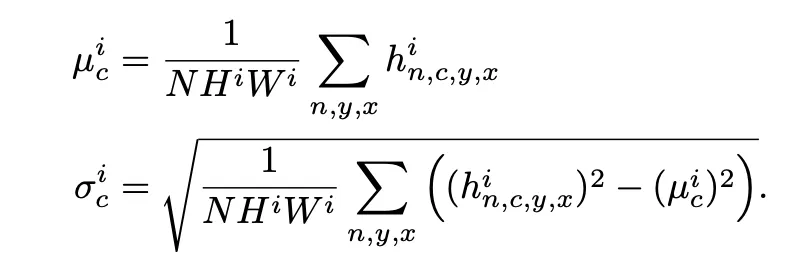Related Works
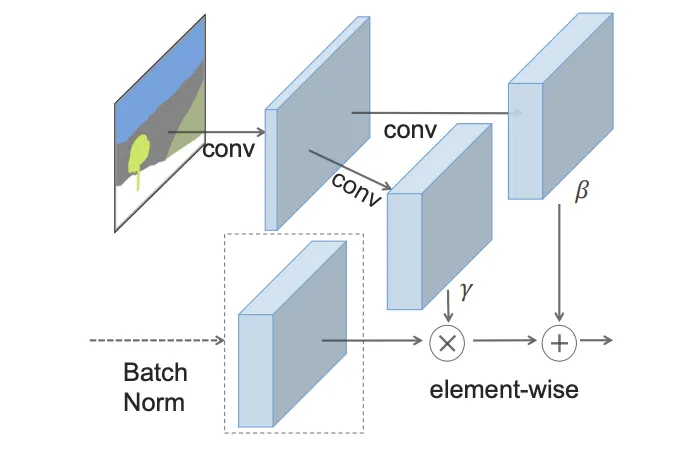
SPADE (2019, 03)

•
Activation Value (: learnable param.)
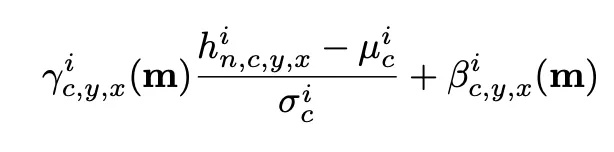
