Closed-Form Factorization of Latent Semantics in GANs

Intro & Overview

Unsupervised 방식으로 Latent의 Direction을 찾는 방법을 제
•
매우 간단하지만 효과적으로 Semantic Direction을 찾음
•
적절한 Metric이 없어 방대한 양의 실험으로 이를 증명
Related Work
GAN Trend: Image Synthesis → Image Editing
•
Image Editing: Latent Code를 잘 제어하거나 원하는 방향으로 이동하는 것이 핵심
•
따라서 Latent code의 방향을 잘 찾아야 한다.
•
How to find direction?: Latent Code Manipulation → Generator → 어떤 부분이 변하는지 관찰
•
일반적으로 대량의 Latent Code를 무작위로 샘플링하여
미리 Annotation이 정의된 mask를 통하여 Latent Space에서 Classifier를 학습
•
하지만, 이런 방법은 Supervised 방식은 Dimension이 매우 큰 latent space에서 방향을 찾기가 어렵다.
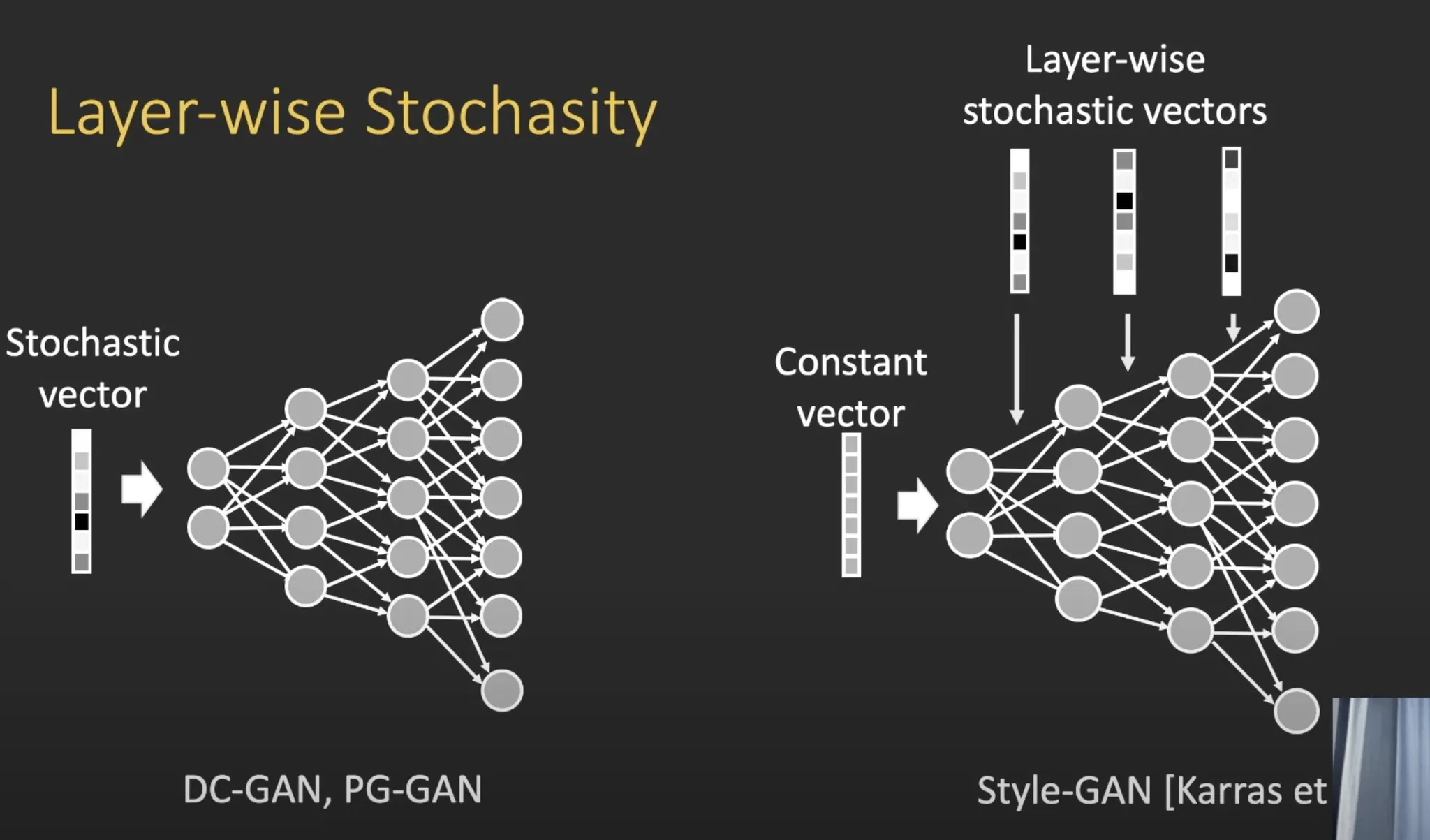
