DINO: Emerging Properties in Self-Supervised Vision Transformers
New system by facebookAI, visualization of attention Map called DINO.

•
가운데는 기존의 Supervised 방식이고, 오른쪽은 제안된 DINO방식입니다.
•
DINO는 Unsupervised pre-training of visual transfomers 로써,
네트워크는 강아지가 무엇인지 배운적도 없고 segmentation task가 무엇인지 배운 적도 없습니다.

•
그럼에도 불구하고 파도 뒤의 배나 풀 뒤의 말처럼 Occlusion을 훌륭하게 처리하는 모습을 볼 수 있습니다.
Intro & Overview

•
논문의 가장 처음에는 DINO로 얻어진 Self-attention 결과가 나와있습니다.
이 결과들은 supervision 없이 얻어졌다고 강조되어 있는 것이 특징입니다. 이 것은 Transformer를 사용한 덕분이고, 모든 attention map의 결과는 사람이 가장 집중하는 사물과 맞아 떨어지는 것을 볼 수 있습니다.
•
이런 Attention map 결과가 너무 좋아서 마치 proto segmentation과 같은 결과를 제공합니다. 따라서 앞으로 zero-shot segmentation과 같은 task 역시 수행할 수 있을 것이라고 기대할 수 있습니다.
Abstract

We questioned if self-supervised learning provides new properties to Vision Transformer (ViT). - 만약 Visual transformers에 Self-supervised learning을 적용하면 어떻게 될까?
DINO = self-DIstillation with NO labels.
•
저자는 self-supervised learning을 ViT에 적용하기 위해 self-distillation framework를 구성했습니다.
Teacher는 mometum teacher로써 centering 후 softmax에서 sharpening을 해줍니다. (아래)
No Negative Sample & No Contrastive Learning mechanism
•
Mode collapse를 방지하기 위한 batch norm, contrastive learning이나 negative sample은 필요하지 않습니다.
Vision Transformers (ViT)

ViT는 Transformers 아키텍처를 이미지에 적용한 논문입니다.
이미지를 패치를 나누어 시퀀스로 만들고, 각 패치를 임베딩으로 만든 후 Transformers에 공급하여 NLP처럼 학습했습니다. 각 sequence 맨 앞에는 [cls]라는 특별한 토큰이 필요하고 sequence의 length는 고정됩니다. input embedding에 대응하는 output embedding이 존재하는데, cls token의 위치에 해당하는 위치에 해당하는 output에는 Visual Representation이 나오게 되는데, 이 곳에 Head를 붙여 Class Classification이나 segmentation등을 수행하게 됩니다.
Self-Distillation and Self-Supervised Learning for Images
Self-supervised Learning = No Label!


•
Transformers는 CNN보다 Augmentations의 중요도가 매우매우매우 중요합니다.
•
여기서는 같은 이미지를 2개 버전으로 크롭합니다. (Augmentation)
◦
Teacher: Global Crop - 원본 이미지를 50% 이상 크기로 크롭
◦
Student: Local Crop - 원본 이미지를 50% 이하 크기로 크롭
◦
그 후 서로 다르게 Augmentation을 해줍니다. (Color Jitter, rotation..) [BYOL]
•
Loss를 보면 standard cross-entropy loss 입니다. representation이 같아야 한다는 뜻입니다.
◦
다르게 crop되고 다르게 augment되었지만, 결국 같은 이미지입니다.
◦
그렇다면, 항상 두 이미지가 같다고 판단 (win) 하기만 해서 결국 collapse할 것입니다.
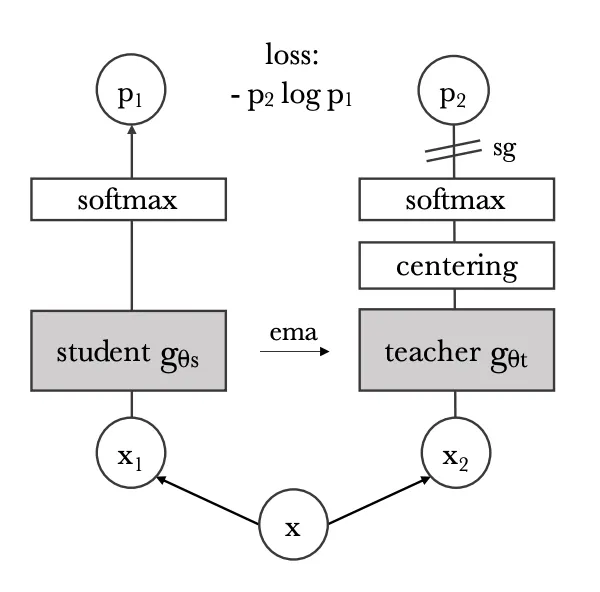

