
DIFT: Emergent Correspondence from Image Diffusion
•
이 논문은 이미지 간 대응 관계 (Correspondence)를 찾는 컴퓨터 비전 문제를 다룹니다.
•
저자들은 확산 모델 (Diffusion Models) 이 명시적인 감독 없이도 이미지 대응을 학습할 수 있음을 보여주고, 이를 위한 DIffusion FeaTures(DIFT)를 제안합니다.
•
DIFT는 추가적인 데이터나 주석 없이도 다양한 대응 작업에서 탁월한 성능을 보여줍니다.
1: Intro & Overview
이미지 간 대응 관계를 찾는 문제는 컴퓨터 비전에서 매우 중요한 연구 주제입니다. 이는 이미지 검색, 객체 인식, 증강 현실 등 다양한 응용 분야에서 필수적입니다. 최근의 연구는 이미지의 특징을 추출하여 이들 간의 관계를 파악하는 데 중점을 두고 있으며, 특히 딥러닝 기술의 발전과 함께 더욱 정교한 방법들이 제안되고 있습니다.
이 논문에서는 확산 모델을 활용한 새로운 접근법을 제안합니다. 저자들은 명시적인 감독 없이도 확산 모델이 이미지 간 대응 관계를 학습할 수 있음을 보여주고, 이를 기반으로 한 새로운 방법론인 DIffusion FeaTures(DIFT)를 소개합니다. DIFT는 추가적인 데이터나 주석 없이도 다양한 대응 작업에서 탁월한 성능을 보이며, 이는 기존의 방법들과 비교해 큰 혁신이라 할 수 있습니다.
2: Prelinamaries
2.1: Image Correspondence
이미지 대응 문제 (Correspondence)는 두 이미지 가 주어졌을 때, 의 픽셀 위치 에 대응하는 의 픽셀 위치 를 찾는 문제입니다. 이 때 대응관계는 기준에 따라 3가지 분류로 나눌 수 있습니다.
•
의미적 대응(Semantic Correspondence): 유사한 의미를 가진 서로 다른 객체의 픽셀
•
기하학적 대응 (Geometric Correspondence): 다른 시점에서 촬영된 동일한 객체의 픽셀
•
시간적 대응 (Temporal Correspondence): 시간이 지나며 변형될 수 있는 비디오 속 동일한 객체의 픽셀
가장 간단하게 대응관계를 찾는 방법은 다음과 같습니다.
1.
특징 추출: 주어진 이미지들의 dense features를 추출합니다. (
이때, 픽셀 에 대한 Feature는 Bilinear Interpolation으로 구할 수 있습니다. ()
2.
특징 매칭: 두 Feature들의 대응관계를 찾습니다. 한 픽셀의 Feature와 가장 유사한 점을 찾게 됩니다.
이때, 는 distance metric으로 cosine distance를 사용합니다.
기존에 좋은 성능을 내는 방법들은 대조 자가 지도 학습 기법 (Contrastive Self-supervised Learning Techniques)을 사용했습니다.
•
DINO
•
OpenCLIP
Contrastive Self-supervised Learning 방식의 기존 연구와는 다른 새로운 접근방법을 제안했습니다. 바로 확산 모델 (Diffusion Models)를 사용하는 것입니다.
2.2: Diffusion Models
확산 모델은 주어진 이미지에 점진적으로 노이즈를 추가하고, 이를 역방향으로 제거하며 원본 이미지를 재구성하는 과정에서 이미지의 특징을 학습합니다. 이 과정에서 모델은 다양한 타임스텝에서의 이미지 정보를 활용하여 고유한 특징을 추출할 수 있다는 점을 이용하여 Correspondence 문제를 풀려고 합니다.
3: Methodology
3.1: DIffusion FeaTures (DIFT)
저자는 먼저 확산 모델은 Correspondence를 implicit하게 학습한다는 점을 강조합니다. (PnP, pix2pix-zero) 그렇다면 이로부터 어떻게 Correspondence를 추출할 수 있을까요?