StyleGAN : Layer-wise Stochasity
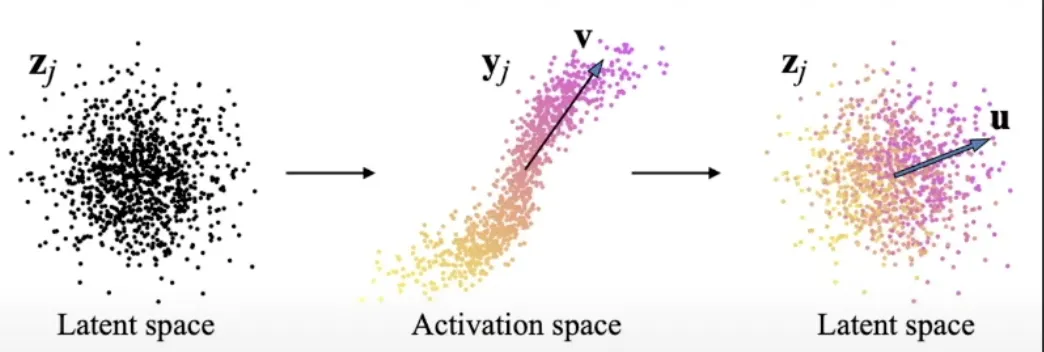
InterFaceGAN : Bridging Latent Space to Attribute Space

•
Off-the-shelf supervised classifier 가 필요함.
InfoGAN : Unsupervised Attribute Discovery in GANs
•
Mutual Information Maximization as added as a training regularizer.
GANSpace : PCA on the latent Activation
Issues for unsupervised approaches
•
How to evaluate the discovered interpretable dimensions?
•
How to measure the disentangement?
•
How to compare different methods?
Methodology
SEFA: SEmantic FActorization
•
GAN의 Generation과정 중에서
첫번째 projection 단계의 모델 가중치를 분석하여
Latent space에서 의미있는 방향을 식별하는 방법
