CoCosNet: Cross-domain Correspondence Learning for Exemplar-based Image Translation



Style Image (Examplar) + Condition ⇒ Image Synthesis
•
스타일 이미지 (Examplar)와 다양한 종류의 Conditional Input (Semantic map, pose, edge, layout 등)을 이용하여 새로운 이미지를 생성한다.
•
기존의 SPADE류 방법들은 VAE에 기반한 반면,
•
이 논문은 Input Condition과 Examplar간의 Correlation을 구한 후 modulation parameter를 구하는 StyleGAN 프레임워크로 접근했다는 것이 특징이다.
•
Generator의 옆구리에서 AdaIN 파라메터가 들어가므로 성능이 더 좋을 수 밖에 없다.
Intro & Overview
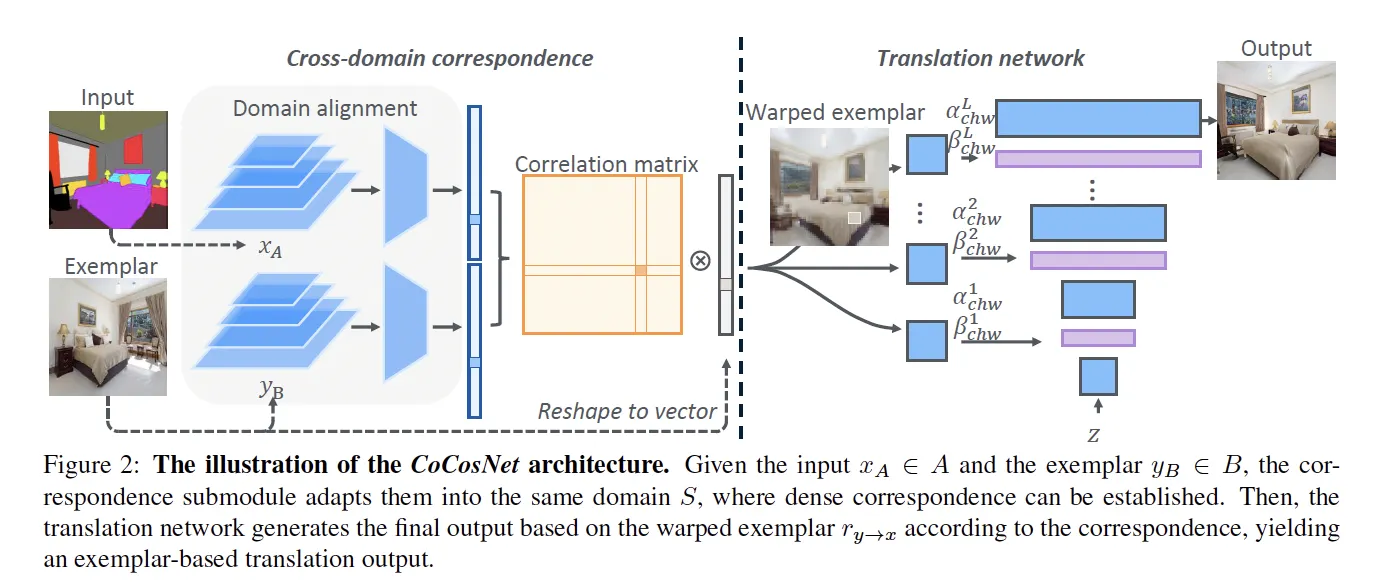
1.
Examplar와 Input간의 관계를 고려하기 위해, Domain Alignment와 Correlation matrix를 구한다.
2.
이에 기반하여 Examplar를 Condition에 맞도록 warping해준 후,
3.
Warp된 examplar로부터 SPADE처럼 modulation parameter를 구해 Image를 Synthesis한다.
•
이 논문의 Contribution은 Examplar와 Condition간의 Correlation을 구한다는 점이다.
◦
기존 SPADE류의 방법은 Style을 입히기 위해 Style Image를 Encoder로 인코딩하여 parameter mu와 sigma를 구한 후, 이 Source Distribution으로부터 sampling하여 Generator의 Input으로 넣어주었던 것과 달리
◦
두 이미지를 함께 Encoding하고 correlation을 구한 후 warp해준 뒤 StyleGAN처럼 접근했다는 방식이 참신했다.
Methodology
Cross-domain correspondence network
Corresondence within shared domain
Translation network
Losses
1.
Losses for pseudo examplar pairs
2.
Domain alignment Loss
•
KL Divergence loss 가 더 좋지 않을까?
