


AICA X NVIDIA Cluster GPU 교육 시리즈
5. 프로그램 병목개선을 위한 GPU 프로파일링 활용
홍광수 박사 (솔루션 아키텍트, NVIDIA))
NVIDIA x AICA Cluster GPU 활용 캠프 (2024/08/26 - 09/05)
GPU Monitoring tools


•
GPU Utilization: 하나의 커널이 샘플링 시간동안 얼마나 차지했는지에 대한 비율.
•
Memory Utilization: 메모리를 읽거나 쓴 비율.
•
따라서 실제 사용률과 괴리가 있다.

•
Utilization 뿐 만 아니라 다른 metric을 함께 봐야 정확히 알 수 있다.

•
그래픽을 디버깅하고 프로파일링하는 툴들
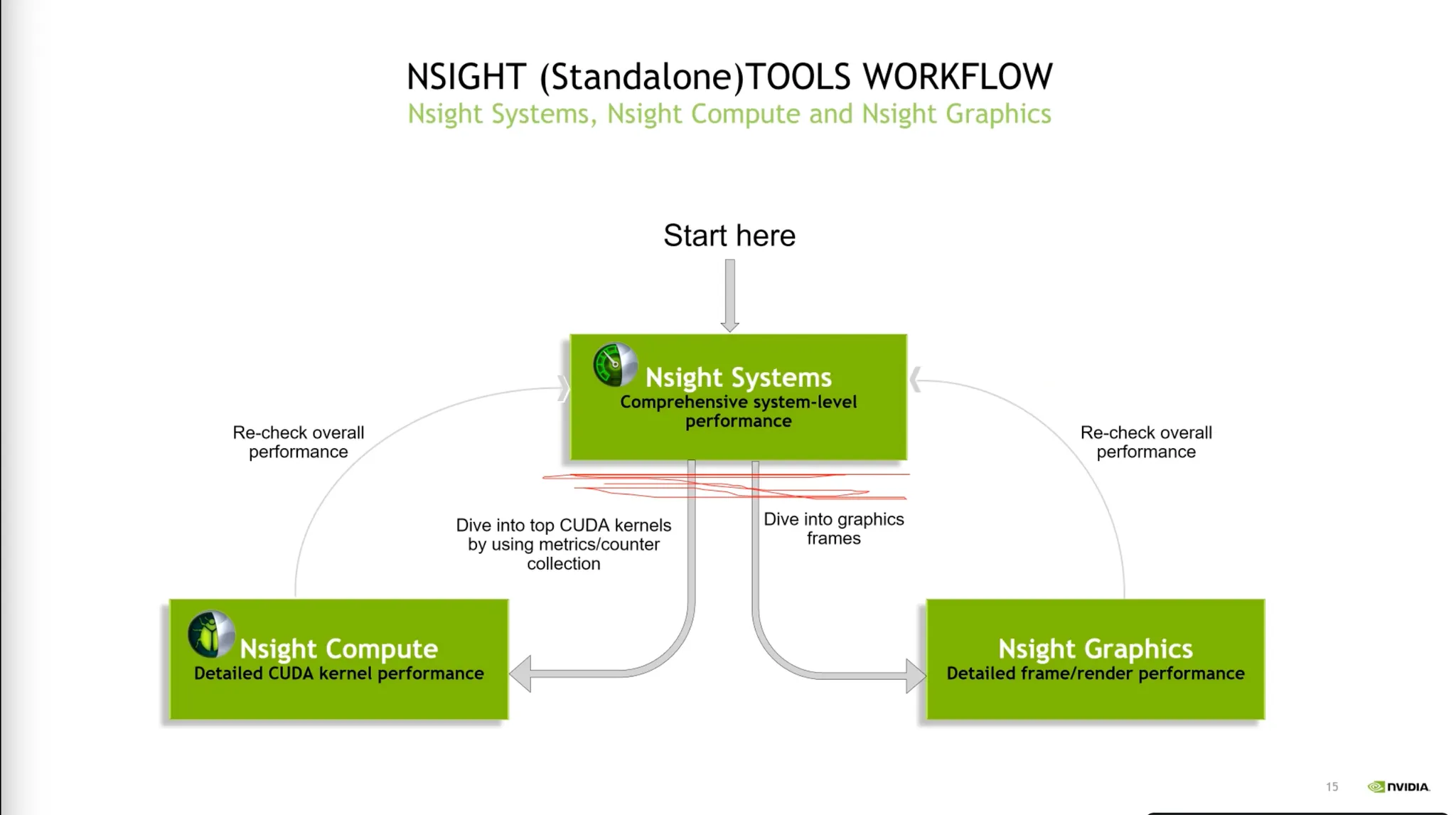
•
Nsight Systems : Bottleneck point를 찾는다.
•
Nisight Compute: 더 딥다이브한 바틀넥을 찾는다.
•
Nsight Graphics: 그래픽스 프레임워크에 사용할 때
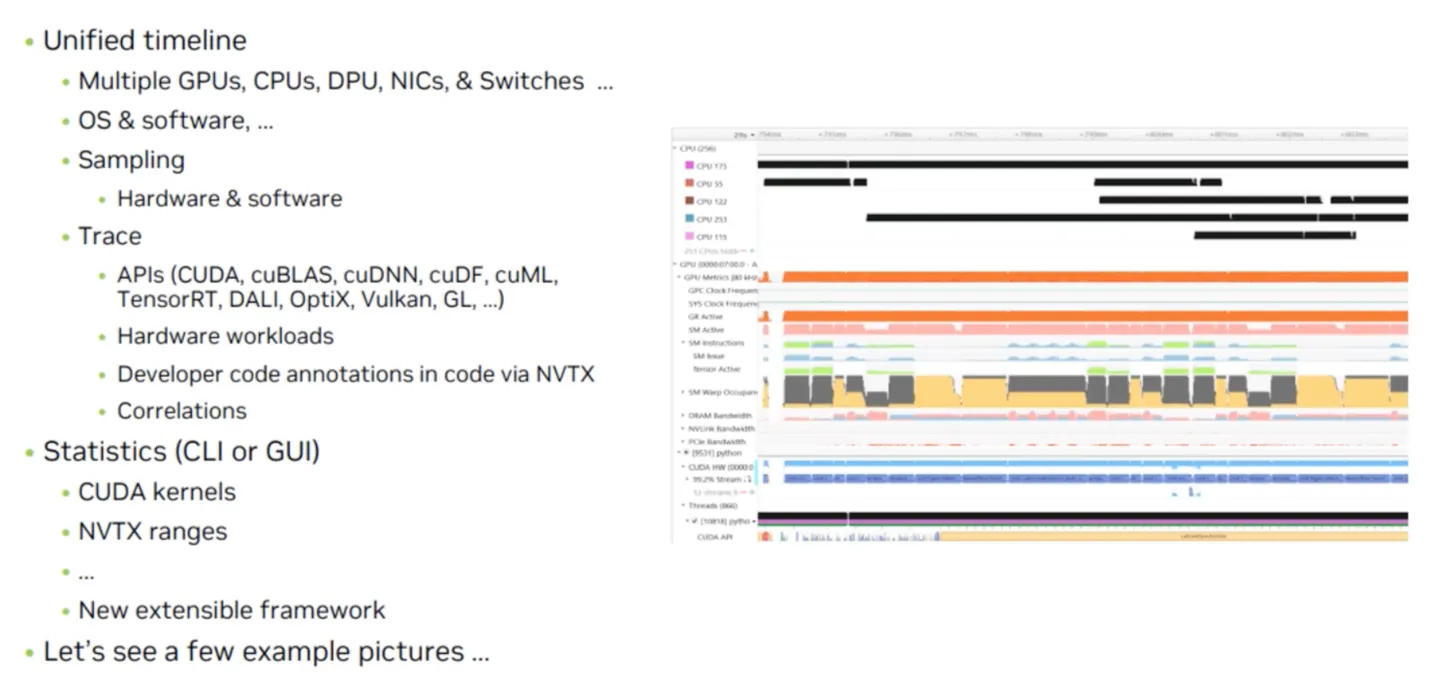
•
Nsight에 표시되는 metric들.