3.2: Extracting Diffusion Features on Generated Images.
먼저 Stable Diffusion을 통해 생성된 이미지간 대응관계를 찾는 문제를 생각해보겠습니다. Gaussian 노이즈로부터 출발하여 점차적으로 denoising을 하며 이미지를 생성하는 과정(Backward Process)을 통해, 우리는 이미지의 모든 중간 단계를 이용할 수 있습니다. 따라서 중간 타임스텝 의 feature map을 추출하고 correspondence를 찾게 되면 굉장히 정확한 대응관계를 찾을 수 있습니다.

Stable Diffusion으로 생성된 이미지에서 특정 시간 단계 t에서 역방향 과정 중간 층 활성화를 추출하여 해당 지점을 예측하는 특징 맵으로 사용합니다. 이 간단한 방법은 동일 범주뿐만 아니라 범주 간, 심지어 사진에서 유화로 넘어가는 교차 도메인 상황에서도 올바른 대응 관계를 생성합니다. credit: DIFT Paper.
3.3: Extracting Diffusion Features on Real Images.
그렇다면 이러한 방법을 실제 이미지에도 바로 응용할 수 있을까요? 하지만 이것은 어렵습니다. 왜냐하면 사전학습된 U-Net은 de-noise를 학습했기 때문에 noisy 이미지에 대해서만 동작하기 때문입니다. 즉, 확산 모델의 Backward Process의 중간단계인 노이즈 이미지들을 알 수 없기 때문이죠. (Access가 불가능)
이러한 문제를 극복하기 위해 저자는 아주 간단한 방법을 취했습니다. 바로 입력 영상에 노이즈를 더하는 것입니다. 타임스텝 에 대해 노이즈를 얻어 의 노이즈 이미지를 얻습니다. 이는 확산 모델의 Forward Process를 재현하는 것과 동일합니다. 그리고 네트워크 에 타임스텝 와 함께 통과시켜 각 레이어의 activation들을 얻을 수 있습니다. 이러한 간단한 방법만으로도 굉장히 좋은 대응관계를 알아낼 수 있었습니다.

이미지의 가장 왼쪽에 있는 빨간 출발점을 기준으로 오른쪽 이미지에서 해당하는 지점을 찾습니다. 미세 조정이나 대응 관계 감독 없이, 제안된 확산 특징(DIFT)은 인스턴스, 범주, 심지어 도메인 간에도 의미적 대응 관계를 설정할 수 있습니다. 예를 들어, 오리에서 펭귄으로, 사진에서 유화로의 전환에서도 정확한 대응을 찾아낼 수 있습니다. credit: DIFT Paper.
그렇다면, 여기서 두가지 질문을 할 수 있습니다.
1.
어떤 timestep 를 사용해야 할까?
2.
어떤 레이어 을 사용해야 할까?
저자는 2D Grid Search를 통해, 아래와 같은 성질을 찾아냅니다.
1.
timestep : 가 클수록 semantically-aware feature, 가 작을때는 low-level details.
2.
layer : 앞쪽일 수록 semantically-aware feature, 뒤쪽일 수록 low-level details.
이러한 trade-off는 Correspondence의 종류에 따라 적절한 와 을 다르게 선택해야 한다는 뜻입니다.
•
Semantic Correspondence:
•
Geometric Correspondence:
마지막으로, 입력 이미지에 추가된 랜덤 노이즈가 있는 상황에서도 표현의 안정성을 높이기 위해, 여러 노이즈 샘플로 생성된 다양한 노이즈 버전에서 특징을 추출하고 이를 평균화하여 최종 Feature를 형성합니다.
4: Experiments
DIFT의 성능을 검증하기 위해 저자들은 다양한 벤치마크 데이터셋에서 실험을 수행했습니다.
