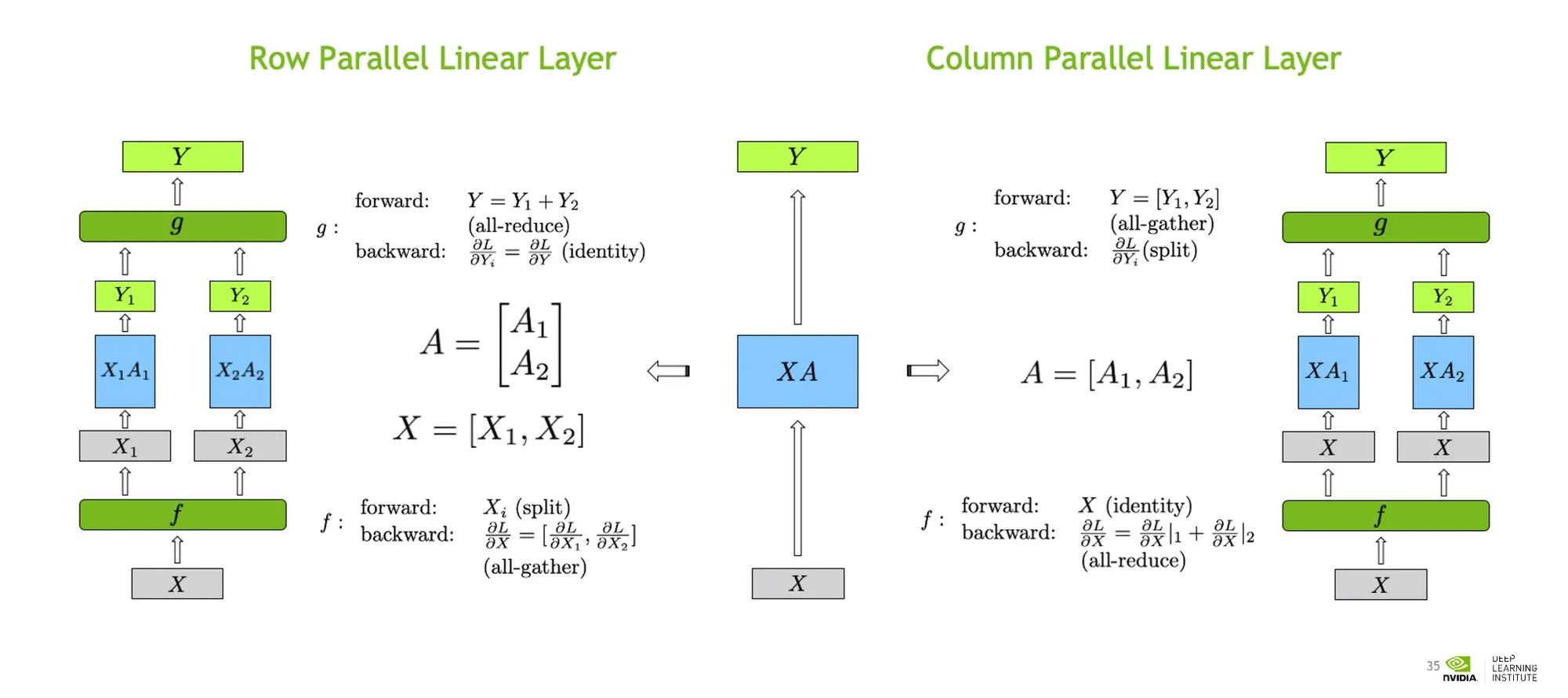
•
Transformers등에도 적용되어있는데, Communication burdon이 있다.
•
Input X와 Weight A가 있다면,
◦
forward 연산은 split으로 나누어준 후 마지막에 allgather 연산으로 합쳐준다.
◦
backward 연산은 identity와 allgather 연산을 해준다.
◦
이 두 연산은 communitive 하다.
•
이런 내용들이 LLM Model Framework 내부에서 자동적으로 적용되도록 잘 구축되어있다.
Pipeline Parallel
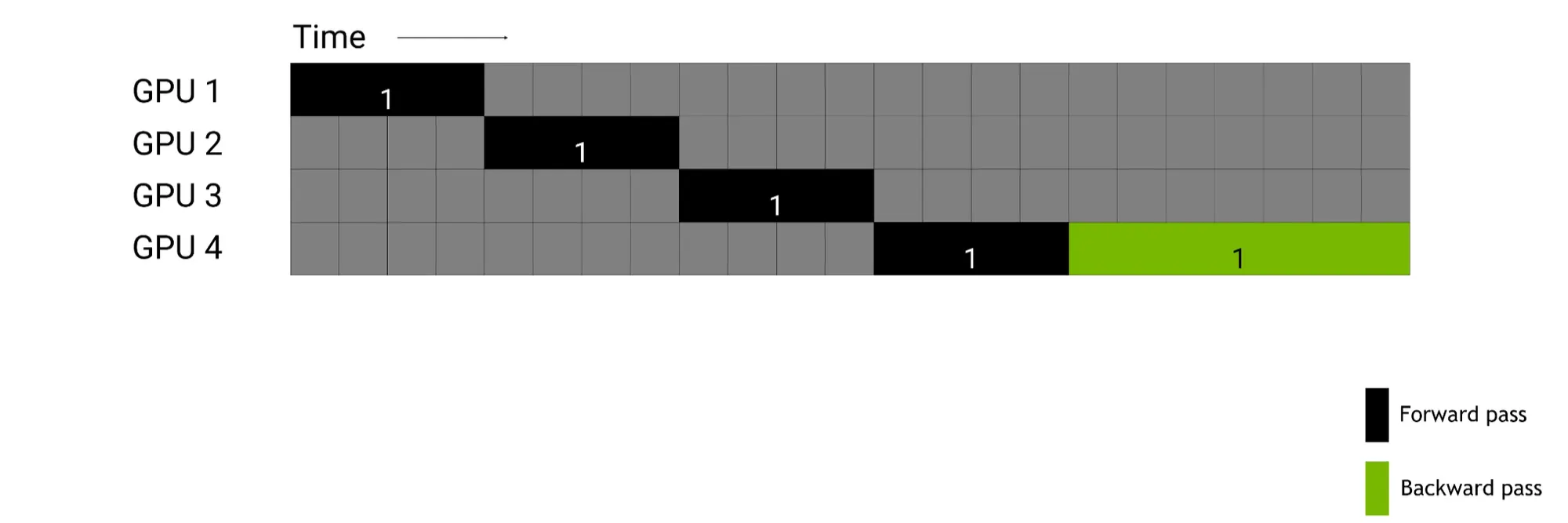
•
파이프라인을 n개로 나누어주면, 이 n개의 파이프라인은 sequential하게 연산이 된다.
•
이 경우, GPU가 쉬는 구간이 많아진다. (GPU idle time)
•
이를 해결하기 위해 micro batch로 나누어 GPU idle time을 최소화시킬 수 있다.
예를 들어보자.
첫번째 batch (1a)에 대한 Forward pass와 backward pass는 다음과 같이 나타낼 수 있다.