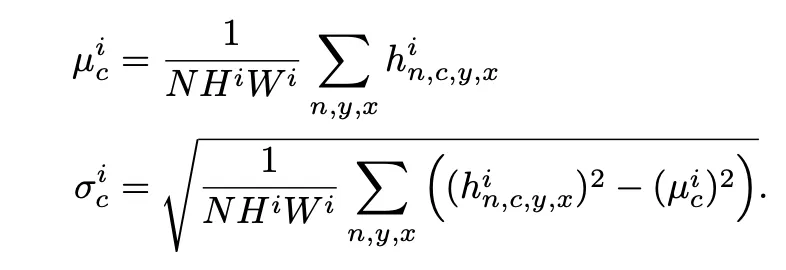
•
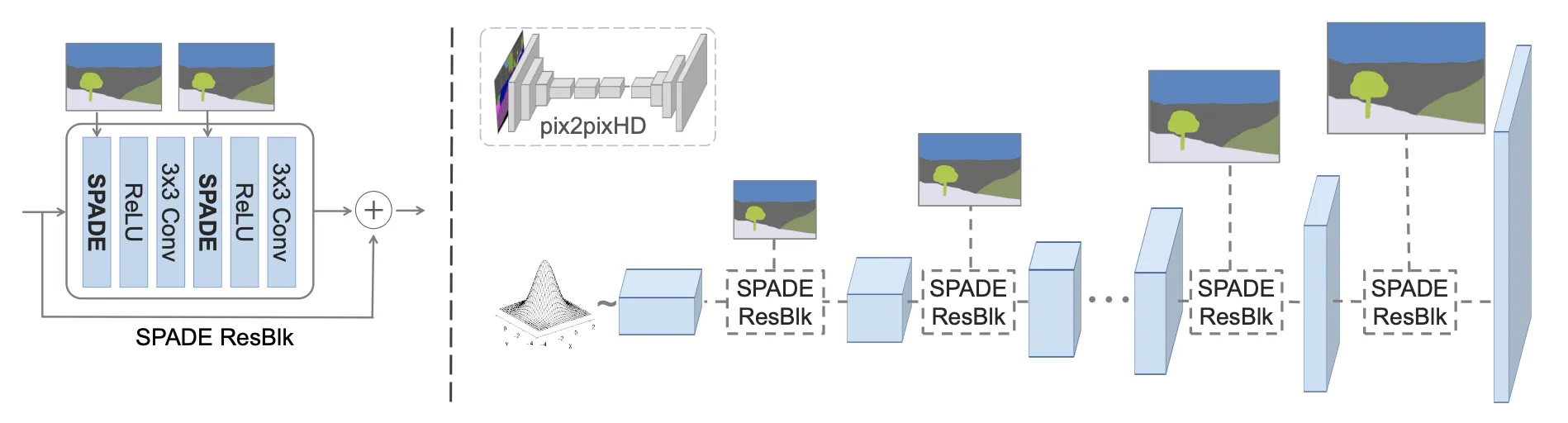
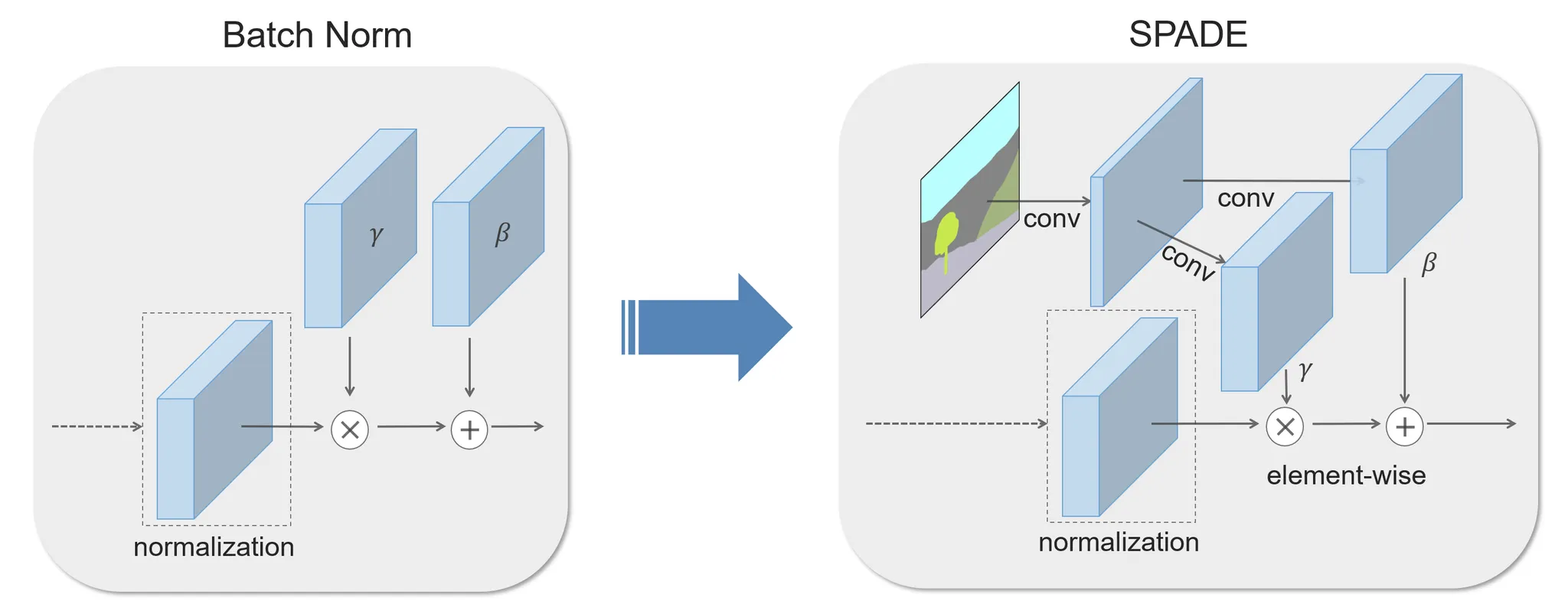
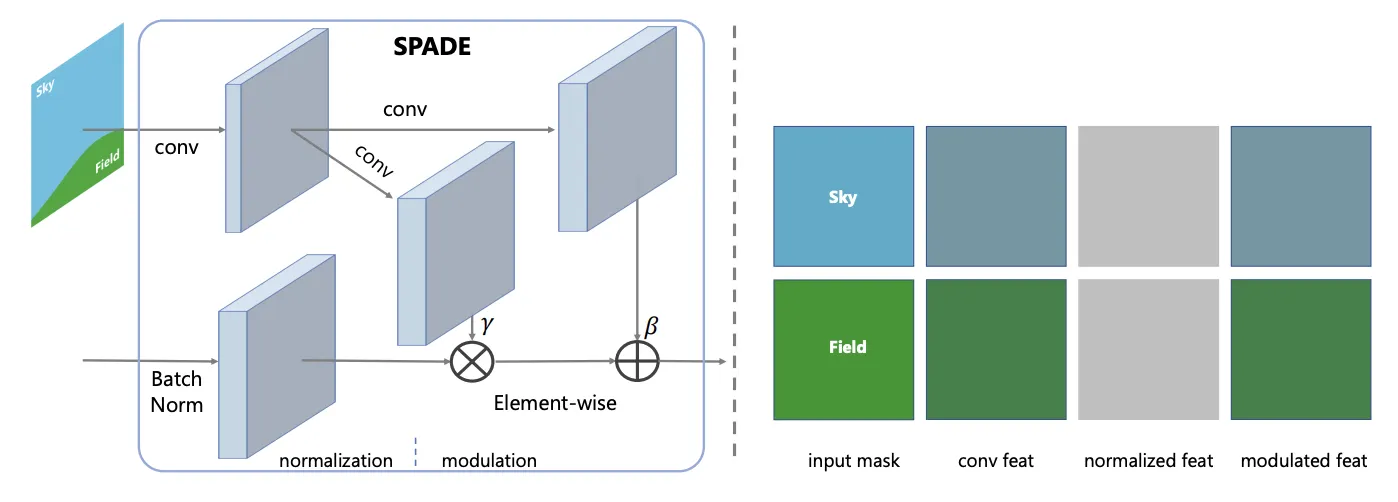
SPADE: SPAtially DEnormalize
•
