
Deep ViT Features as Dense Visual Descriptors
Shir Amir, Yossi Gandelsman, Shai Bagon and Tali Dekel
ECCVW 2022 “WIMF” Best Spotlight Presentation
(The Weizmann Inst. of Science, Berkely AI Research)
[paper][code][project][supplementary]
Intro & Overview
이 논문은 Pre-trained Vision Transformer (ViT)에서 추출된 깊은 특징들(Deep Features)을 밀집된 시각적 기술자 (Dense Visual Descriptor)로 사용하는 것에 대해 연구합니다. 저자들은 Self-supervised ViT 모델인 DINO-ViT에서 추출된 특징들이 몇 가지 주목할 만한 특성을 가지고 있다는 것을 관찰했습니다:
1.
객체 부분과 같은 강력하고 잘 국소화된 의미 정보를 높은 공간적 세밀도로 인코딩합니다.
2.
인코딩된 Semantic 정보는 관련이 있지만 다른 객체 카테고리 간에 공유됩니다.
3.
positional bias는 모델의 레이어를 통해 점진적으로 변화합니다.
이를 바탕으로, 추가적인 훈련 없이도 (Zero-shot) 효과적인 공동 분할, 부분 공동 분할, 의미적 대응과 같은 시각 작업을 수행할 수 있는 제로샷 방법론을 제안합니다.
논문 리뷰에 앞서 ViT와 DINO ViT에 대한 이해가 있다는 전제하에, 기본적인 설명은 생략하겠습니다.
Methodology
ViT as a Local Patch Descriptor.
ViT 아키텍처는 이미지를 n개의 패치로 나눈 후 n-dim space로 토큰화 시켜 position embedding을 더해 input으로 받아들이게 됩니다. 추가적인 [CLS] 토큰은 이미지의 global 특징을 포착합니다. initial 토큰세트 (는 총 L개의 Transformer로 들어가는데, 다음과 같은 연산을 거칩니다.
•
are the output tokens for layer L.
•
LN: Normalization Layer.
•
MSA (Multi-head Self Attention module): project token into Q, K and V.
Transformer와 ViT에 대한 자세한 내용은 다음 블로그를 참고해주세요.


CNN vs. ViT
CNN Feature와 ViT Feature는 딥러닝 기반 이미지 처리에서 중요한 두 가지 접근 방식입니다. 각각의 특징들은 이미지 인식과 분석에 있어서 고유한 장점과 단점을 가지고 있습니다. 여기서는 CNN 특징과 ViT 특징을 비교해보겠습니다.
CNN Feature
1.
지역적 특성 인식: CNN은 지역적 특성을 인식하는 데 강력합니다. 이는 필터를 통해 이미지의 작은 부분에서 패턴을 학습하고, 이를 통해 복잡한 특징을 단계적으로 구축합니다.
2.
계층적 구조: CNN은 저수준 특징에서 고수준 특징으로 정보를 계층적으로 추출합니다. 이는 이미지의 기본적인 에지부터 시작해 점점 더 복잡한 개체의 부분까지 인식할 수 있게 합니다.
3.
변형에 강함: CNN은 이미지의 변형(예: 이동, 회전, 크기 변화)에 강한 내성을 가지고 있습니다. 이는 풀링 레이어를 통해 얻어지는 공간적 불변성 덕분입니다.
4.
효율적인 연산: CNN은 이미지의 특정 부분에만 초점을 맞추기 때문에, 전체 이미지를 한 번에 처리하는 것보다 연산이 효율적일 수 있습니다.
ViT Feature
1.
전역적 특성 인식: ViT는 이미지 전체에 걸쳐 특성을 인식합니다. 이는 이미지의 모든 부분을 동시에 고려하여 전역적인 컨텍스트를 이해하는 데 도움을 줍니다.
2.
Self-attention 매커니즘: ViT는 자기 주의(self-attention) 메커니즘을 사용하여 이미지의 다른 부분 간의 관계를 학습합니다. 이는 이미지 내의 복잡한 상호작용을 포착하는 데 유용합니다.
3.
데이터 효율성: ViT는 일반적으로 많은 양의 데이터를 필요로 합니다. 이는 ViT가 효과적으로 훈련되기 위해 많은 예제를 필요로 하기 때문입니다.
4.
높은 계산 비용: ViT는 일반적으로 CNN보다 더 많은 계산 비용을 요구합니다. 이는 자기 주의 메커니즘이 복잡한 연산을 필요로 하기 때문입니다.