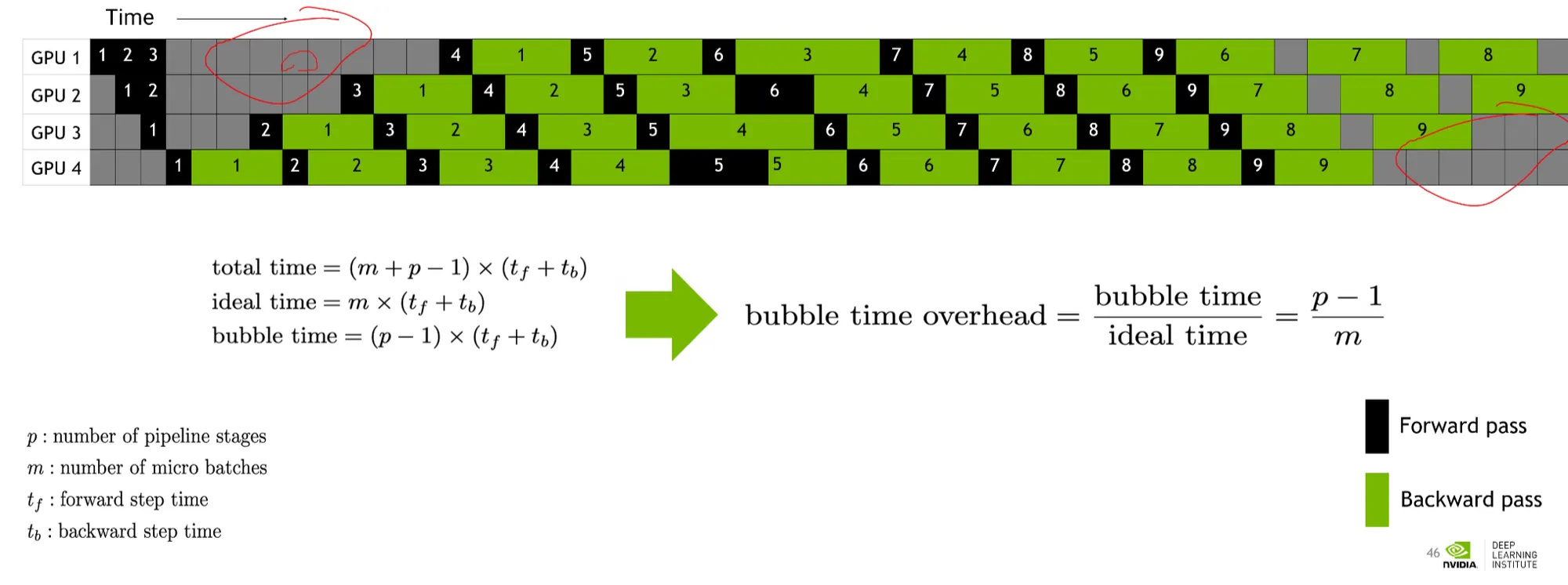
유휴시간을 줄이기 위해, 두번째 micro batch (2b)를 다음과 같이 연산한다.

n개의 micro batch에 대해서 다음과 같이 연산할 수 있다.