1) GAN Image projection to Latent code
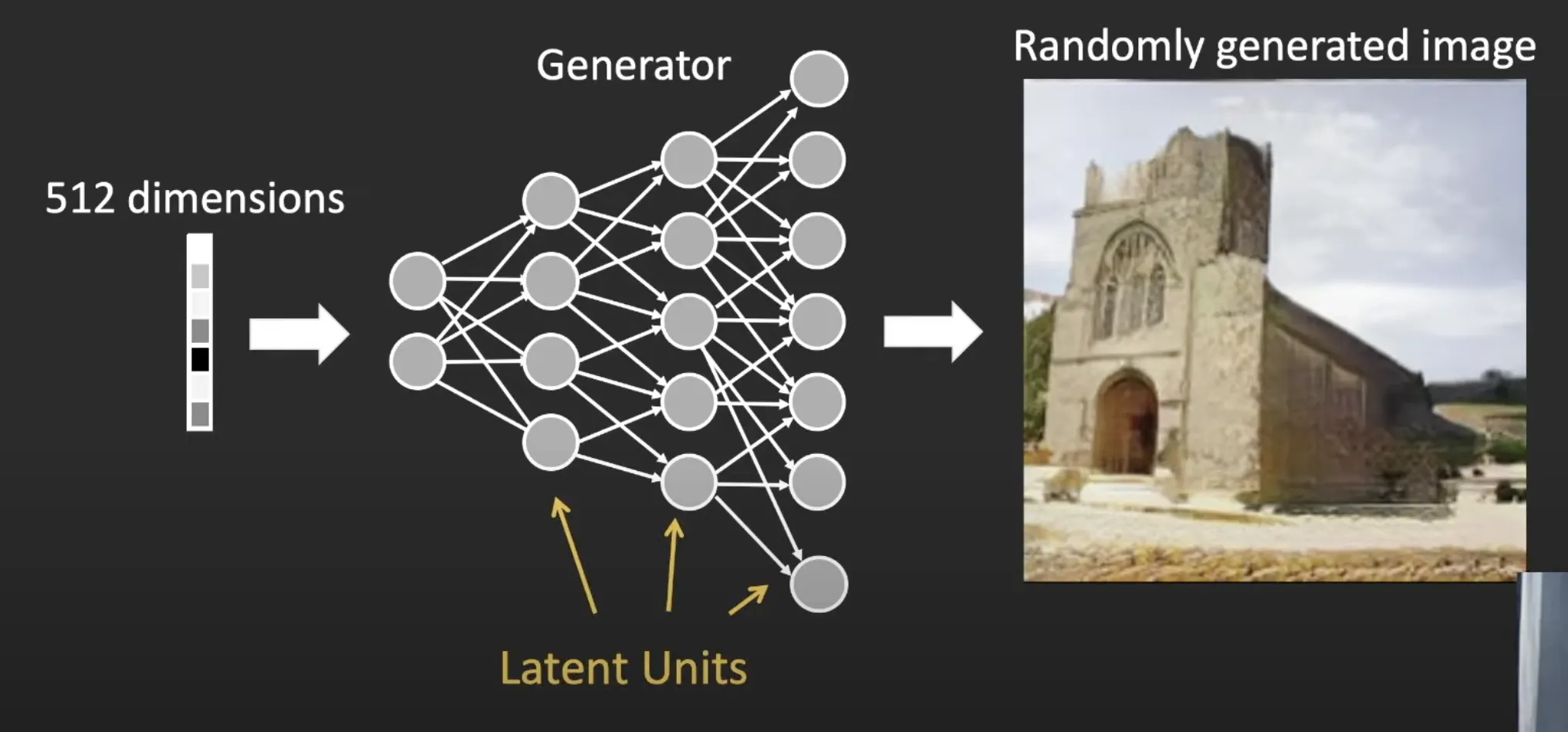
: Latent code
A: Matrix
b: Bias
2) Image Editing

: Direction
: Intensity
•
Latent space에서 Latent code 를 특정 방향 n과 강도 로 결정하여 변화된 이미지 생성.
3) Unsupervised Semantic Factorization (SEFA)
Image Editing은 latent code 와 상관이 없다.
: Direction
: Intensity
따라서, Image Editing은 오로지 에 의존적 (Dependent) 하다.
•
의 가중치가 이미지 변환에 필수적인 정보를 가지고 있다.
•
따라서 를 에 projection 시켰을 때 가장 큰 direction을 찾는 것이 핵심.
Lagrange Multiplier Methods
•
에서 가장 큰 개의 eigenvalue로 각각 대응되는 eigenvector의 방향이 이 된다.
•
이러한 방식을 PGGAN, StyleGAN, BigGAN에 대해 일부 projection을 분해하고 Latent Code를 수정하여 이미지를 생성함.