CNN Feature vs. ViT Feature
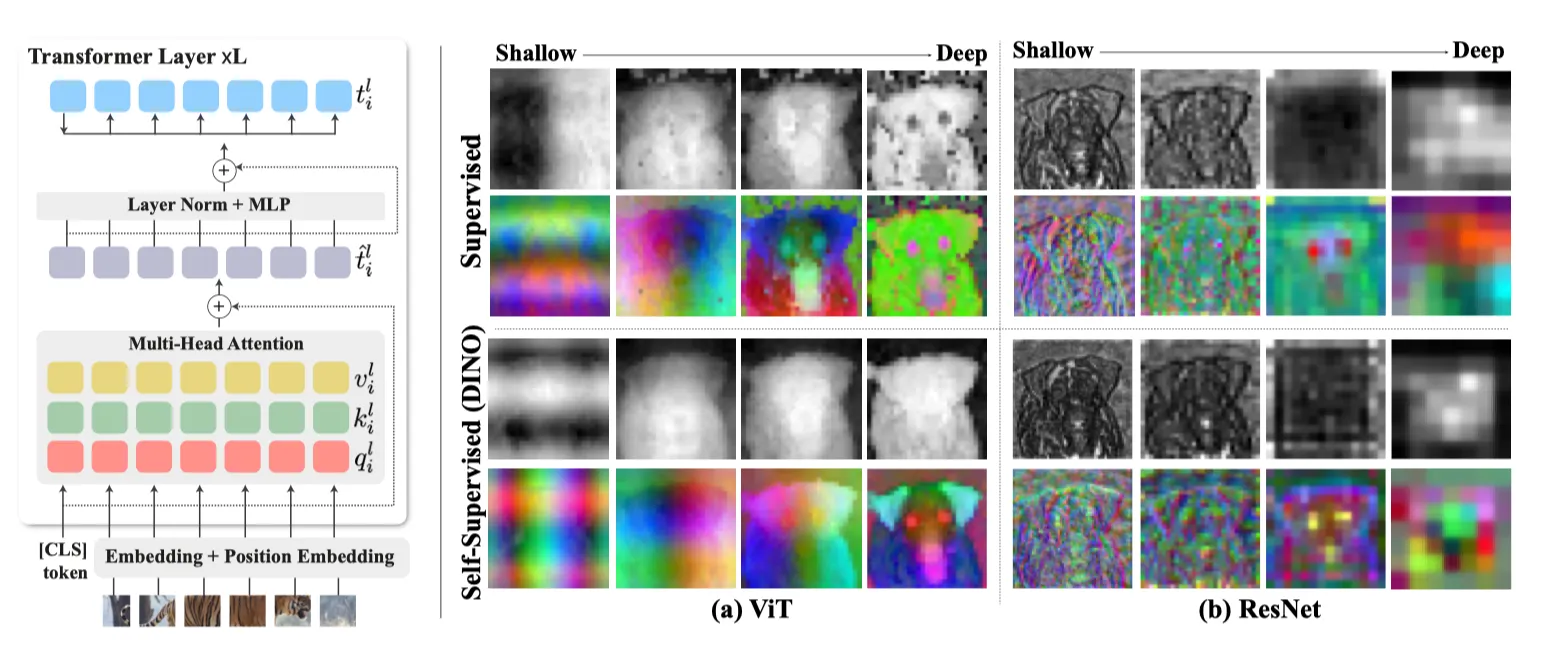
(좌) ViT 구조. (우) a) ViT Feature와 CNN Feature의 비교. 각 레이어의 Feature를 PCA 시각화 하였다.
•
Semantics vs. spatial granularity
(a) CNN은 공간 해상도와 더 깊은 레이어의 의미 정보를 교환하는 모습을 볼 수 있습니다. 가장 깊은 레이어의 Feature Map은 해상도가 매우 낮기 때문에 따라서 지역화된 Semactic 정보를 제대로 제공하지 못합니다.
(b) ViT는 모든 레이어를 통해 동일한 공간 해상도를 유지합니다. 또한 ViT의 Receptive Field는 모든 계층의 전체 이미지입니다. 즉, 각 토큰 은 다른 모든 토큰 에 attend 하게 됩니다. 따라서 ViT 기능은 세분화된 시맨틱 정보와 더 높은 공간 해상도를 제공한다.
