

References
•
확률론 기초 by ratsgo
•
InfoGAN by haawron
•
Generative Models Part 2: ImprovedGAN,InfoGAN,EBGAN by Taeho Kim
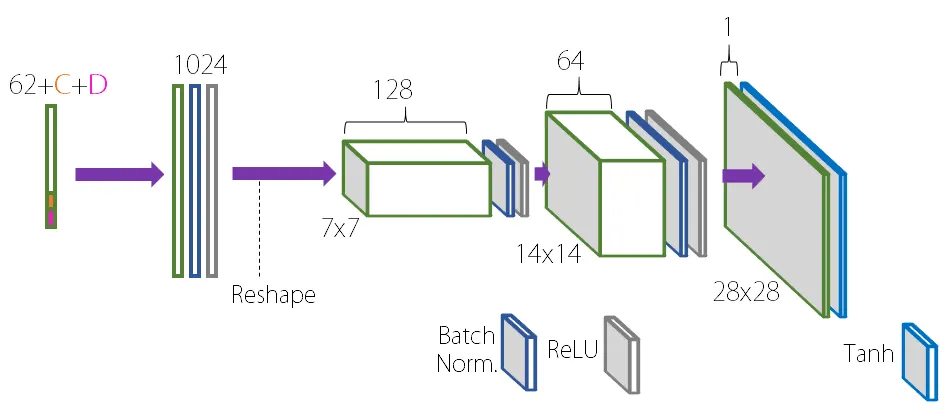
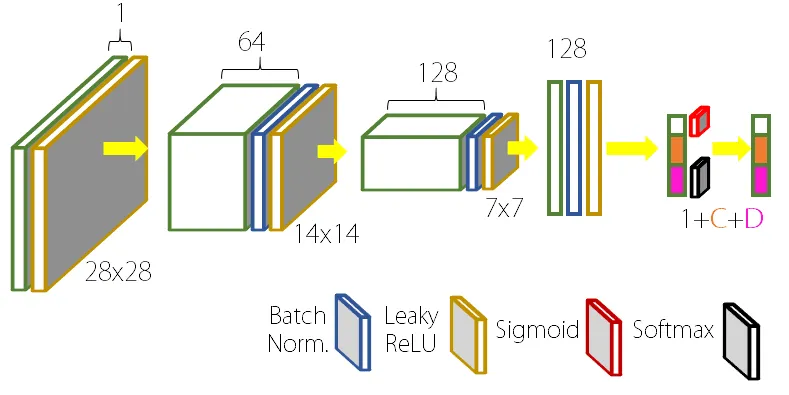
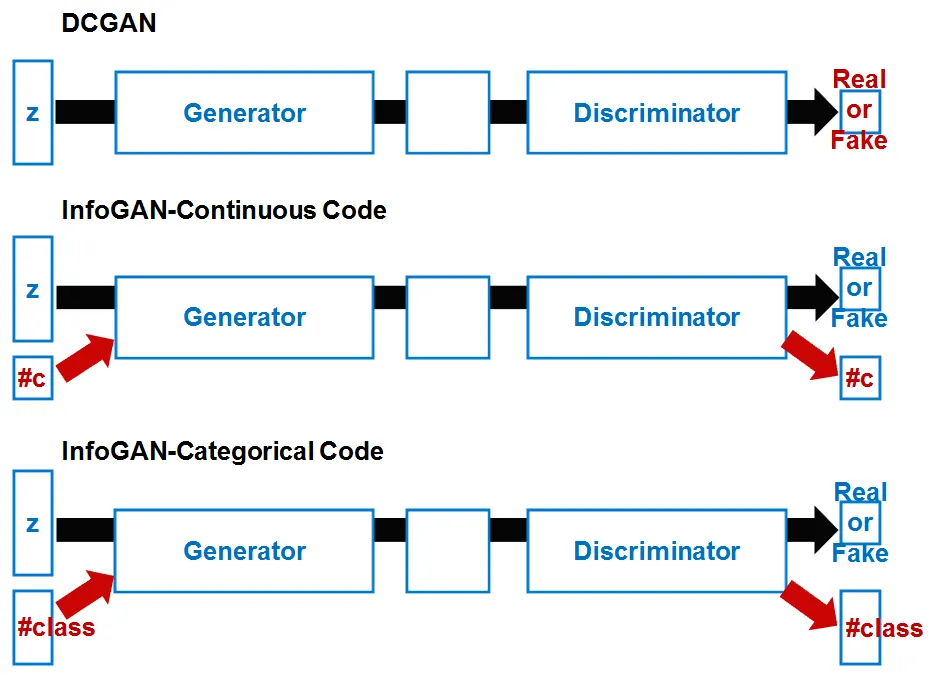
input_to_G = torch.cat((noise, continuous_code_input, discrete_code_input), 1)
fake = G(input_to_G)
input_to_D = torch.cat([images, fake])
outputs = D(input_to_D)
# outputs : 1 (real/fake) + cont_code + dist_code
Python
복사
Train D
D.zero_grad()
# Mutual Information Loss
continuous_code_output = outputs[batch_size:, 1:1+num_of_continuous_code]
discrete_code_output = outputs[batch_size:, 1+num_of_continuous_code:1+num_of_continuous_code+num_of_class_of_category]
Loss_continuous = MSE(continuous_code_output, Distribution_of_continuous_code_generator)
Loss_discrete = CrossEntropy(discrete_code_output, discrete_code_input)
Loss_D = BCE(outputs[:,0], real_and_fake_labels) + Lambda1 * Loss_continuous + Lambda2 * Loss_discrete
Loss_D.backward(retain_variables=True)
D_optimizer.step()
Python
복사
Train G
G.zero_grad()
Loss_G = BCE(outputs[batch_size:,0], real_labels) + Lambda1 * Loss_continuous + Lambda2 * Loss_discrete
Loss_G.backward()
G_optimizer.step()
Python
복사