Experimental Results
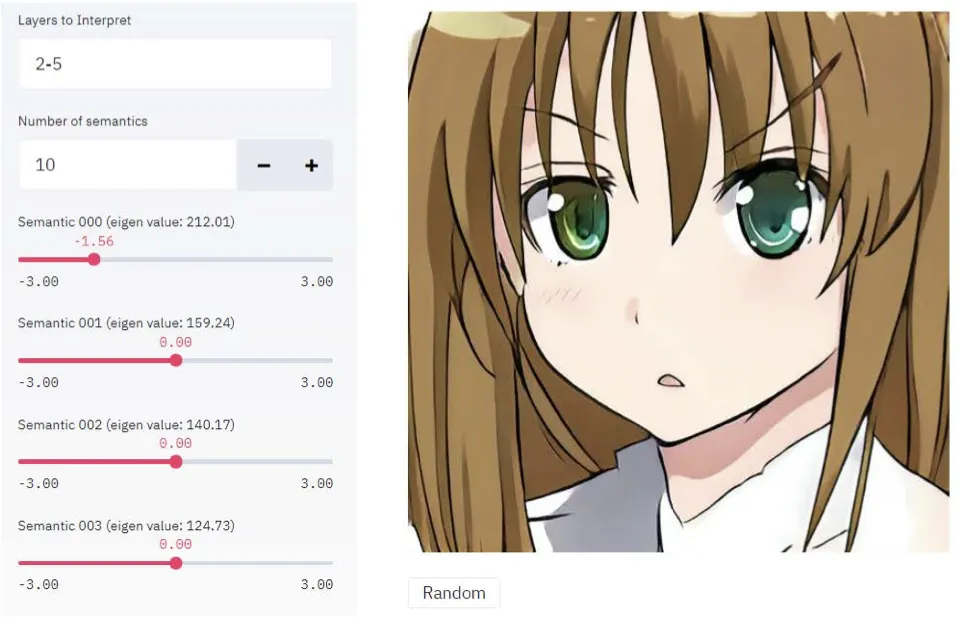
대화형 인터페이스를 개발하여 실험을 진행함.
Result on Diverse Models and Dataset
•
Interactive Editing by Tuning Interpretable Directions.
◦
Model: StyleGAN, BigGAN, StyleGAN2
▪
Supervised Learning
▪
Unsupervised Learning with SeFa.
◦
Dataset : FF-HQ, Anime Faces, Scenes, Object, Streetscapes, ImageNet
◦
Interactive Interface.
Result on StyleGAN
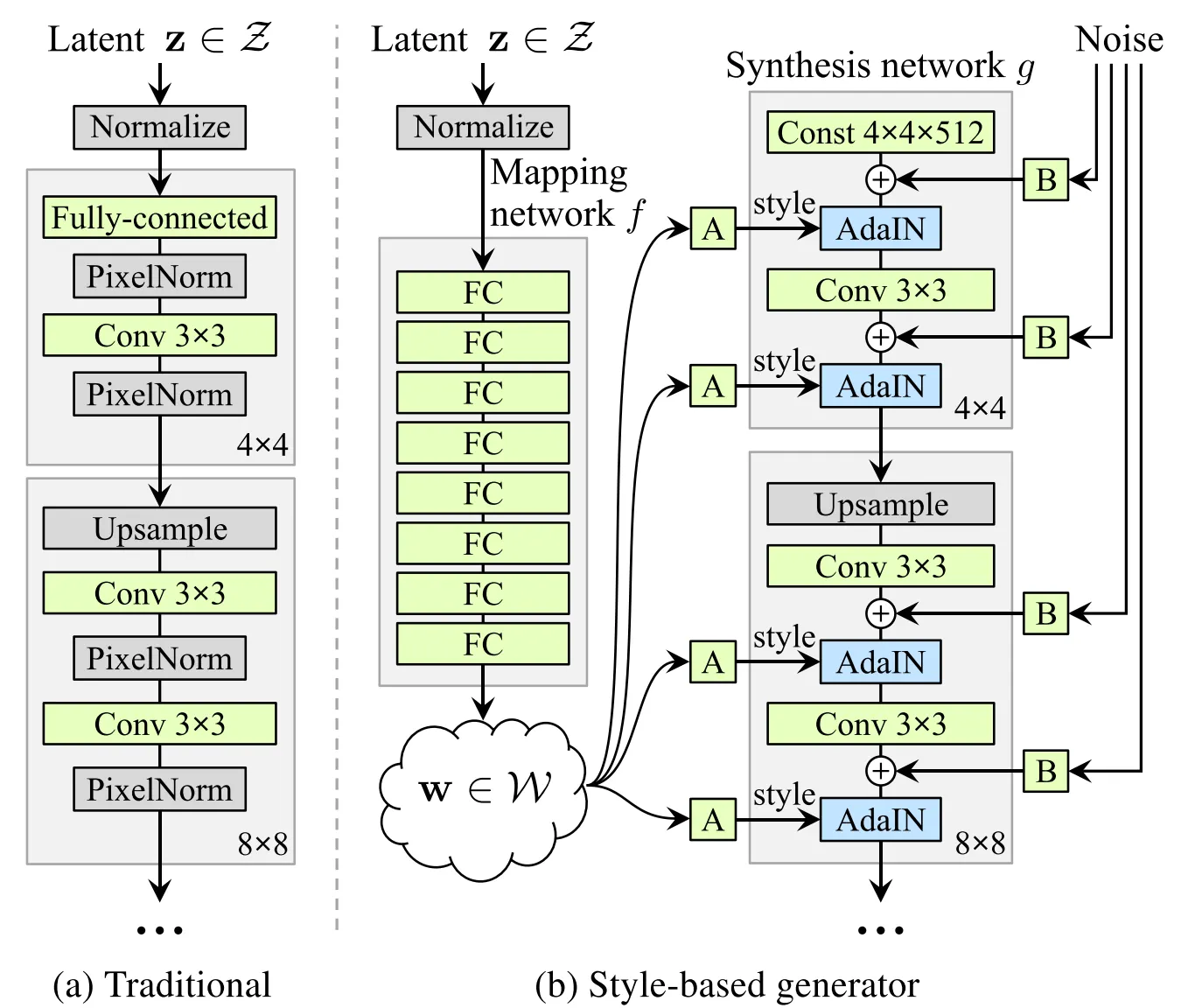

•
: Layers
분자 : how many directions result in obvious content change.