AdaIN: 와 를 모두 같은 값을 곱해줌
SPADE: 와 를 feature map 의 pixel별로 다르게 적용
Loss
•
LS-GAN loss (pix2pixHD) → Hinge loss term
•
KL-div loss , weight=0.05
CLADE (2020, 04)
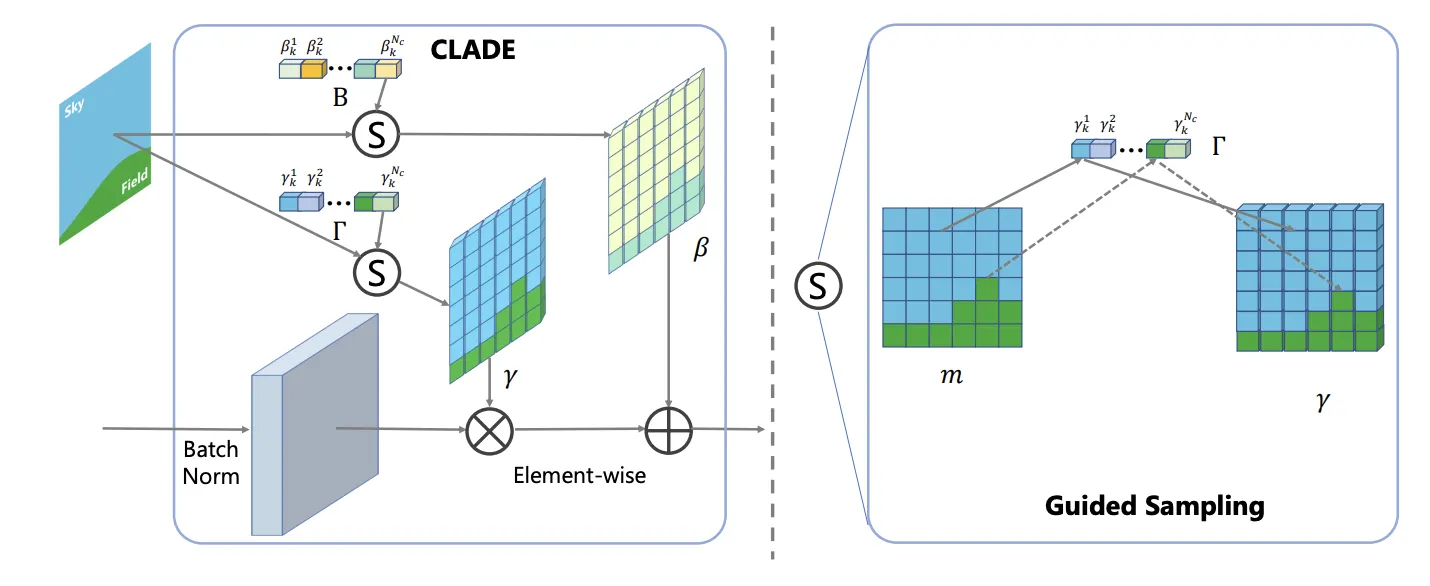
논문 리뷰를 참고하세요.