•
Representations across layers.
◦
(a) CNN 기반 Feature는 계층적인 표현 구조를 갖는다는 것은 잘 알려져 있습니다. 즉, 얕은 레이어들은 Edge, Texture등을 캡쳐하는 반면 깊은 레이어는 Semantic한 정보나 high level concept들을 캡쳐합니다.
◦
(b)ViT는 얕은 레이어는 대부분 Positional Information (위치 정보)를 포함하는 반면, 더 깊은 층에서는 위치정보가 감소하고 Semantic 정보들을 캡쳐합니다. 그림 (a)를 보면, 깊은 특징은 개의 파트와 배경을 구분하는 반면 얕은 레이어의 Feautre는 공간적 정보를 담고있는 것을 볼 수 있습니다. 흥미로운 것은, 중간 레이어의 Feature는 위치 정보와 의미 정보를 모두 포함한다는 것입니다.
•
Semantic information across super-classes.
◦
(a-상단) Supervised ViT Feature는 (b-하단) Self-supervised ViT Feature에 비해 더 “Noisy”한 Feature를 만듭니다. 이는 아래 결과를 보면 더 직관적으로 이해가 됩니다.
Properties of ViT’s Features
저자는 Supervised 방식의 ViT와 Self-supervied 방식의 DINO-ViT 에 대해 분석했습니다. 는 다음과 같습니다.
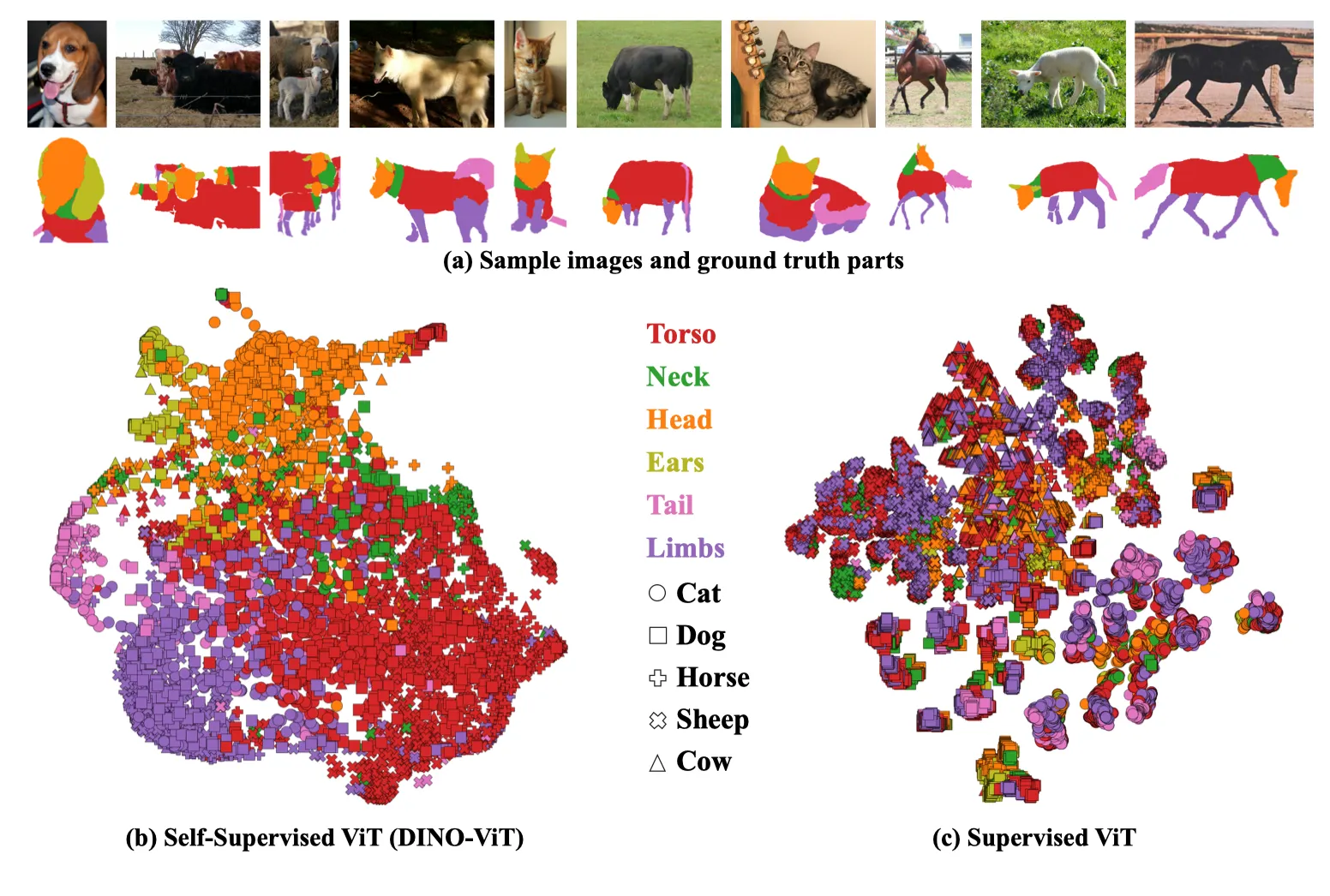
5개 클래스 50개의 동물 이미지에 대해 ViT Feauture를 얻은 후 (최종 출력의 key), t-SNE시각화 한 결과.