분모 : How many directions are semantically meaningful.
•
Unsupervised로 학습된 seFa 역시 GAN모델에서의 특정 레이어에서 변형도 사람이 이해할 수 있는 변형을 찾을 수 있음.
Result on BigGAN

•
줌, 회전, 개체 속성등 다양한 변환이 가능했음
Comparison with InterFaceGAN (Supervised) vs. SeFA (Unsupervised)
Qualitative Comparison

•
Unsupervised 모델인 SeFA가 Supervised Model인 InterFaceGAN과 비슷한 성능을 나타내었음.
•
SeFA는 Expensive한 Annotation이 필요하지 않으므로 효율성 면에서 우수함
Quantative Comparison
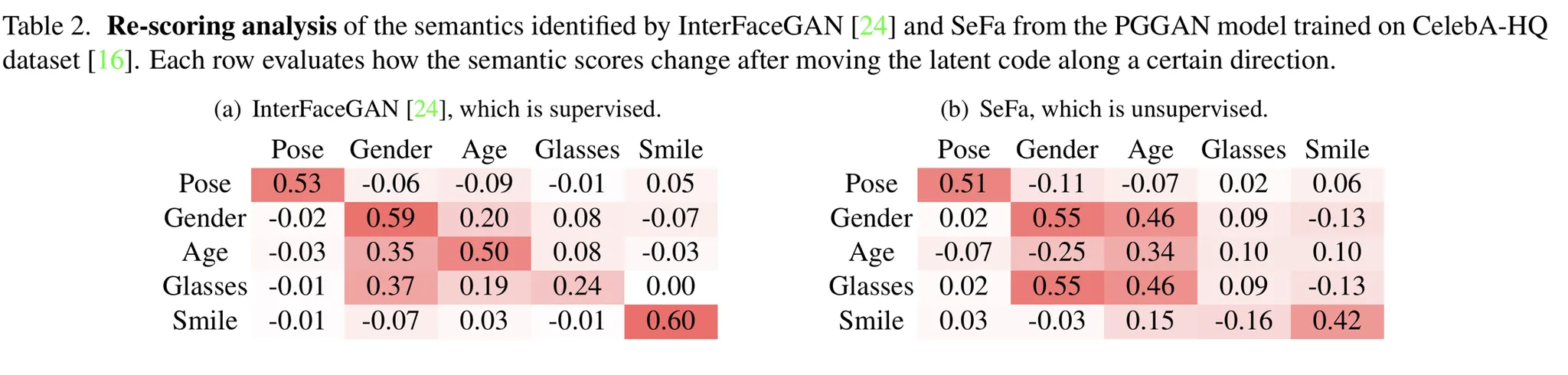
•
CelebA with ResNet50.