INADE (2021, 03)
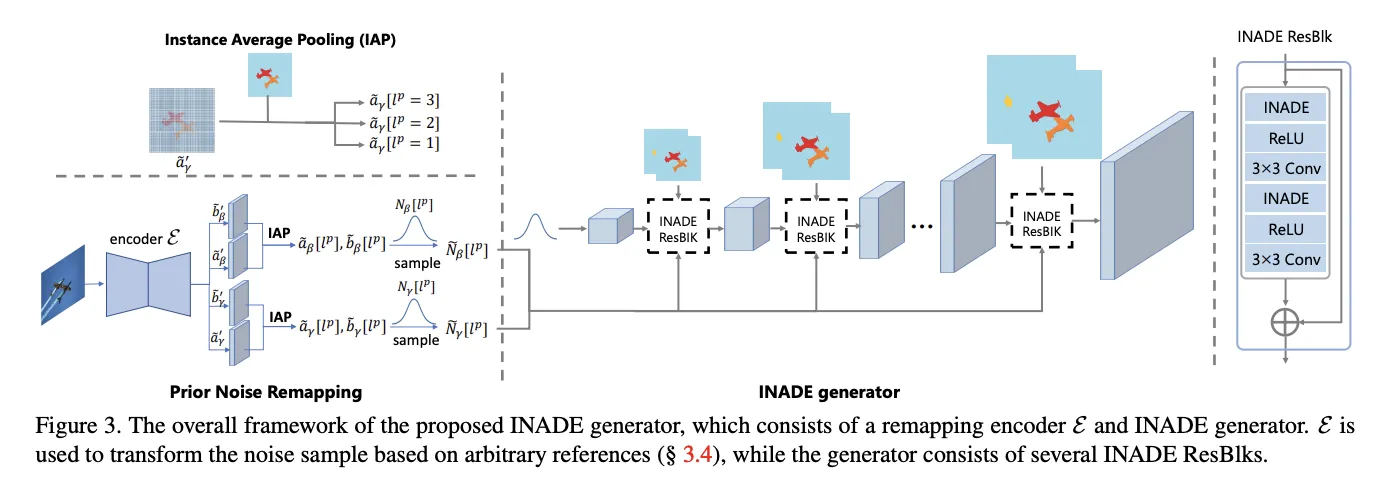
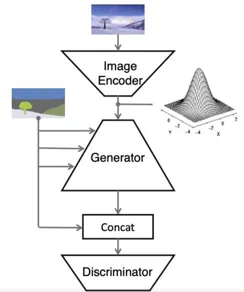
3. Method
semantic mask photo-realistic image
where
semantic label map
semantic label mapping
3.1. Conditional Normalization
Similar to Batch Normalization
activation tensor to i-th normalization layer (channel C,H,W)
Step 1) Normalization step
step 2) Modulation step
•
Conditional normalization (eg. AdaIN)에서,
modulation parameter들은 extra condition에 의해 학습된다.
•
For semantic image synthesis (eg. SPADE)에서,
modulation parameter들은 semantic mask에 의해 conditioned된다.
3.2. Variational Modulation Model
•
Semantic-conditioned modulation은 반복된 Normalization에 의한 semantic information의 "wash-out" 효과를 개선하는데 성공했다.
•
하지만 여전히 sementic-level / instance-level 의 이미지 생성은 문제가 있었는데,
이는 이미지 diversity가 semantic map / global randomness에만 conditioned 되어있기 때문이다.
•
기존의 instance-level image generation (Pix2pixHD Panoptic-based Image Synthesis)들은 diversity나 realism이 아닌 instance의 경계에만 주목을 했다.