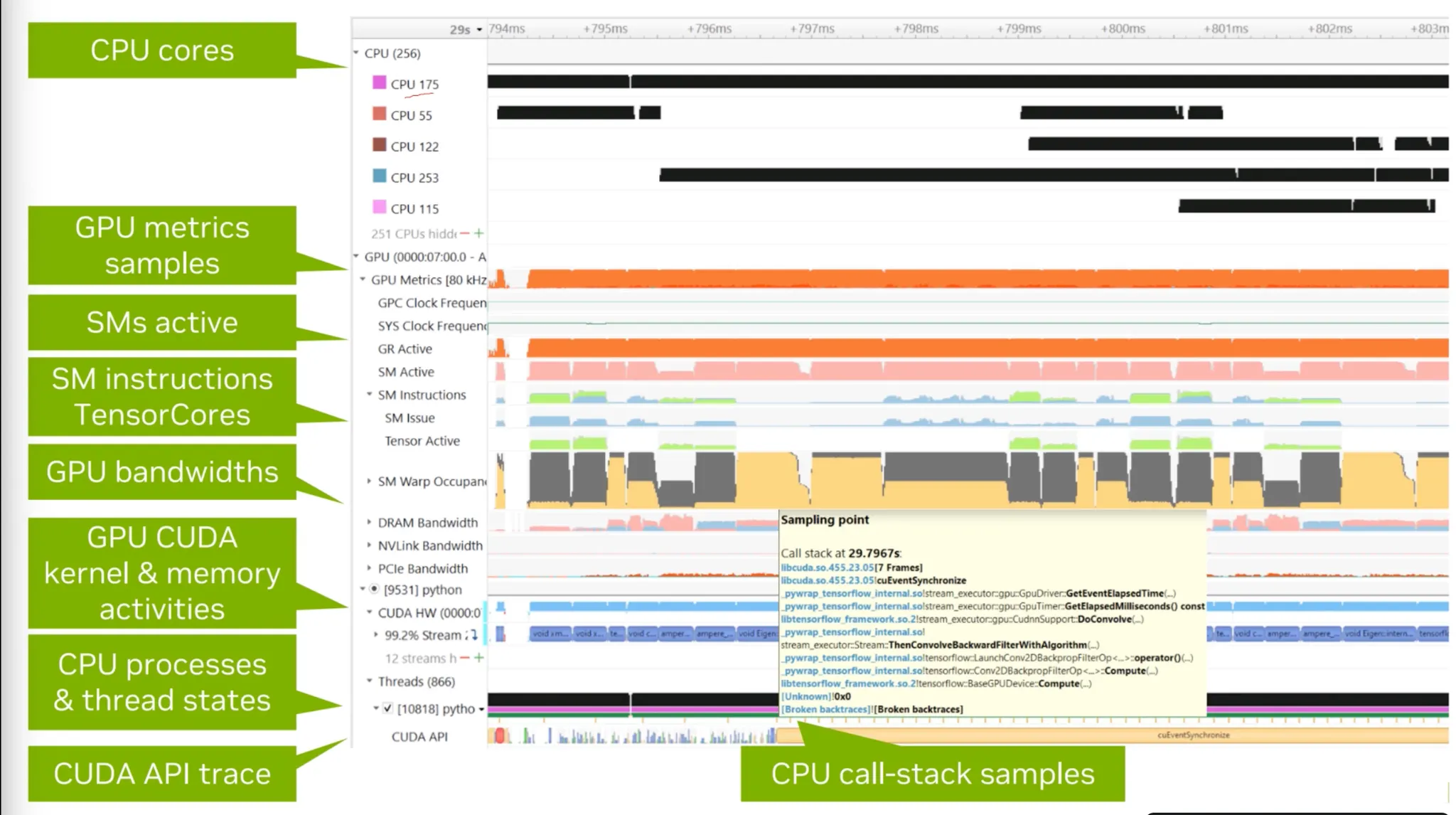
•
Nsight 화면 구성.
•
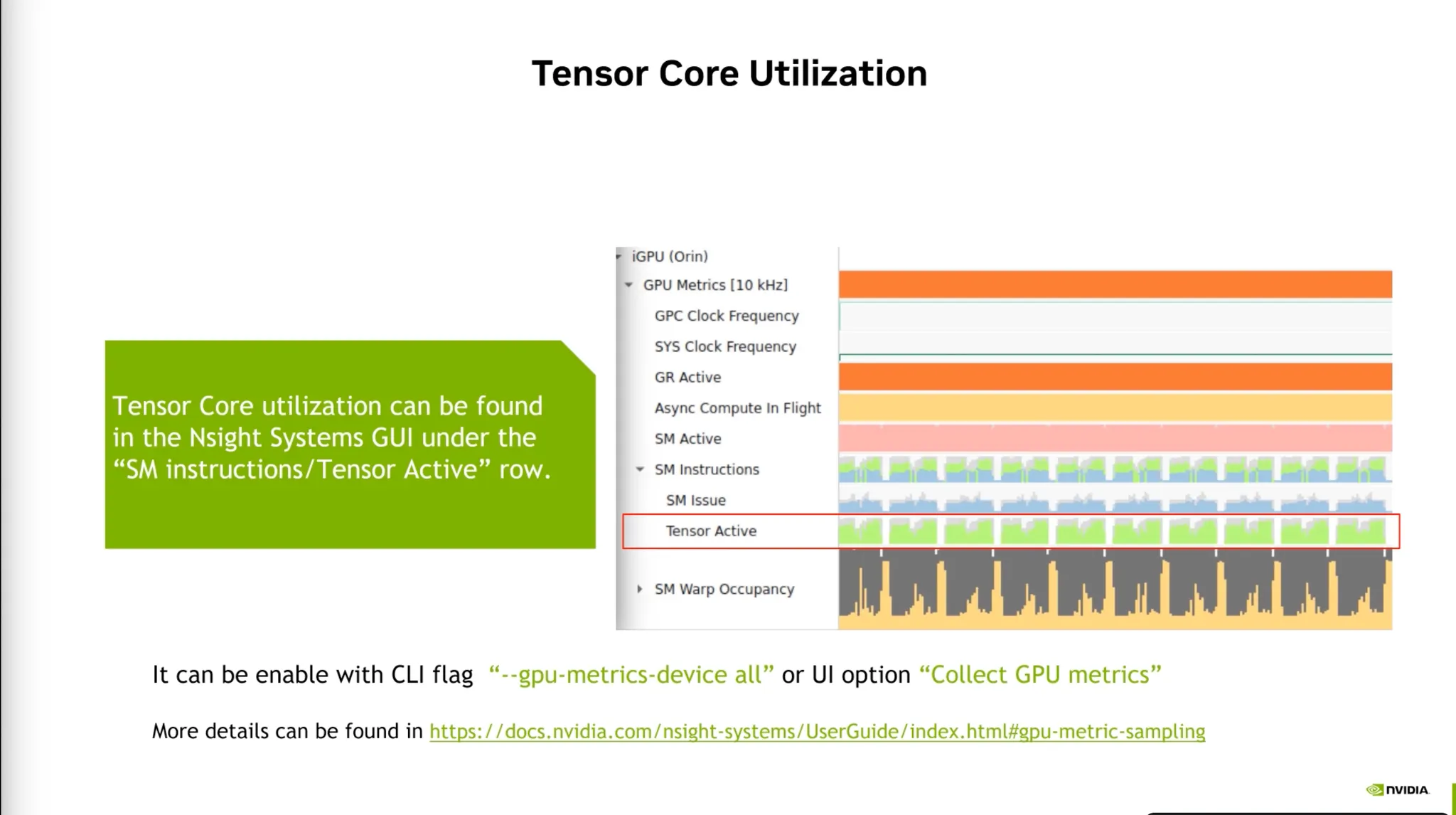
GPU Utilization 뿐 아니라 SM, TensorCores Activity를 표시해준다.
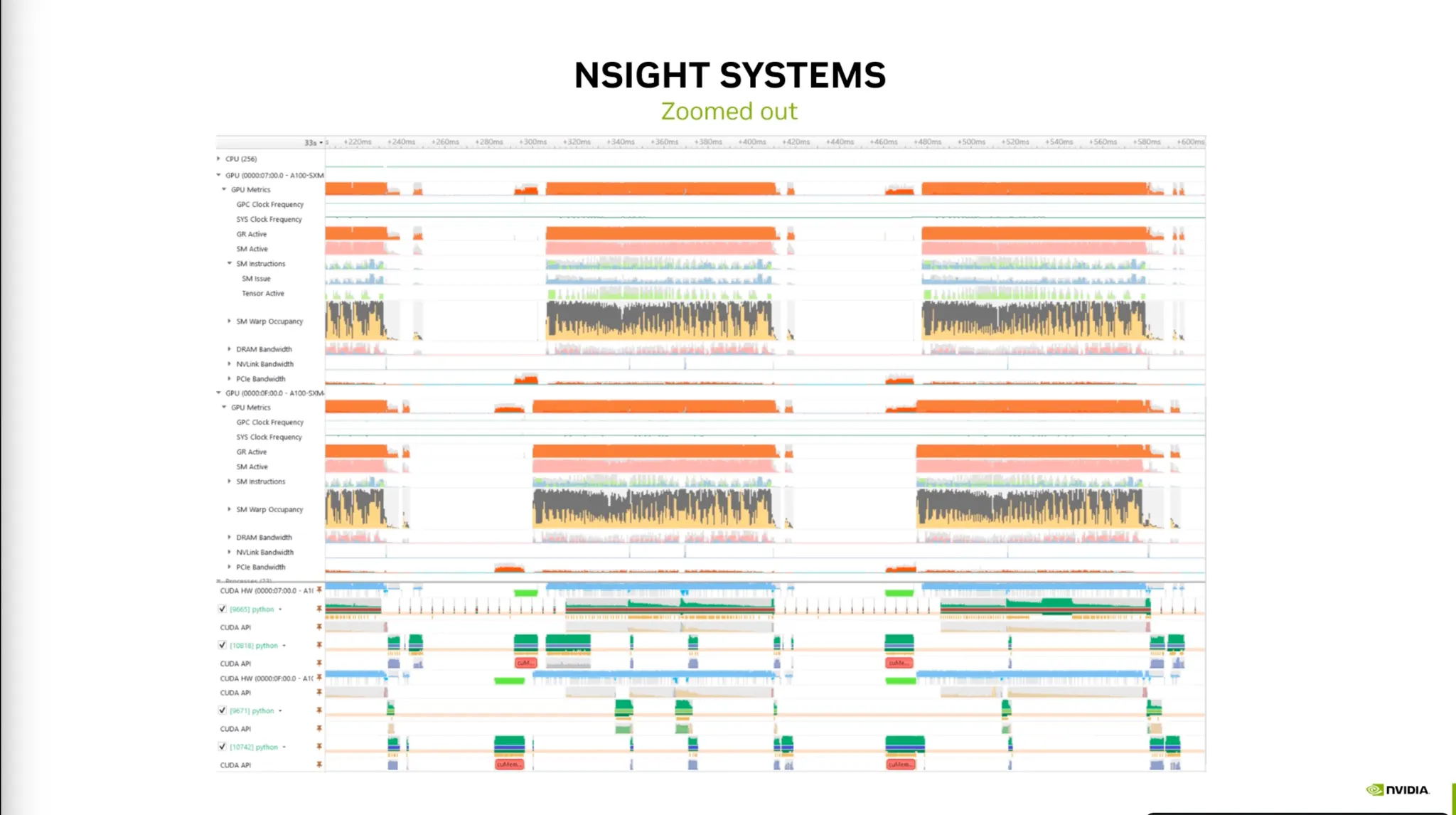