•
SeFA는 InterFaceGAN처럼 특징을 잘 컨트롤했다.
•
InterFaceGAN이 Supervised의 이점을 가지고 있어서 정량적으로 더욱 Robust한 모습을 보였다.
•
SeFa는 특정 Attribute (예를들어, 안경) 에서는 실패하는 모습을 보였다. 이는 Variation이 크지 않았기 때문이다.
Diversity Comparison

•
InterFaceGAN (Supervised) : Binary Attribute
SeFa (Unsupervised) : Diverse Attribute
•
InterFaceGAN (a)는 단일 속성만을 변화시키는데 반해, SeFa (b)는 다중속성을 함께 변화시킬 수 있었다.
•
SeFa가 더욱 일반적인 방법이다.
Comparison with Unsupervised vs. SeFa
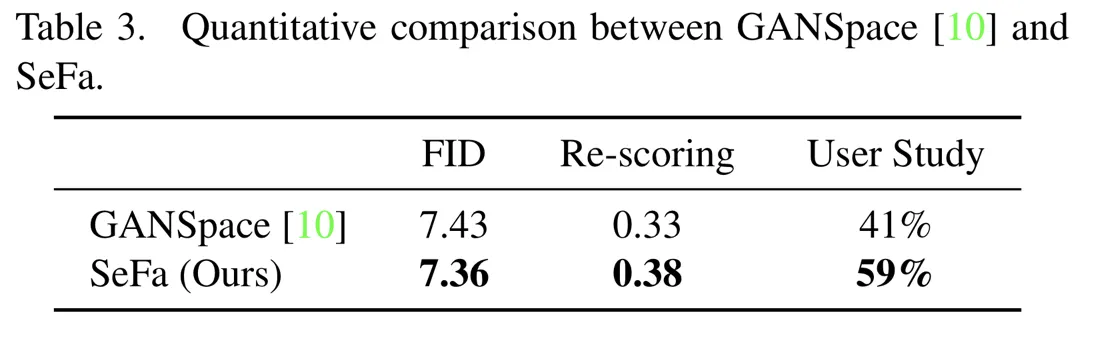
GANSpace vs SeFa

•
GANSpace (a) : 샘플된 데이터에서 PCA를 통해 latent direction의 주성분을 찾는 Unsupervised 방법.
PCA가 전체 데이터에 대한 초기 주성분들을 disentangle하는 방법임.
•
SeFa (b) : 더욱 정확한 semantic control이 가능했다.
Model Training, Data Sampling에 독립적으로 작동하는 장점이 있다.
그림에서는 피부나 Identity가 더욱 잘 보존되었음.
InfoPGGan vs SeFa

•
Pose 를 변경하고자 할 때,
InfoPGGAN(a)는 머리 색깔도 함께 변하지만
SeFa (b) 는 포즈만 잘 변경함.