•
따라서 Instance Conditioning이 부족하기 때문에 모든 instance들은 diversity가 부족했다.
Key to Instance-level Diversity
•
Uniform semantic-level distribution: semantic level의 특징을 deterministic하게
•
Instance-level Randomness: semantic distribution 내에서 diversity를 허용
•
이를 위해 modulation parameter를 discrete value가 아닌 각 semantic level에 대한 parametric probability distribution으로 모델링했다.
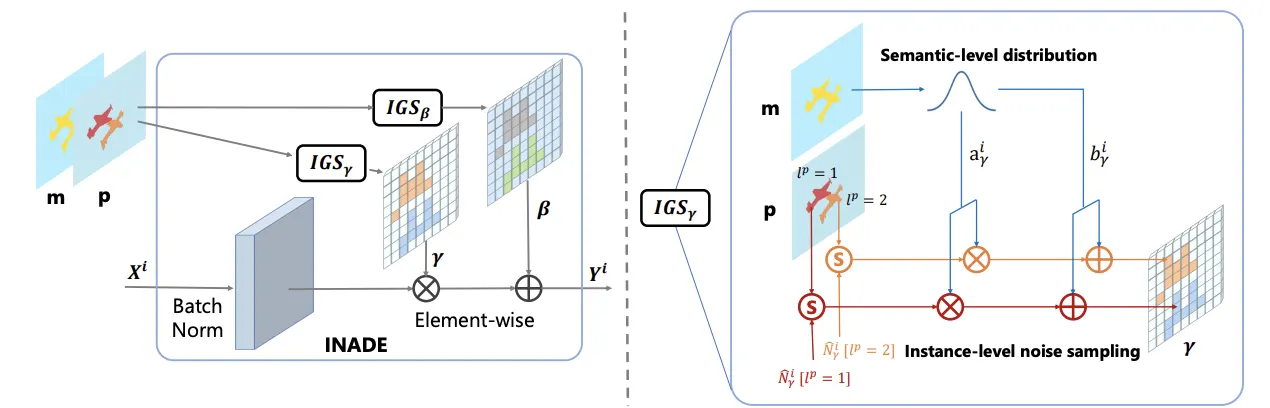
Variational Modulation Model
i-th channel depth
semantic category
distribution transformation parameter of
Stochastic noise matrix from same distribution for sampling
the corresponding modulation parameters
식을 뜯어보면
•
각 semantic label 에 속하는 instance label 에 대한 mod. param. 를 구하는 과정이다.
•
먼저 instance 가 소속된 semantic label 에 대하여
•
Scaling: 학습된 를 곱해주고
•
Randomness: 랜덤노이즈 를 곱해준 후
•
Translation: 학습된 를 더해주어 Modulation을 한다.
Instance-Adaptive Modulation Sampling
•
확률 분포 집합이 동일할 경우에 다양한 modulation parameter를 생성할 수 있다.
•
이제 Generator가 conditional norm. layer들을 여러개 가질 경우, 이를 조화하는 솔루션이 필요하다.
가장 간단한 방법 :
•
각각에 Norm. Layer에 대해 독립적으로 Stochastic Sampling
•
문제: inconsistency, diversity의 무력화 (why?)
따라서 채널 깊이가 동일하지 않은 여러 Norm. Layer에 걸쳐 일관된 instance 샘플링을 달성하는 방법 제안
Noise Sampling
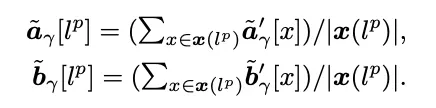
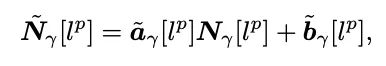
Notes
Semantic Image Synthesis = one-to-many mapping problem.
How?Modeling class-level conditional modulation parameters
Related as discrete values and sampling per-instance modulation parameters
Propose as continuous probability distribution
through 1. instance-adaptive stochastic sampling that is consistent across the network.
2. Prior Noise Remapping trough linear pertubation parameters encoded from paired references
Goal and Intuition
Controllable diversity in semantic image synthesis from perspective of semantic probablity distributions
•
each sementic class = 1 distribution
•
each inscence in this class = drawn from this distribution as a discrete sample.
Proposed
Variational Modulation Models
•
Extend of discrete modulation parameters → class-wise continuous probability distribution
(embed diverse style of each semantic categoty in a class-adopt manner)