•
여기서 두 네트워크를 구성해서 Distillation이라는 Trick을 씁니다.
◦
본래 Distillation은 Big model로부터 Small model로 지식을 증류하는 방법입니다.
◦
하지만 이 논문에서는 big-small이 아닌, self-distillation framework입니다.
◦
Student는 Teacher로부터 Distillation으로 학습됩니다.
◦
그 후, Teacher는 New student로부터 ema를 통해 업데이트 됩니다.
•
이 방법은 hyperparameter에 매우매우 민감해서 몇몇 Dataset에는 실패하기도 했습니다 (Ablation).
# gs, gt: student and teacher networks
# C: center (K)
# tps, tpt: student and teacher temperatures
# l, m: network and center momentum rates
gt.params = gs.params
for x in loader: # load a minibatch x with n samples
x1, x2 = augment(x), augment(x) # random views
s1, s2 = gs(x1), gs(x2) # student output n-by-K
t1, t2 = gt(x1), gt(x2) # teacher output n-by-K
loss = H(t1, s2)/2 + H(t2, s1)/2
loss.backward() # back-propagate
# student, teacher and center updates
update(gs) # SGD
gt.params = l*gt.params + (1-l)*gs.params
C = m*C + (1-m)*cat([t1, t2]).mean(dim=0)
def H(t, s):
t = t.detach() # stop gradient
s = softmax(s / tps, dim=1)
t = softmax((t - C) / tpt, dim=1) # center + sharpen
return - (t * log(s)).sum(dim=1).mean()
Python
복사
Algorithm 1. DINO PyTorch pseudocode w/o multi-crop. from paper.
Why Cross-Entropy Loss?
•
self-supervised이므로 정답 class-label이 없습니다.
•
그래서 임의로 class-label을 매겨 출력합니다.
•
Student는 Softmax 후에 class에 대한 probability가 나옵니다.
•
Teacher는 sharpening을 거치므로 더욱 '확신에 찬 (peak)' probaility가 나옵니다.
이는 Student의 Target이 됩니다.
•
K-dim classification 문제가 되고, k-dim은 teacher에 의해 결정됩니다.
•
따라서 풀 수 있는 Classification Problem으로 만들어집니다.
이 부분이 매우 스마트한 접근방법이라고 생각됩니다.
Experimental Results