Real Image Editing
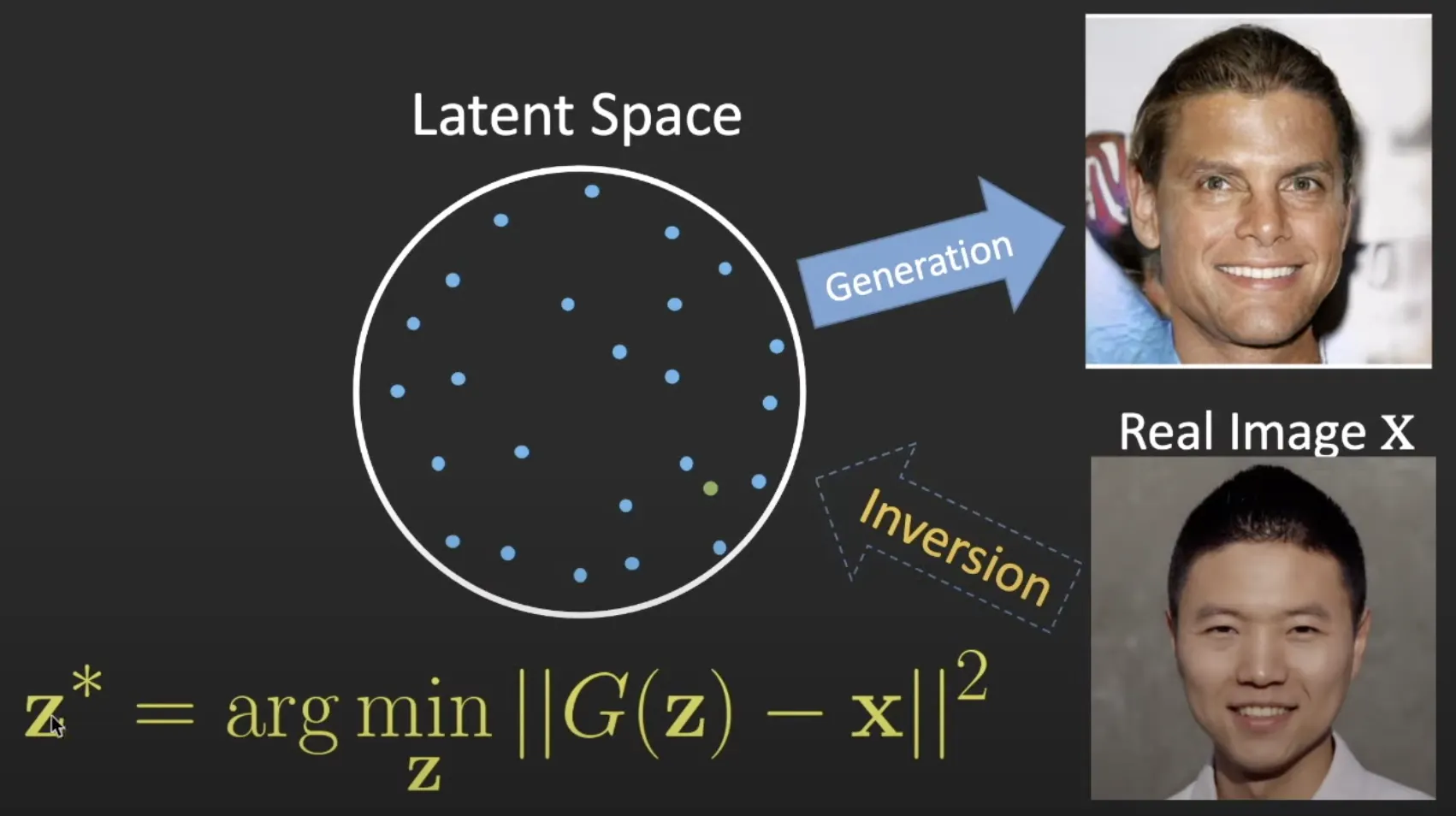


•
Generator가 실제 이미지에서 Inference 하는 것은 어렵기 때문에 GAN Inversion을 포함함.
•
GAN Inversion : 이미지를 Reconstruct 할 수 있는 최적의 Latent Code를 찾는 방법.
•
편집할 이미지에 대해 Latent Code를 찾고, 다시 Projection을 하여 SeFa에서 찾은 방향으로 이미지를 변형함.
Conclusions
•
Unsupervised Learning을 통해 다양한 유형의 GAN 모델과 학습된 Latent Semantic을 분석하여 다양한 Semantic Diretion을 찾는 SeFa를 제안함.
•
Weight 자체가 가지고 있는 learned characteristics를 사용함.