3.
Examplar translation losses
3-1. Perceptual Loss
3-2. Contextual Loss
4.
Correspondence regularization
where : forward-backward warping image.
5.
Adversarial Loss
where : hinge function to regularize the .
•
Total Loss
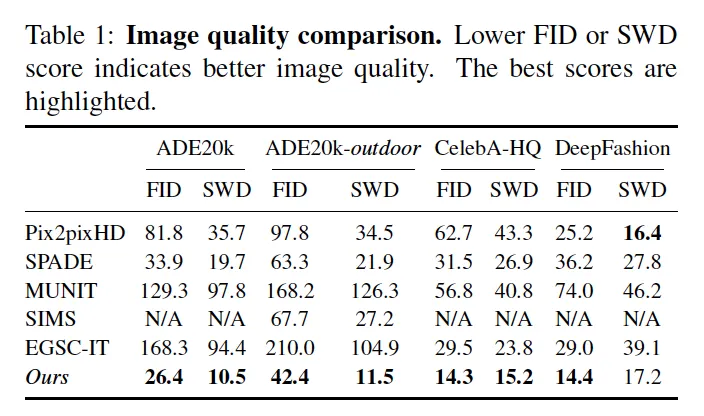
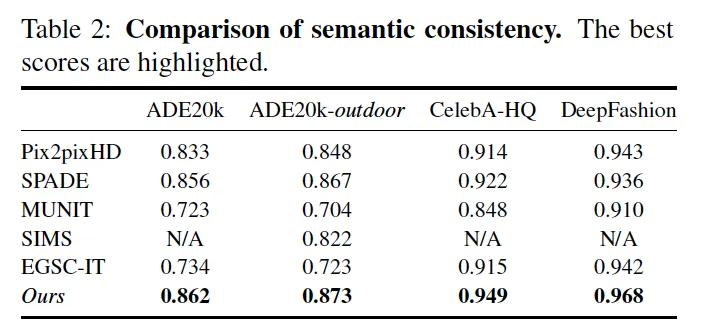
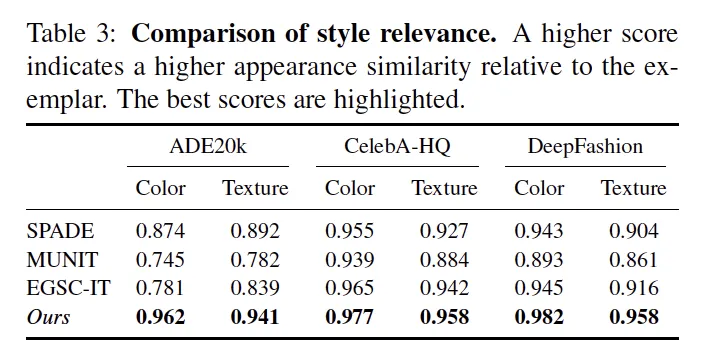
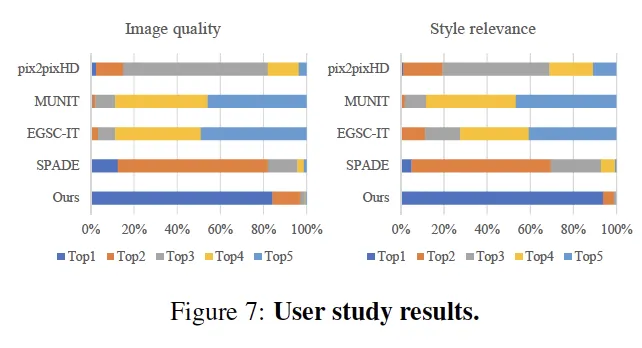
Experimental Results
Datasets
•
ADE20k (Segmentation → indoor image)
◦
코드를 돌리면서 얘때문에 엄청 고생했다.
ADE20k 공홈에서 받으면 안되고, ADEChallenge2016이라는 데이터셋 (Annotation이 흑백이다.) 을 구해서 돌려야 된다. (근데 논문에는 ADE20k로 들어가 있다..)
•
ADE20k-outdoor (Segmentation → outdoor image)
◦
ADE20k의 subset이다.
•
CelebA-HQ (Edge → face image)
◦
Canny Edge Detector를 사용해 Edge를 추출 후 Edge to Image Task를 수행했다.
•
Deepfasion (Pose → Image)
•
Lsun Bedroom (Segmentation → indoor image)
◦
다른 연구와는 달리 LSUN Bedroom은 쓰이지 않았다.