이를 살펴보자면, (b) DINO-ViT Feature는 서로 다른 카테고리임에도 (!) 각 파트에 대한 semantic similarity를 잘 표현한 반면 (c) supervised ViT의 경우 클래스에 대한 similarity, 즉 global 정보에 집중하는 모습을 볼 수 있습니다.
•
ViT Feature의 특징
◦
최종 레이어 출력에서는 K가 Q, V에 비해 더욱 나은 representation을 제공합니다.
◦
중간 레이어 출력에서는 K, Q가 V, Token보다 더 많은 positional bias를 포함합니다.
◦
이는 ablation 실험 결과에서 볼 수 있습니다. 좀 땡겨오겠습니다.

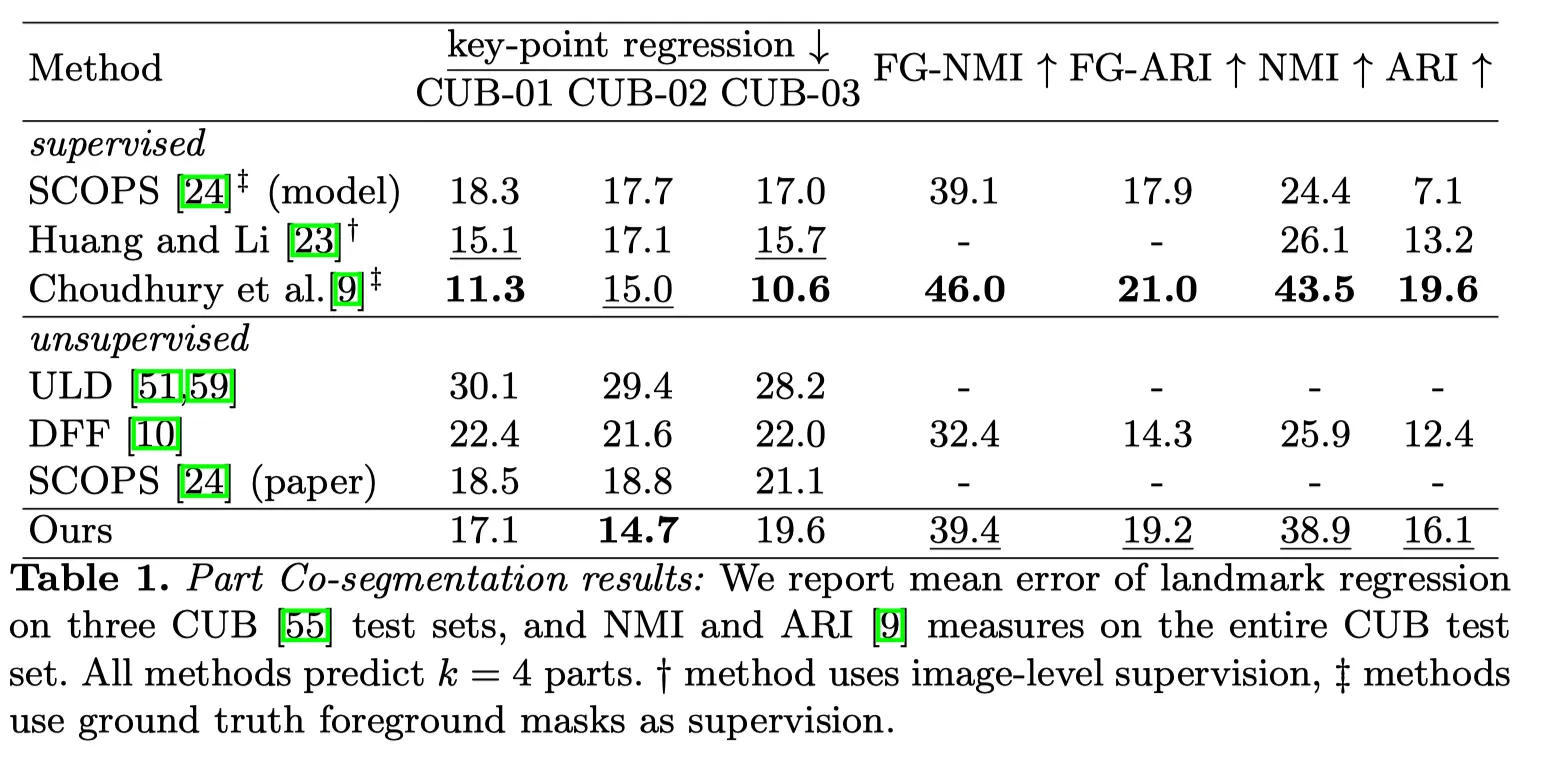
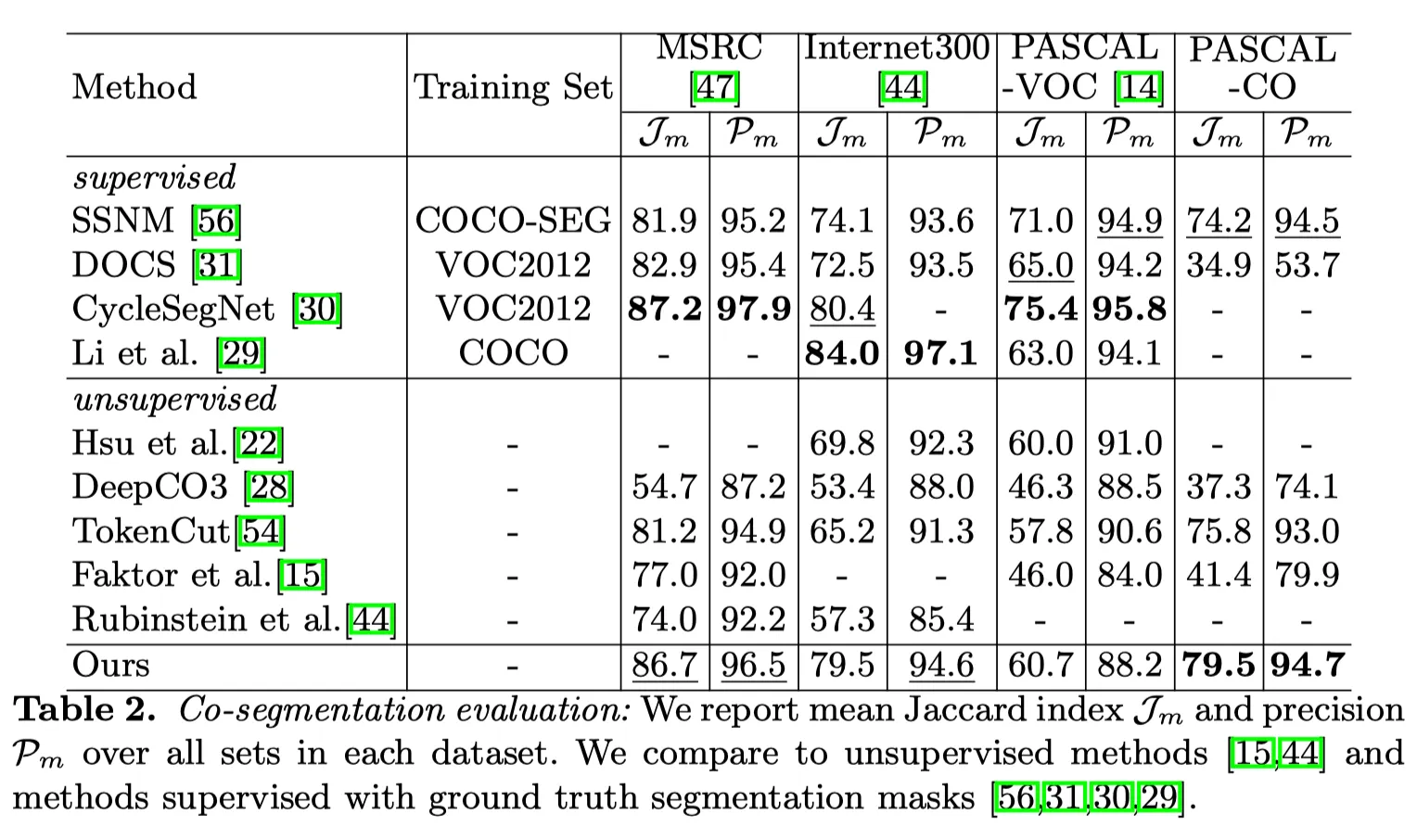
위 표를 보면, Key를 사용하는 것이 Q, V, Token을 사용하는 것 보다 더 나은 결과를 보여줍니다.