•
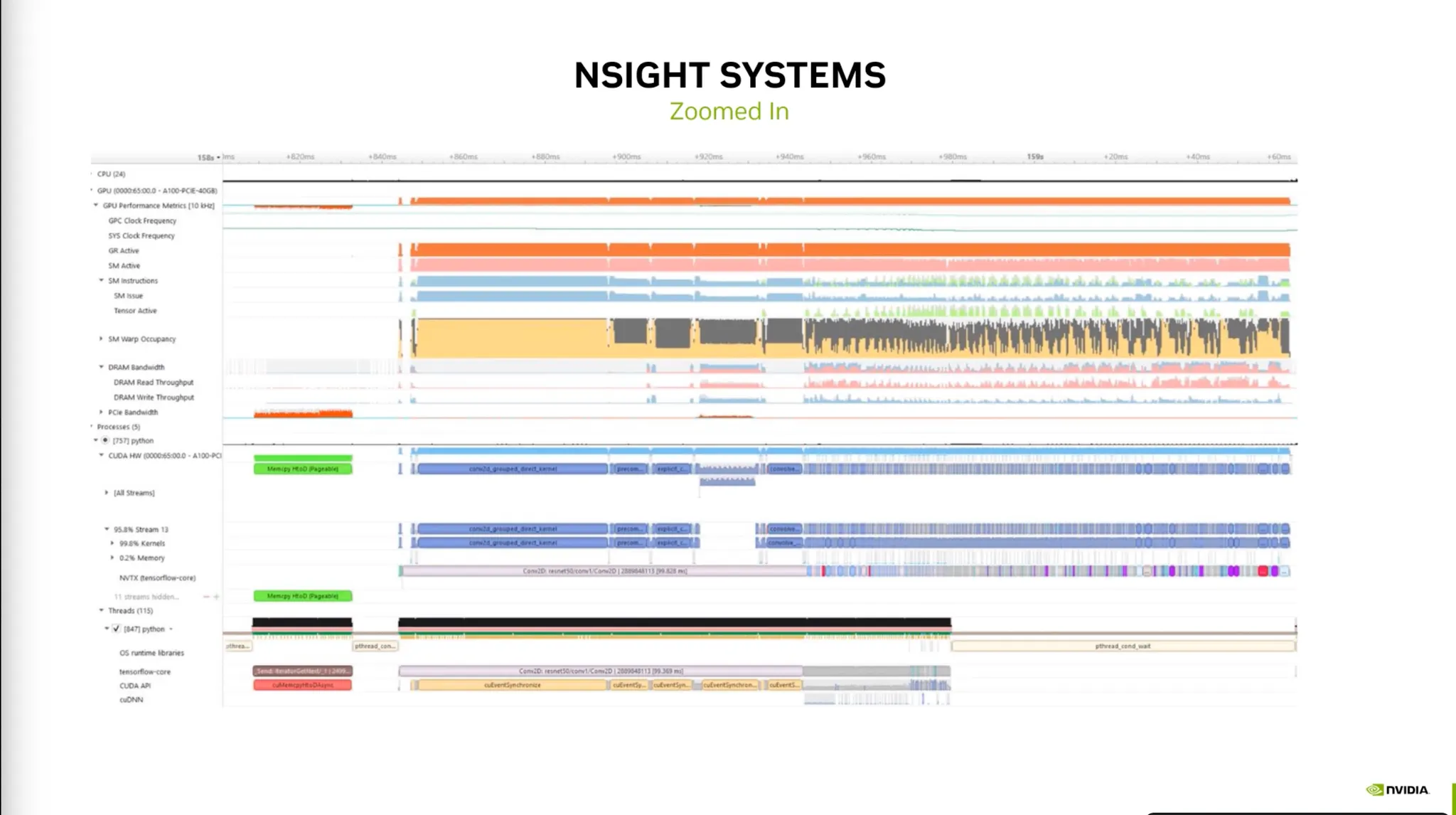
Zoom Out, Zoom in에 따른 레이아웃.
•
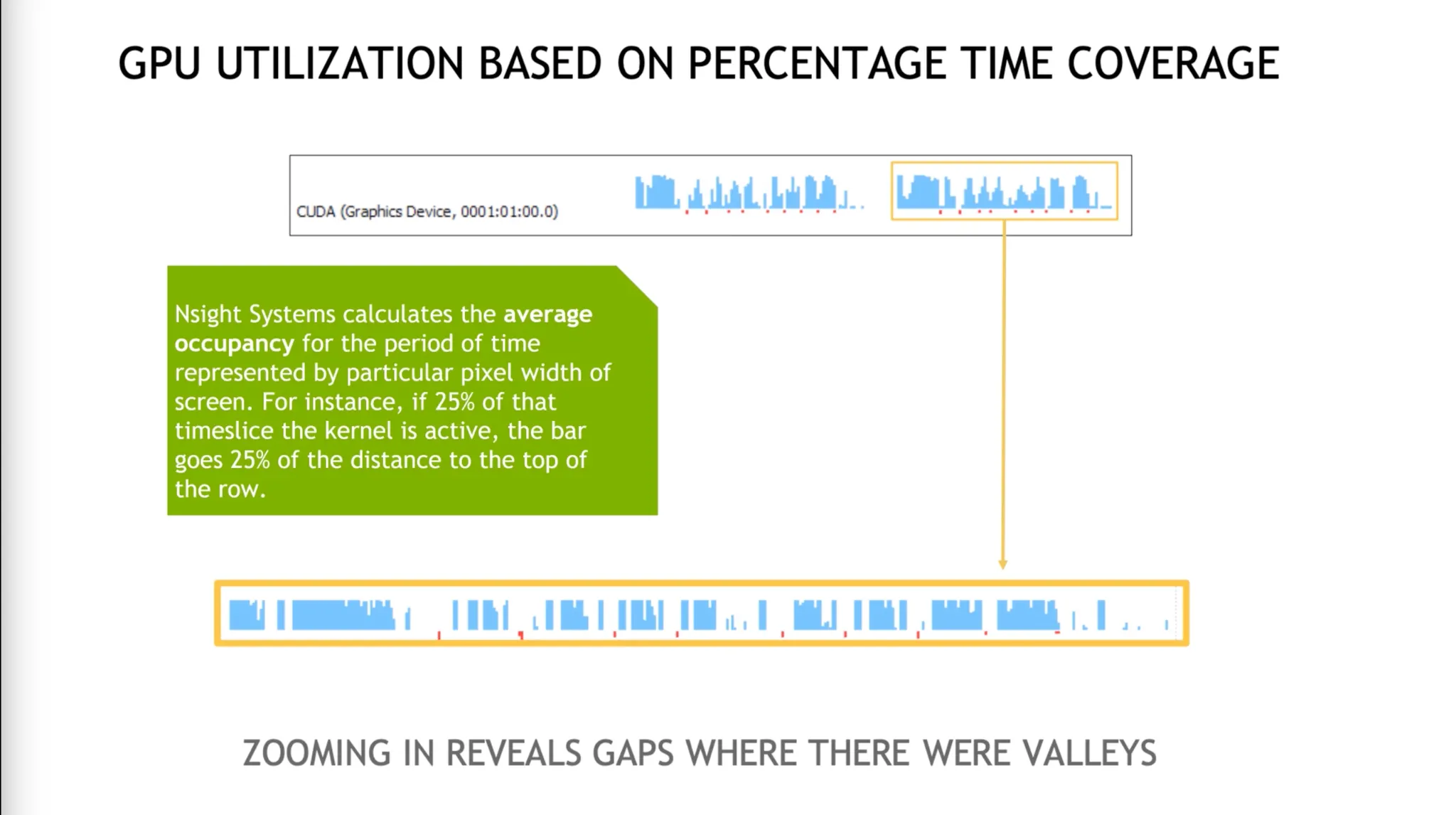
Utilization Metric은 평균값들을 막대지표로 보여준다.
•
가장 중요한 것은 TensorCore Activity가 중요하다.