이런 방법들을 통해 bubble time을 줄이는 알고리즘이 내장되어있다.
Hybrid Parallelism
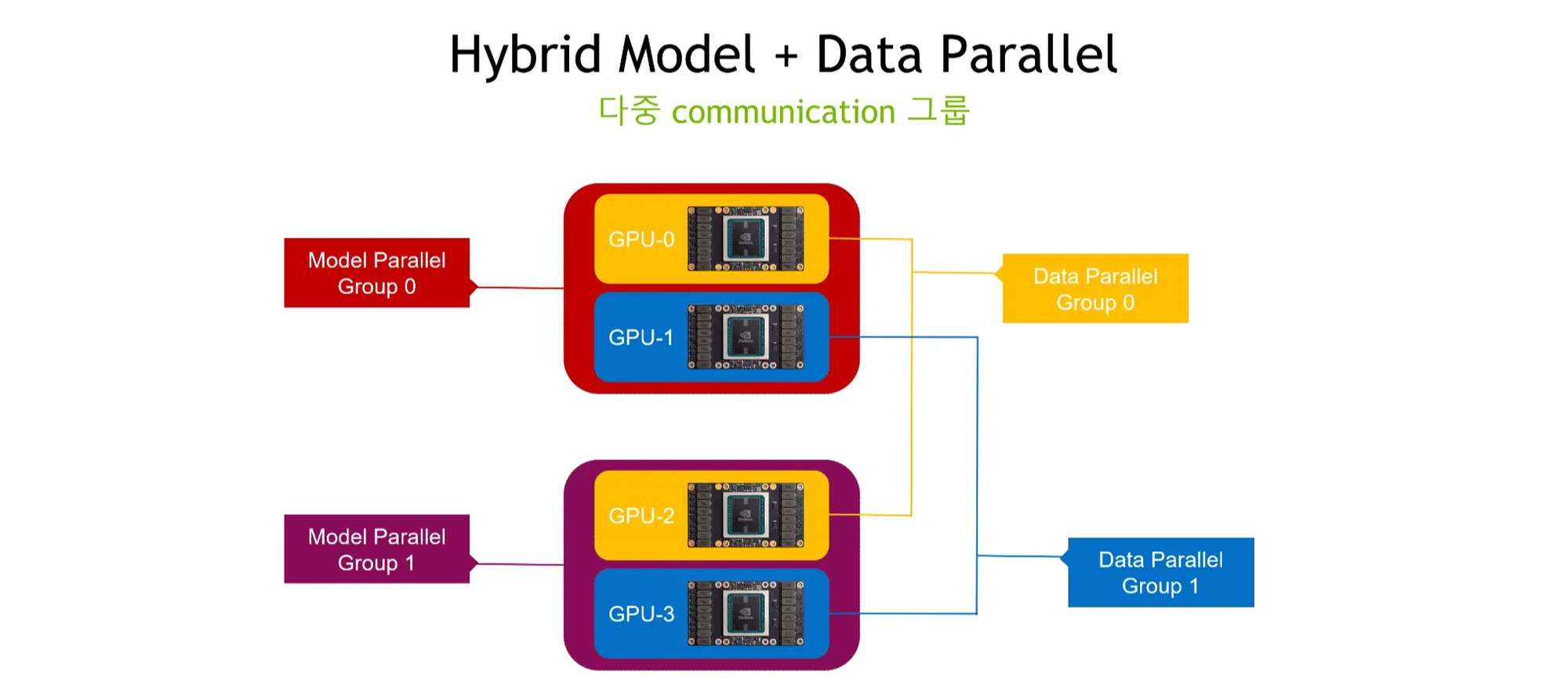
•
node와 rank를 그룹으로 나누어 데이터 및 모델을 병렬화한다.
Distributed Training

분산학습을 하기 위한 Parameters
•
--nproc_per_node: 노드당 GPU 개수
•
--nnodes: 전체 노드의 개수
•
--node_rank: 노드의 글로벌 랭크
•
—master_addr / —master_port: master address의 port정보가
분산학습을 위한 환경 변수

•
Global Rank와 Local Rank를 구분할 필요성이 있다.
예시


QnA
•
모델사이즈가 커서 batch size = 2~4로 작게 설정하는 경우, Model/Pipeline parallel을 사용하는 것이 좋을까?
◦
No. 하나의 GPU에 올라간다면 그냥 쓰는것이 가장 좋다.
◦
gradient accumulation을 활용하자.
•
pytorch lightning과 같은 wrapper를 사용하면 DDP시 성능이 저하될까?
◦
No. 성능저하 없다. 편하게 사용하자.