Experimental Results
논문에서 제시한 방법론은 다양한 시각 작업에 대해 광범위한 실험을 통해 검증되었습니다. 공동 분할, 부분 공동 분할, 의미적 대응 작업에서 최신 감독 방법과 비교하여 경쟁력 있는 결과를 보여주었으며, 특히 비감독 방법에 비해 뛰어난 성능 향상을 보였습니다. 이러한 결과는 ViT가 단순히 이미지 분류뿐만 아니라 더 복잡한 시각적 이해 작업에도 유용하게 활용될 수 있음을 시사합니다.
Part Co-segmentation
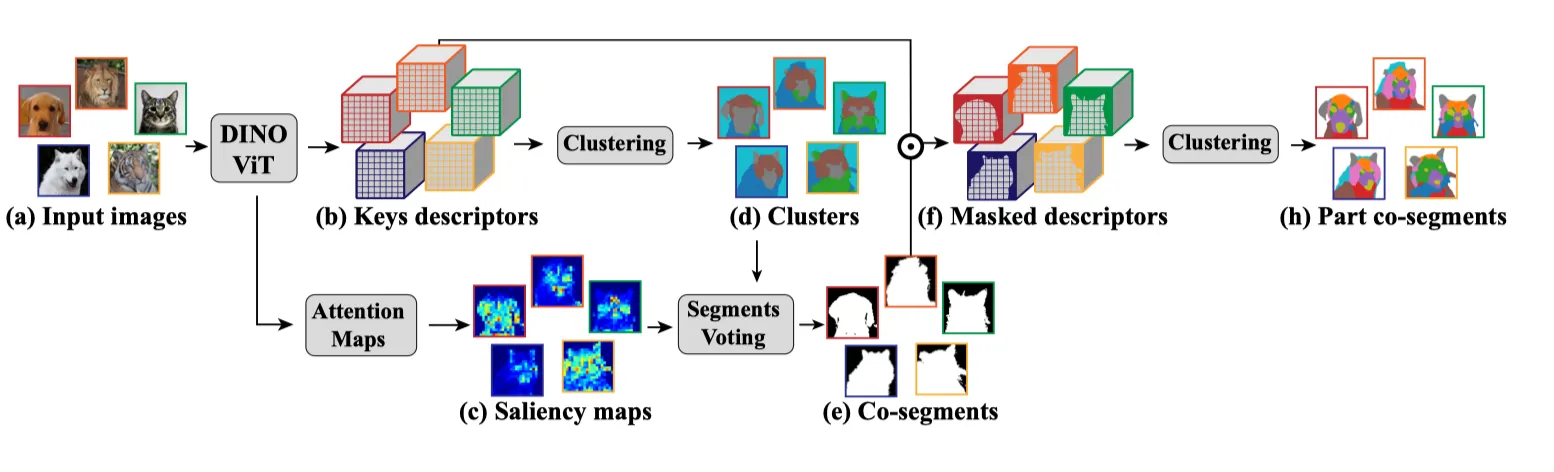
Part Co-segmentation은 몇장의 이미지들 사이에서 유사한 부분을 분할하는 task입니다. 저자는 ViT Feature을 이용해 이 문제를 해결하려고 했습니다. 접근 방법은 다음과 같습니다.
1.
Clustering: 모든 이미지에 대해 descriptor를 추출하고 이를 모아 (bag-of-descriptors) K-means 클러스터링을 수행했습니다.
2.
Voting: 클러스터들 사이에서 중요한 클러스터를 선별하기 위해 Voting을 수행합니다.