Profiling with Nsight
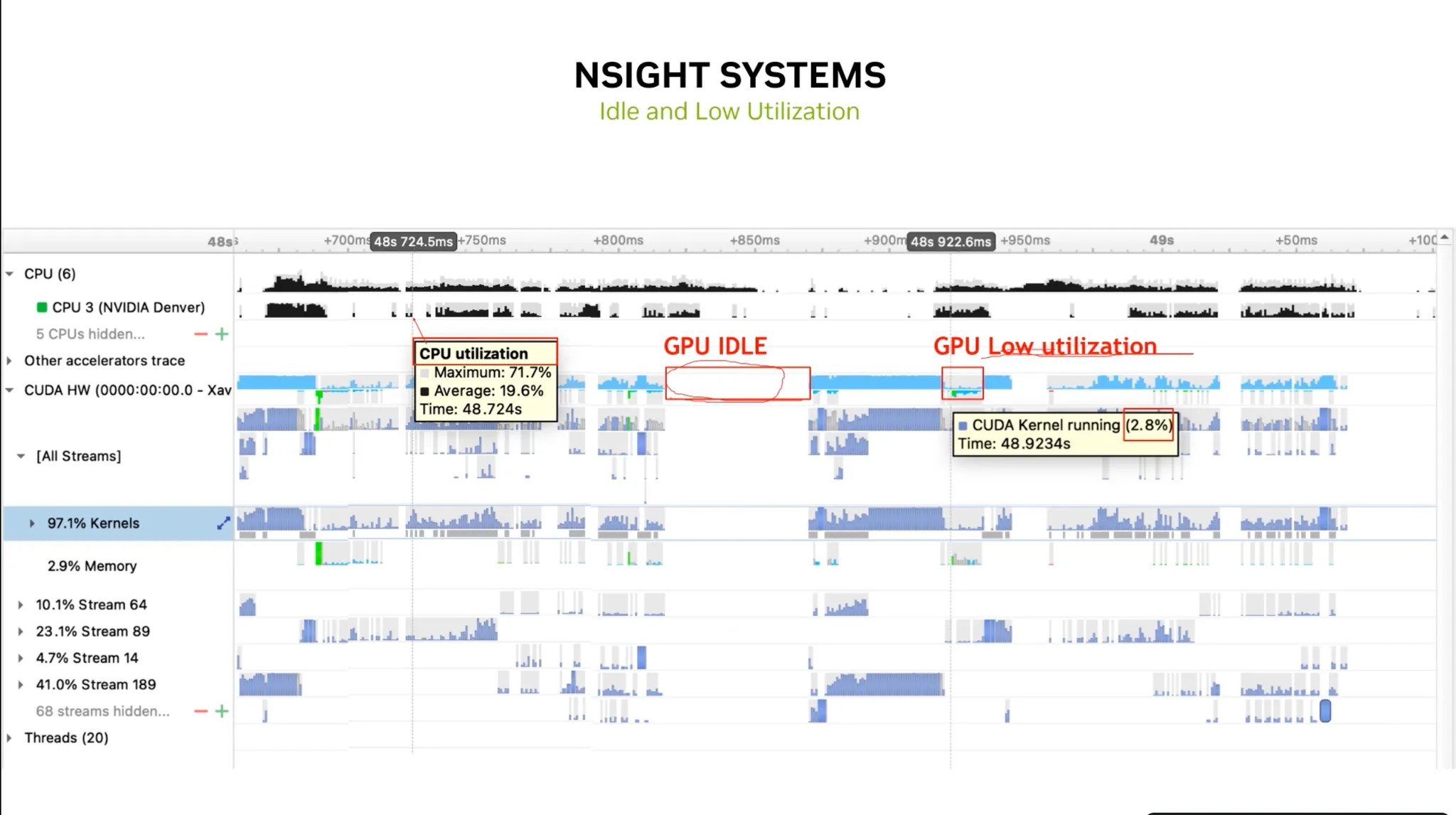
•
CPU Utilization 확인
•
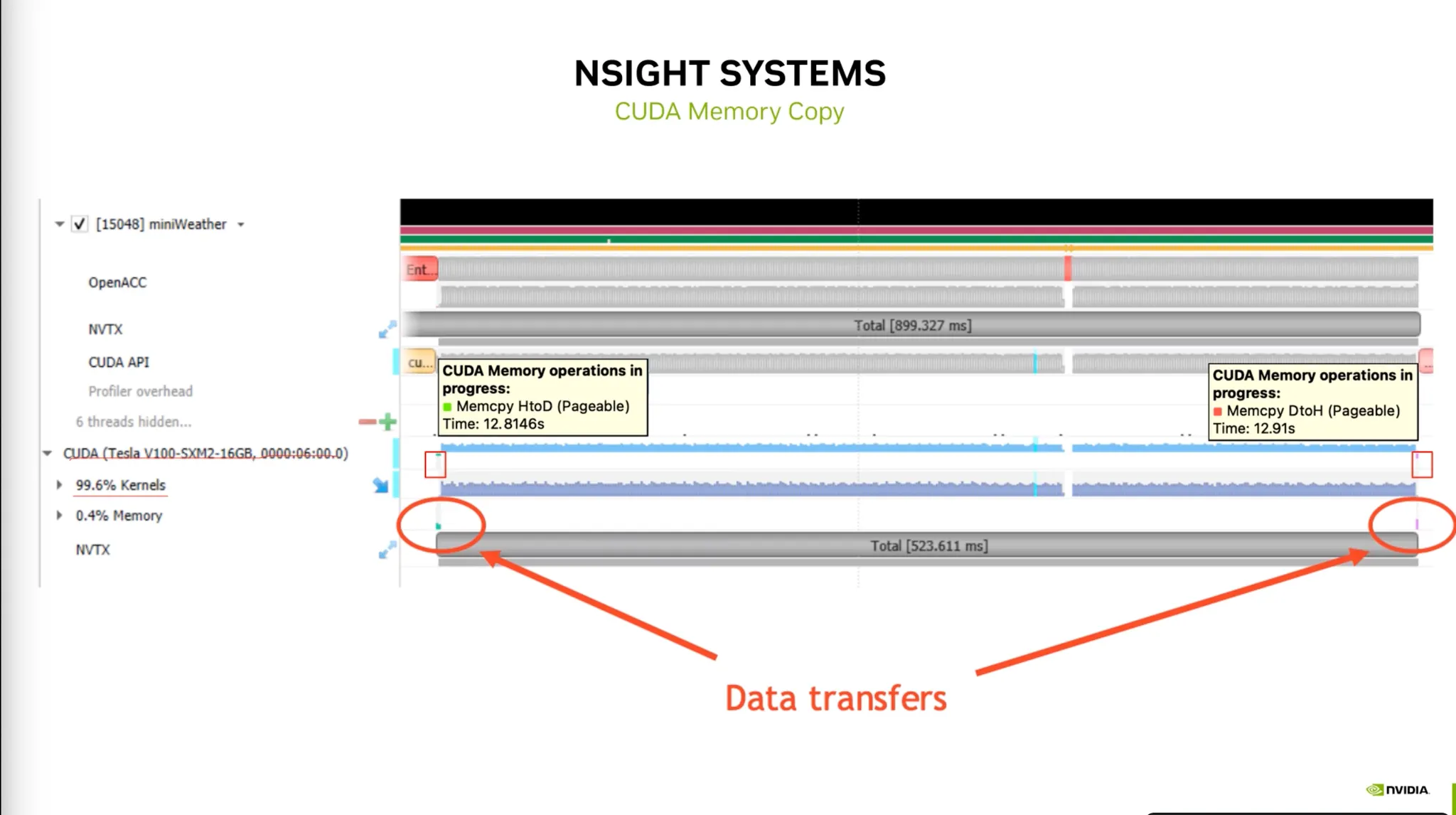
System Memory (H) 와 GPU Memory (D) 간의 메모리 전송과정 확인.
•
과도한 메모리의 전송은 Dependency가 발생함.
•
예를 들어, freeze한 network의 weight는 저장할 필요가 없음.

•
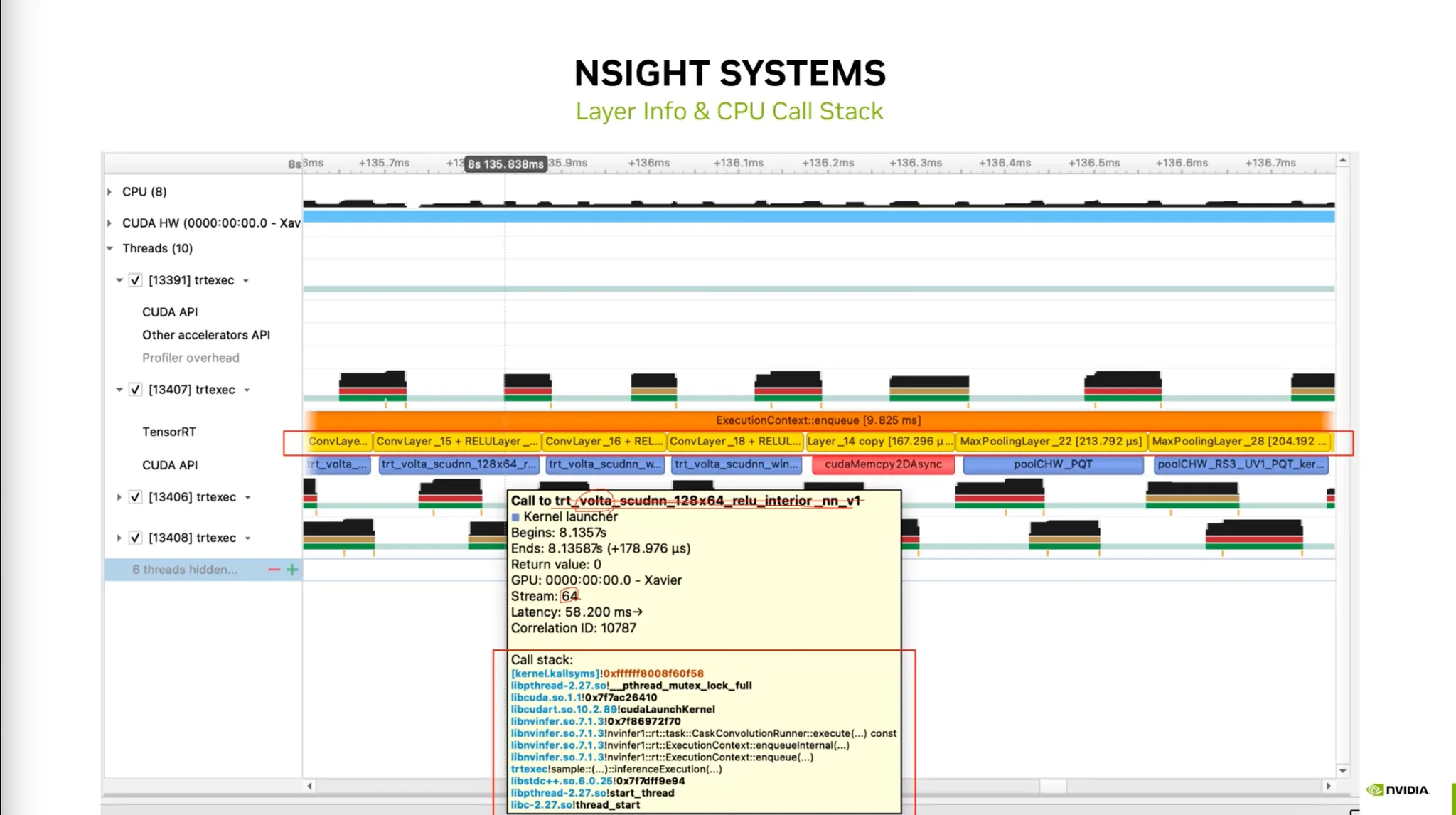
실제 DL Training 프로파일링 과정
•
연산과정의 Activity를 확인할 수 있다.