DINO가 Flickr Dataset의 중복 이미지를 인식 실험 결과
(빨간색은 False, 초록색은 True)
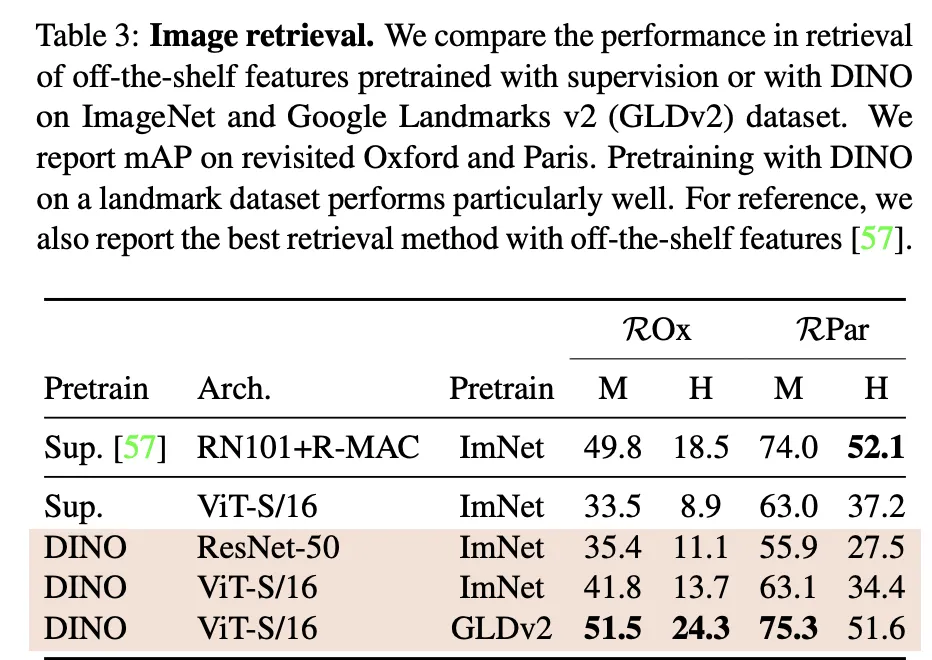
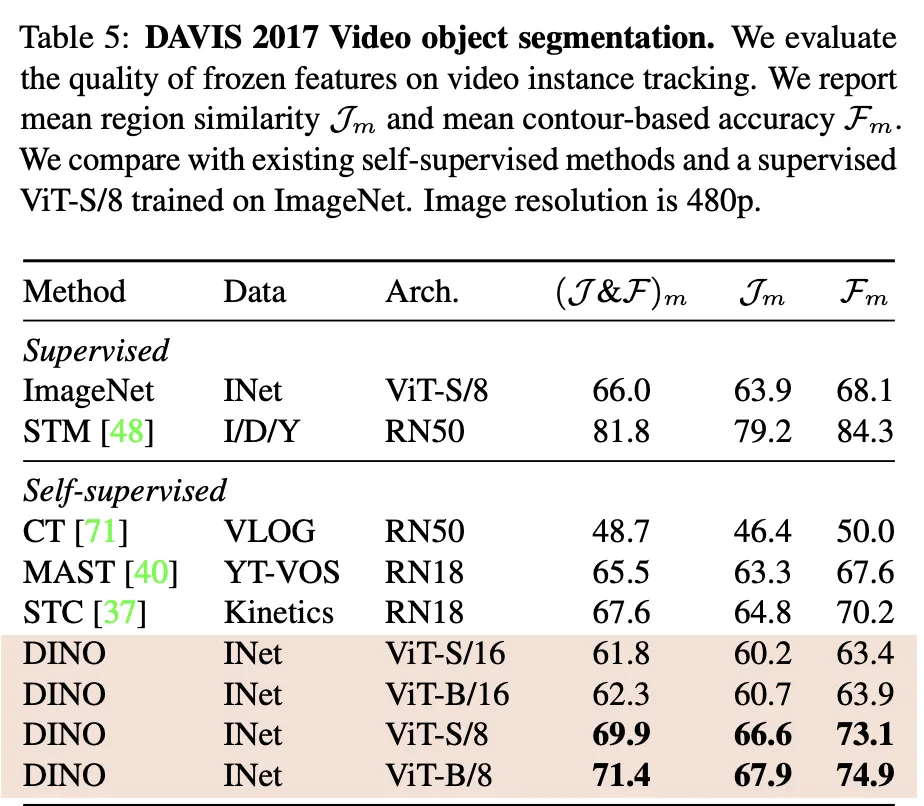
또한 DINO는 모델 전반에서 물체 각 부분이나 클래스, 생물학적 분류 체계와 같은 특성에 따라 이미지를 분류하고 그룹으로 구성하는 법을 스스로 배웁니다. 아래는 학습 진행 과정에 따른 latent space를 visualized 한 결과입니다.

최근 Facebook은 연구 개발자들이 대규모 생산에 활용할 수 있도록 오픈 소스 프레임워크, 도구, 라이브러리 및 모델을 개발하고 있습니다.
지난달 페이스북은 연구원들이 C++를 이용하여 인공지능 애플리케이션을 원활하게 실행할 수 있는 오픈소스 머신러닝 라이브러리인 Flashlight를 출시했습니다.
또한 1년 전에 Facebook은 그래프 기반 학습 모델을 효과적으로 Train 하기 위한 오픈 소스 Graph Transformer Network (GTN) 프레임워크를 출시했습니다.
FAIR (Facebook AI Research) 팀은 Transformers 연구쪽에서 매우 앞서나가는 모습을 보여주고 있습니다.