이미지 I에 대한 패치 i가 있을때, 를 mean [CLS] attention이고 는 클러스터 k에 속하는 이미지 I 의 패치 Set이라고 하면 Segment 의 saliency는 다음과 같습니다.
각각의 segment는 클러스터 k의 saliency에 voting을 합니다.
3.
Vote(k) 가 percentage p보다 크다면, foreground 로 간주합니다.
여기까지 Co-Segmentation을 수행하게 됩니다.
4.
Part co-segmentation을 수행하기 위해, multi-label CRF를 refine했습니다.
cluster의 갯수를 결정하기 위해 elbow method 를 사용했습니다.

(좌) Input. (중) Co-segmentation. (우) Part Co-segmentation.


Point Correpondences
이 task는 두 이미지 사이에서 matching point를 찾는 것입니다.
에서는 semantic information이 덜 중요하고 positional 정보가 더욱 중요한데, 저자는 이를 반영하기 위한 두가지 방법을 제안합니다.
1.
Positional Bias: descriptor는 position-aware 해야하므로 중간 레이어의 Feature를 사용합니다. 적절한 레이어의 선택은 position정보와 semantic 정보 사이의 trade-off를 제공합니다.
2.
Binning: 인접한 공간적 특징의 정보를 통합함으로써 context를 각 descriptor에 통합하기 위해 각 spatial feature에 log-binning을 적용합니다.
3.
“Best Buddies Pairs“ (BBPs): 두 이미지 사이에 매칭점을 찾습니다. 이를 위해 두 이미지의 표현자 사이에 mutual Nearest Neighbor를 찾습니다.
•
: 이미지 M, Q의 binned descriptor set.
•
4.
Resolution Increase: ViT는 이미지를 패치로 쪼개 받아들이므로, 공간적 해상도에 제약이 있습니다. 이를 해결하기 위해 patch를 정의할 때 non-overlapping이 아닌 overlapping patch를 사용하고 position encoding은 interpolate합니다.

NBB 방법과 비교

Leverage Deep ViT features to automatically detect semantically corresponding points between images from different classes, under significant variations in appearance, pose and scale.

Video Part Co-segmentation
더욱 많은 실험 결과는 아래에서 제공합니다.
Conclusion
Strength
•
ViT에서 추출된 깊은 특징들이 고해상도의 의미 정보를 지역화하여 인코딩할 수 있다는 것을 밝혀냈습니다.
•
제로샷 방법론을 통해 추가적인 데이터 없이도 다양한 시각 작업을 수행할 수 있음을 입증했습니다.
•
Supervised 방법과 비교하여 경쟁력 있는 성능을 달성했으며, 기존의 방법보다 우수한 결과를 보여주었습니다.
Weakness
•
데이터 효율성: ViT는 일반적으로 많은 양의 데이터를 필요로 합니다. 이는 ViT가 효과적으로 훈련되기 위해 많은 예제를 필요로 하기 때문입니다. 이 연구에서는 추가 훈련이나 데이터 없이도 ViT 특징을 직접 적용하는 경량의 제로샷 방법론을 사용하고 있지만, 이 방법론이 모든 시나리오에서 최적의 결과를 낼 수 있는지는 불분명합니다.
•
일반화 문제: 연구에서는 다양한 도메인에 걸쳐 일관된 부분 세분화를 달성하는 것을 보여주고 있지만, 이러한 방법이 모든 도메인이나 시나리오에서 동일하게 잘 작동할지에 대한 질문은 남아 있습니다. 특히, 훈련 데이터가 부족한 도메인에서의 성능은 더욱 불확실할 수 있습니다. (e.g., MRI영상, 위성영상)
•
사전 훈련된 모델에 대한 의존성: 특징의 품질과 방법의 성공이 사전 훈련 모델의 품질에 의존적입니다.
•
계산 자원의 필요성: ViT의 Self-attention 연산은 높은 계산 자원을 요구하며 이로 인한 적용 범위의 제한이 있을 수 있습니다.
•
이론적 근거: 더 높은 공간 해상도를 얻기 위해 overlapping 패치를 추출하고 그에 따라 위치 인코딩을 보간하는 방법을 사용합니다. 이는 추가 훈련 없이도 작동하지만, 이 방법이 모든 실험에서 잘 작동하는지에 대한 경험적 증거만 제시되고 있습니다.