Multi-node Profiling
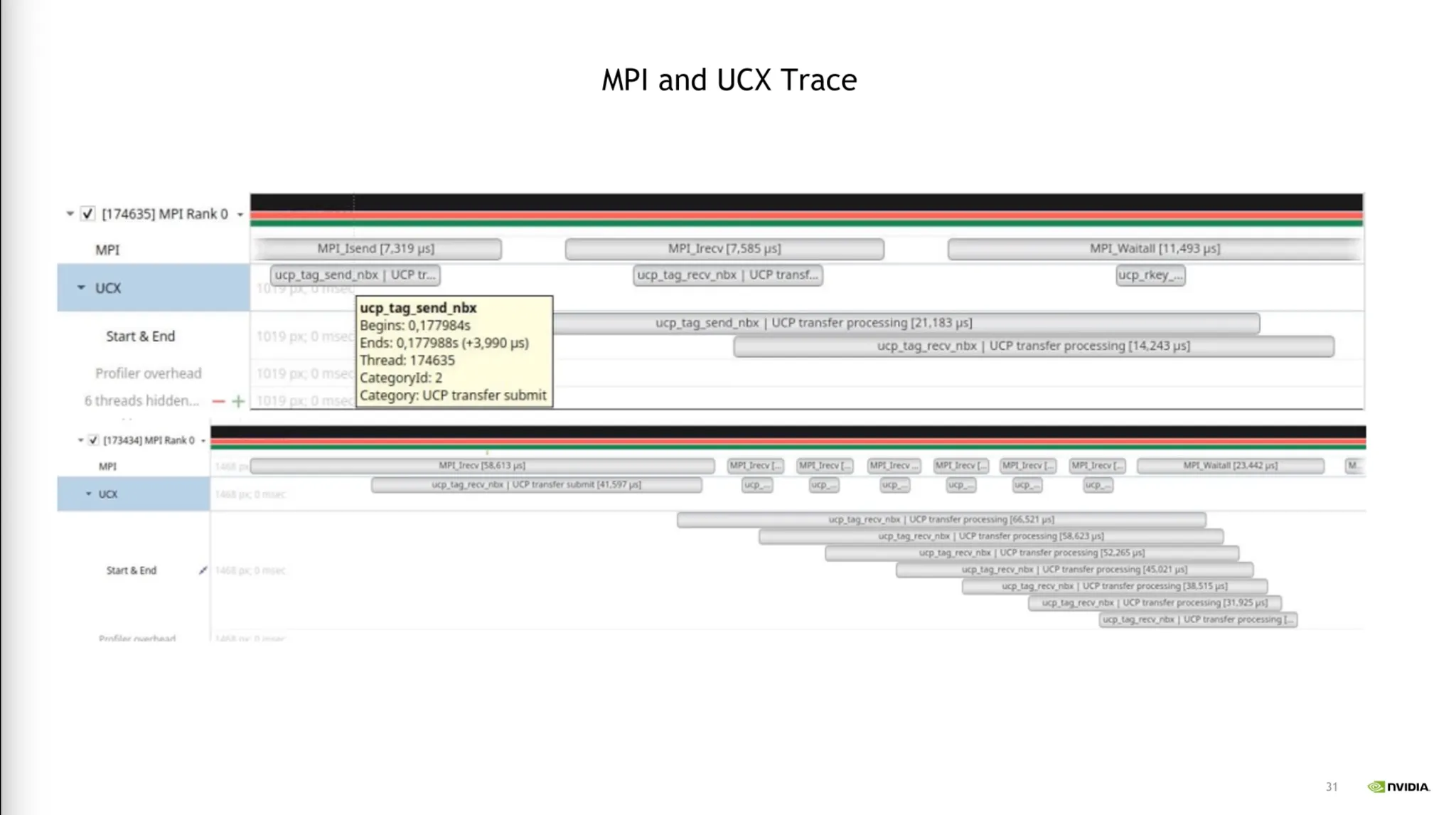
•
GPU간 Communication, SharedMemory 등을 프로파일링.
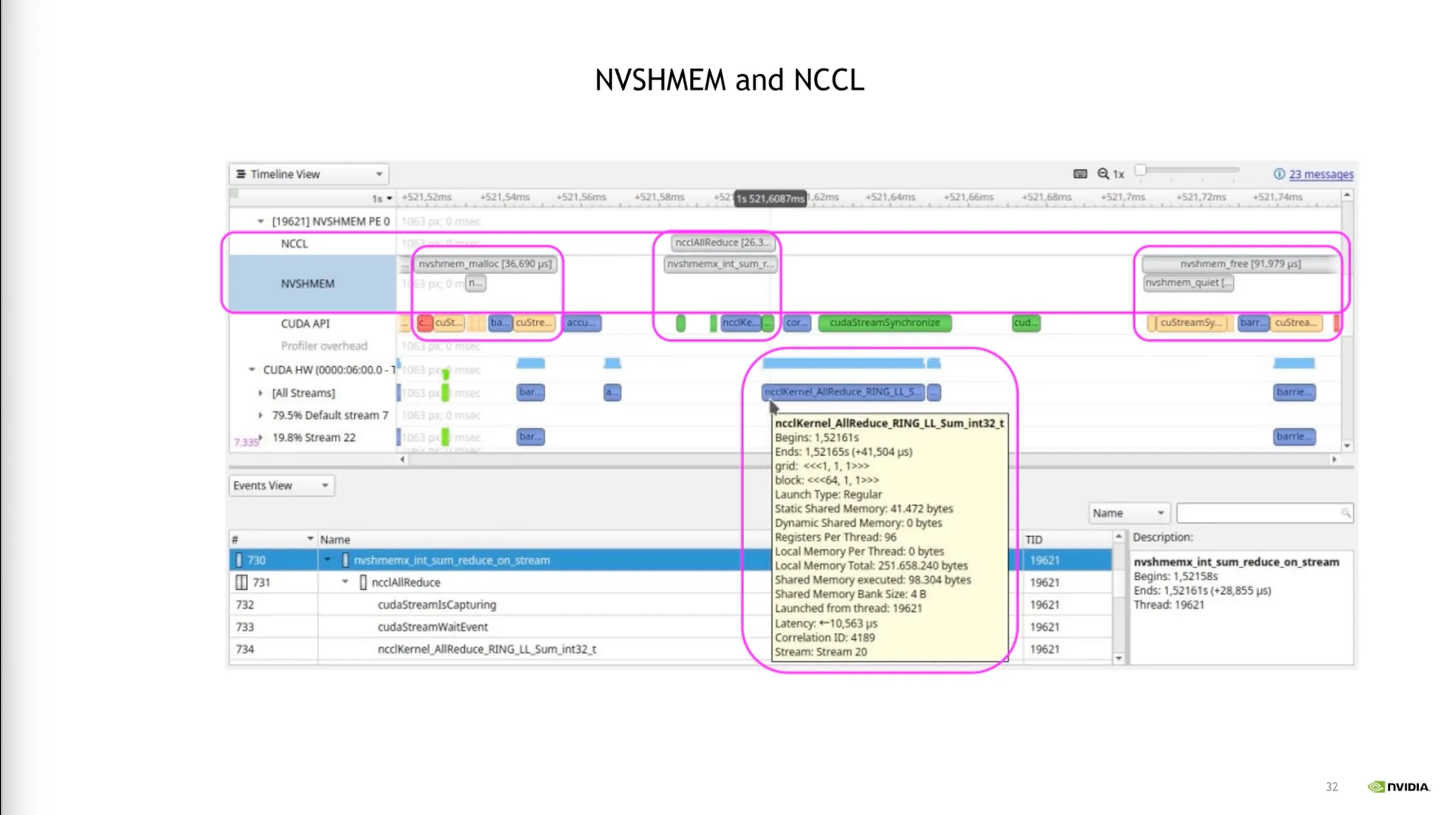
•
NCCL 라이브러리 연산
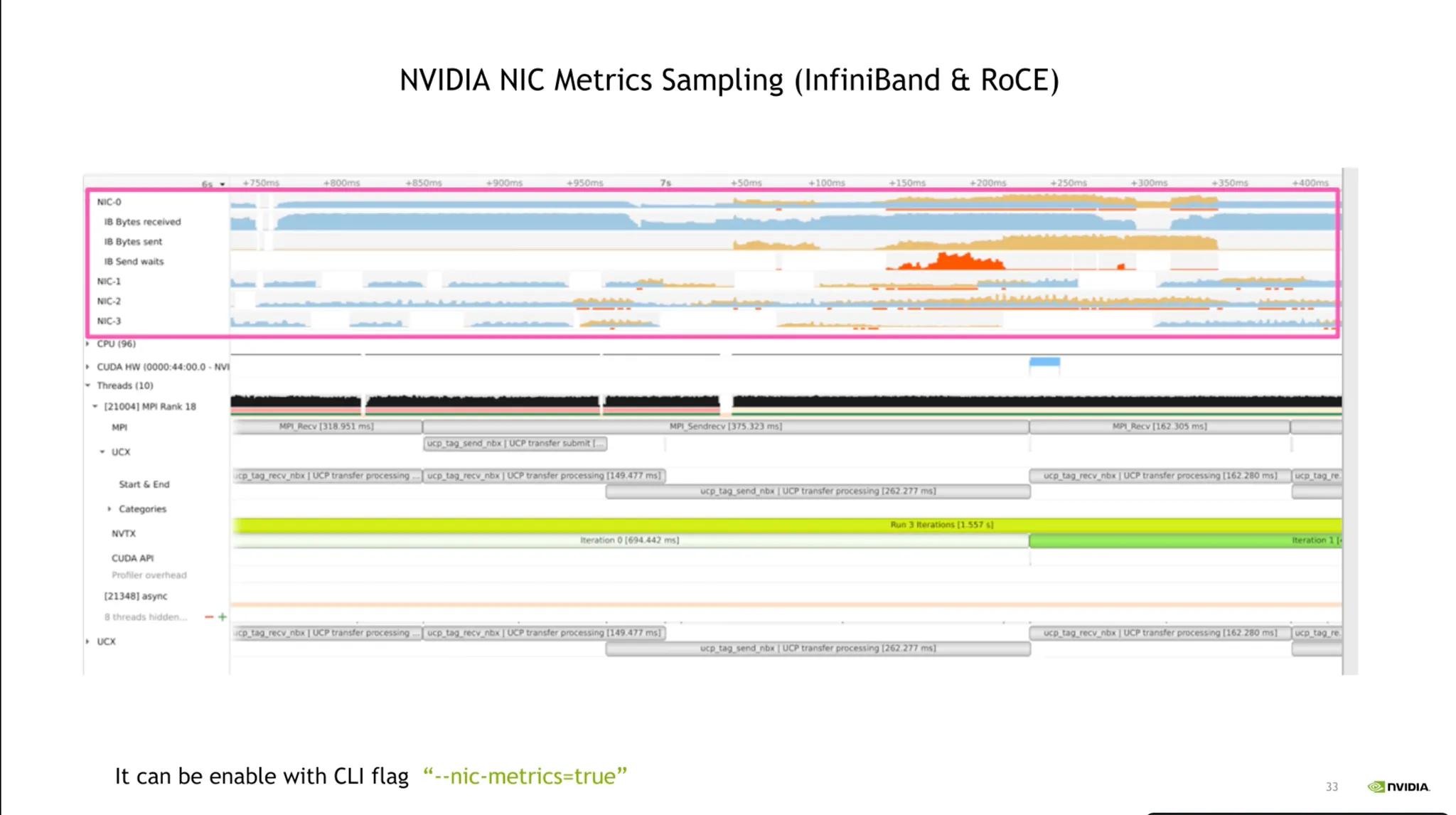
•
IO Bottleneck 확인 (NIC)
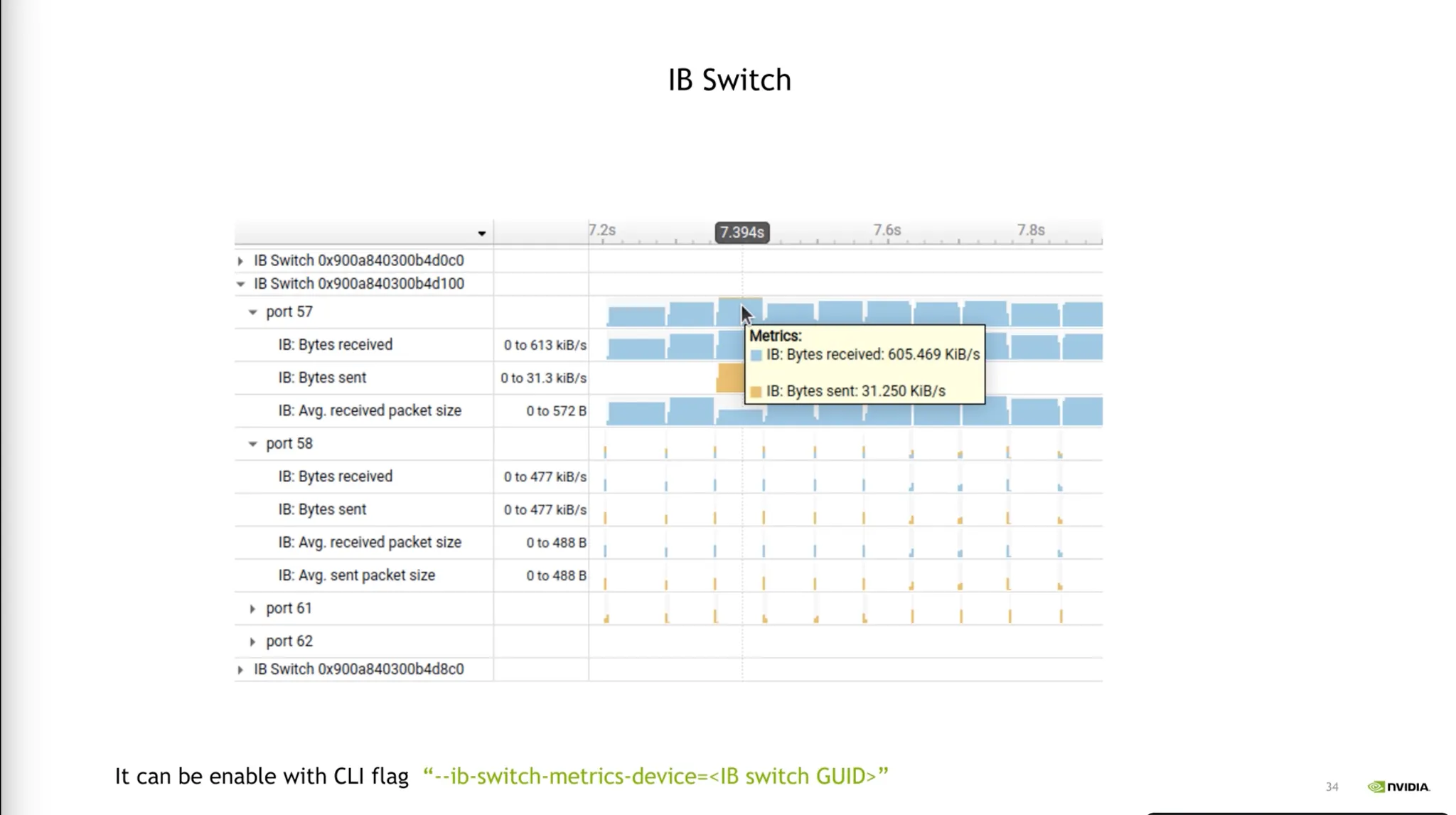
•
Infinite Band의 스위치 Level에서의 전송/수신 관련 Metric.

•
CLI 호출.
•
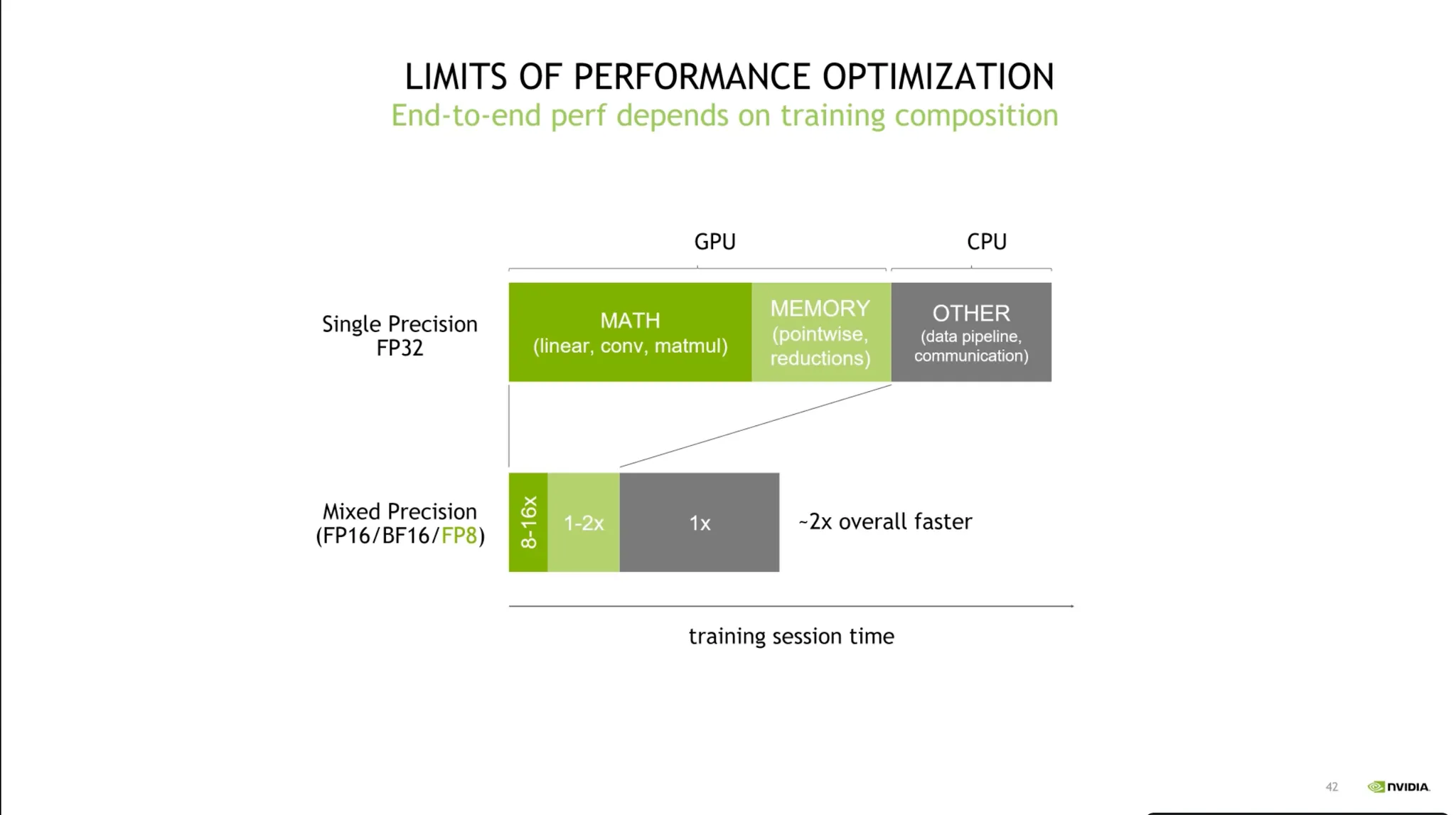
pytorch 컨테이너를 사용하는게 Bottleneck point를 최소화시키는 방향성이 된다.
•
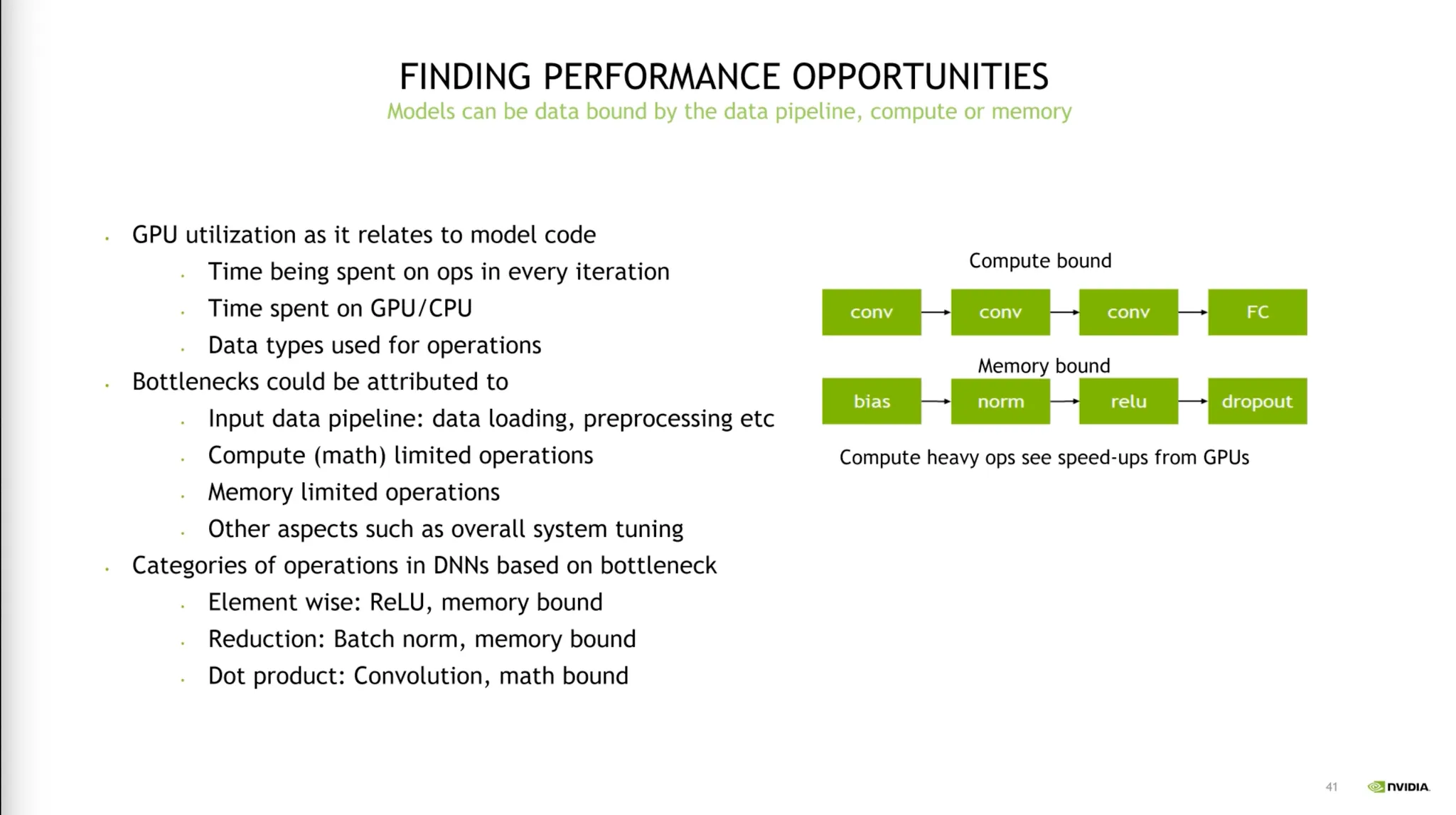
가장 많은 바틀넥을 차지하는 부분부터 줄여나가세요.
•
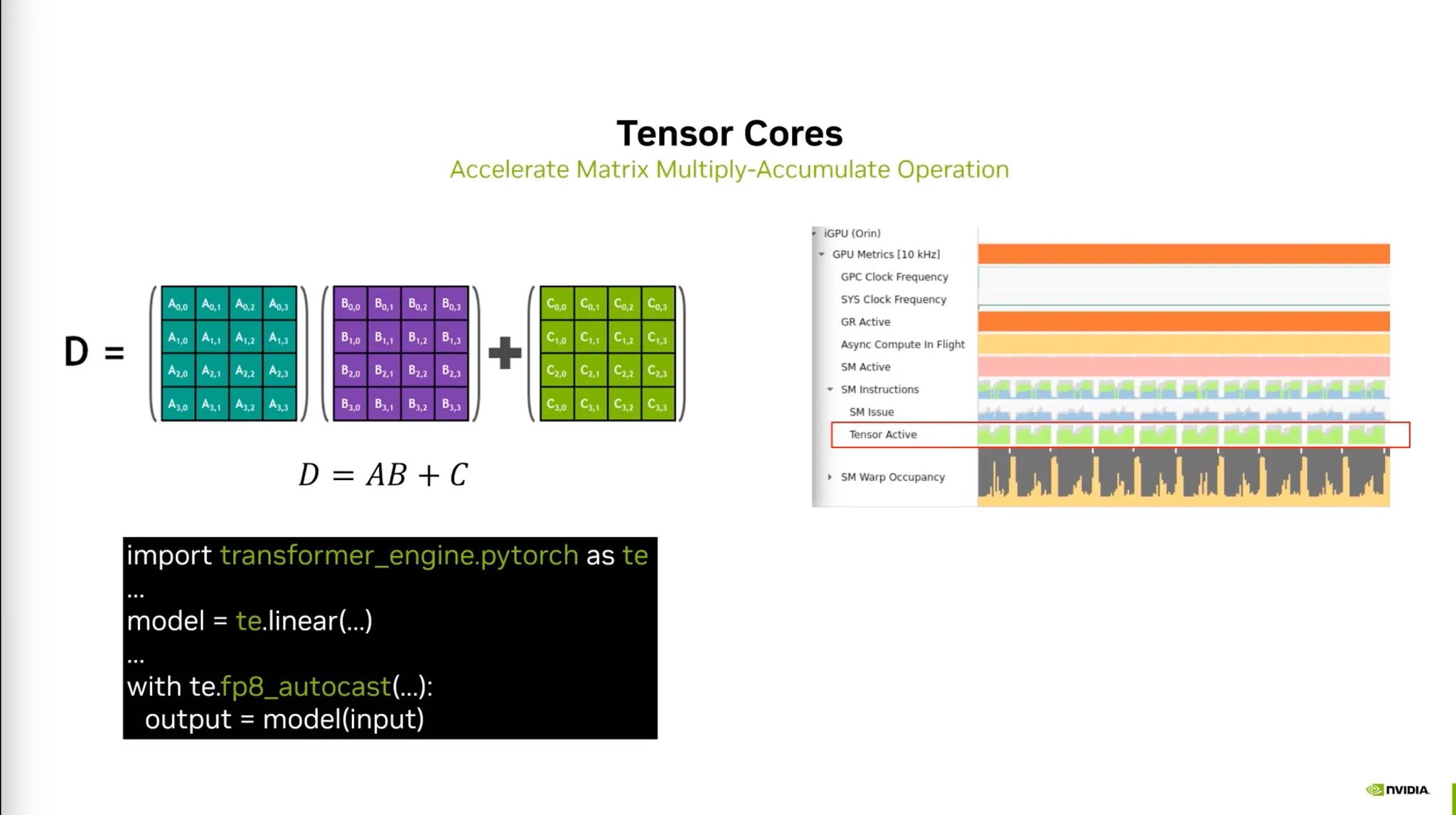
텐서코어를 활용하는 것부터 시작한다.
•
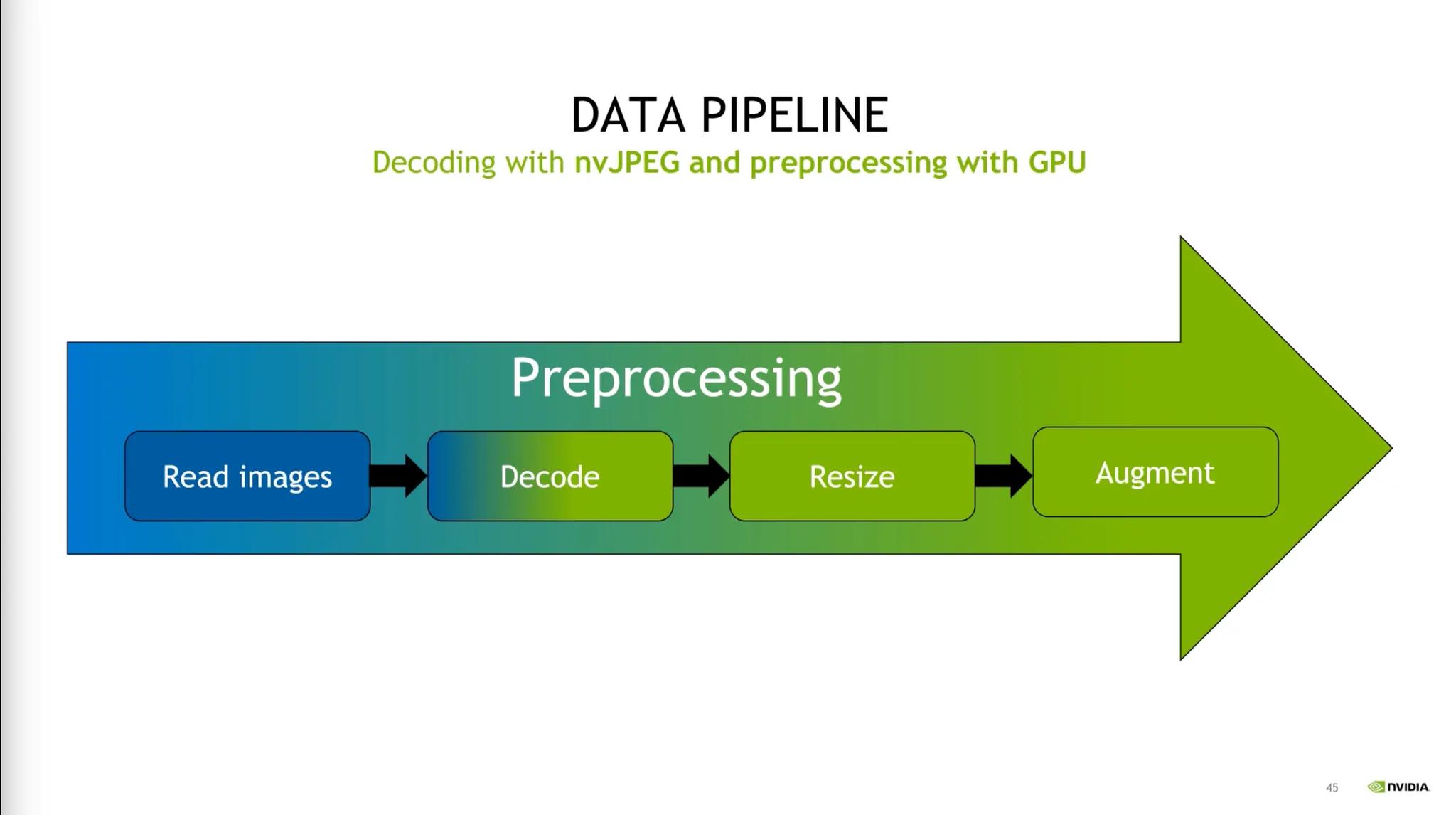
전처리 과정 역시 GPU Based 라이브러리를 활용한다.
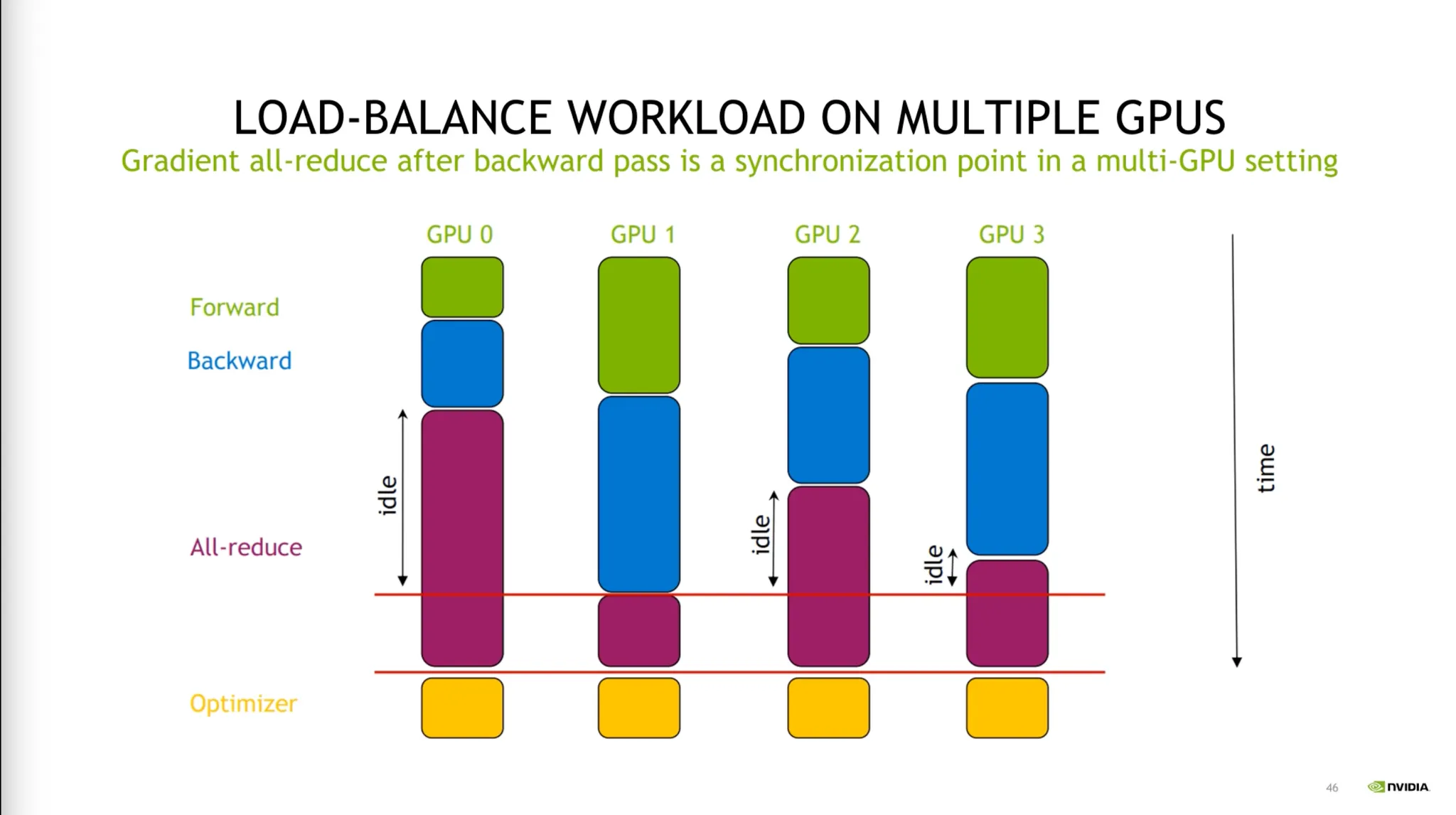
•
분산학습시 가장 성능이 낮게나오는 퍼포먼스에 맞춰지므로, 균등하게 처리가 되게끔 분배를 하는 작업이 필요하다.
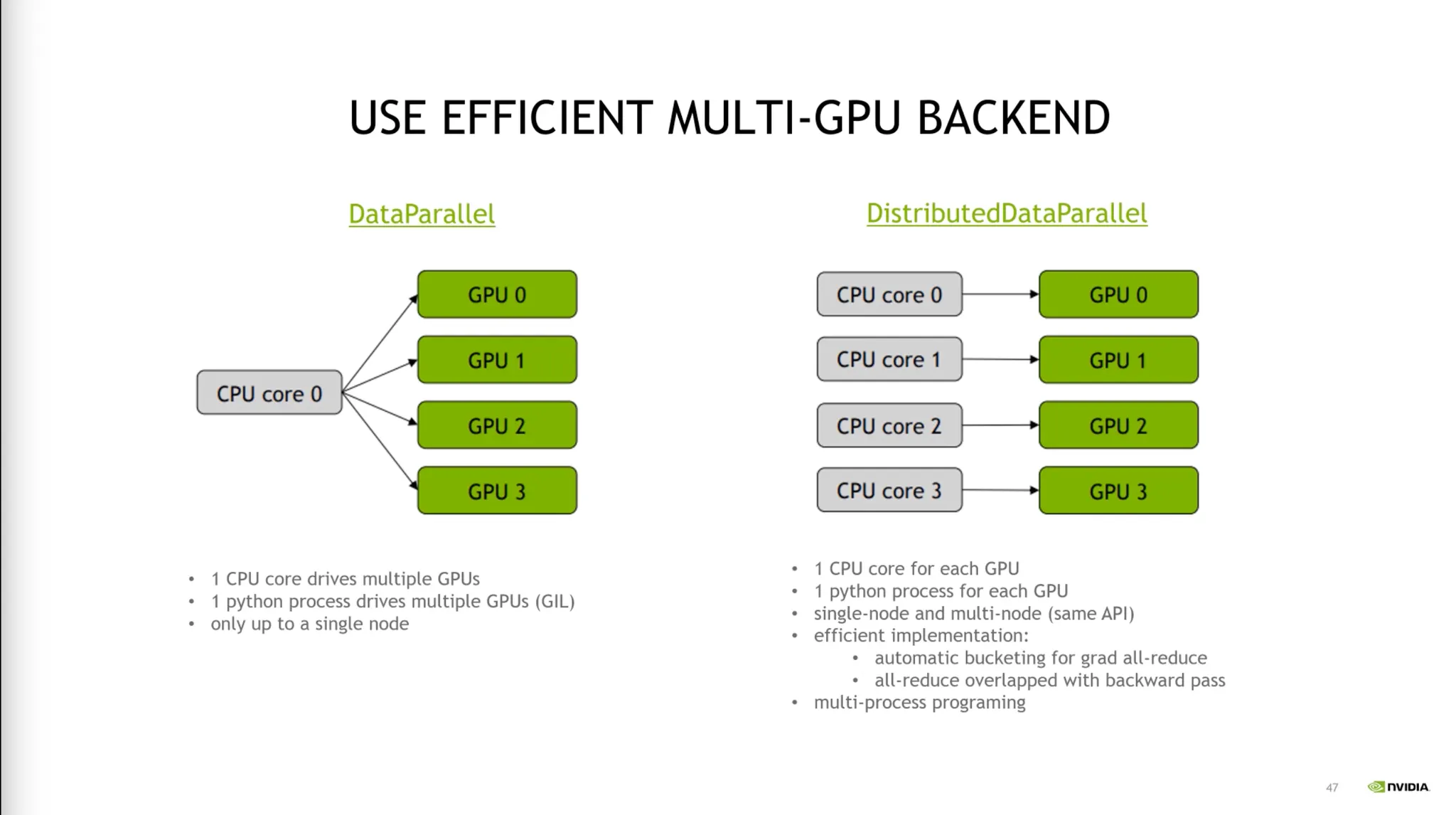
•
DP보다 DDP를 사용하자.

•
오른쪽이 낫다.

•
no_grad를 잘 활요하자.

•
TorchJIT 스크립트를 해놓자.

•
Hotspot을 의심할 수 있는 랭크들.
•
어떤 랭크에서 대기가 걸리고, 전처리 후처리 시간이 소모되는지, 동기화가 잘 되는지 등

•
멀티노드 네트워킹과정에서 트래픽이 발생하는지, 메모리 접근은 원활한지.
NVIDIA Nsight Systems
NVIDIA Nsight Compute
NVIDIA DCGM