먼저 DIFT를 추출하기 위해 두가지 확산모델을 사용했습니다. 이때 DIFT는 어떠한 fine-tuning, re-training을 하지 않았습니다. 한편 학습 데이터에 대한 편향을 제거하기 위해 두가지 베이스라인 모델을 준비합니다.
•
DIFT Backbones
◦
Stable Diffusion (SD): LAION Dataset에 대해 학습.
◦
Ablated Diffusion Model (ADM): ImageNet에 대해 라벨링 없이 학습.
•
Baseline Methods
◦
OpenCLIP: ViT-H/14. LAION 학습.
◦
DINO: ViT-B/8. ImageNet에 라벨링 없이 학습.
•
Benchmark Dataset
◦
SPair-71k: 가장 어려운 Semantic Correspondence 데이터셋. 12,234 pairs, 18 categories.
◦
PF-WILLOW: PASCAL VOC의 subset. 900 pairs.
◦
CUB-200-2011: 14종류에 대해 25 pairs.
•
Evaluation Metrics
◦
PCK: Percent of correct keypoints.
◦
PCK per point:
◦
PCK per image: 이미지당 PCK를 계산 후 전체 데이터셋에 대한 평균
4.1: Semantic Correspondence
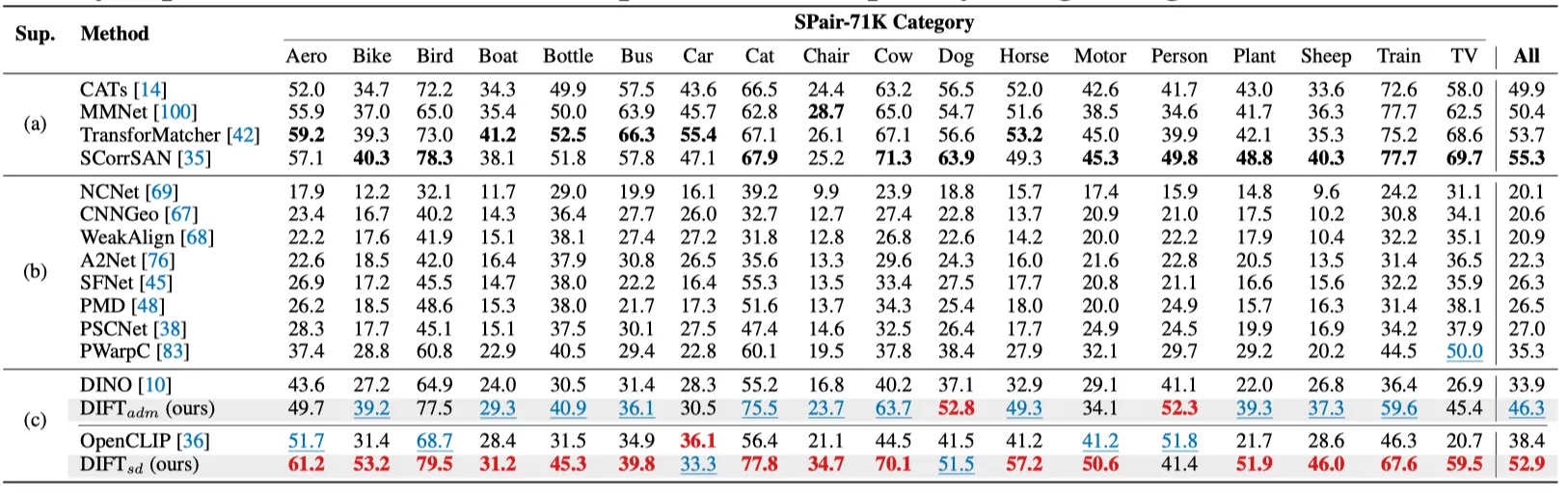
PCK( per image on SPair-71k Dataset. (a) Fully-supervised (b) weakly-supervised (c) no supervision.

PCK( per point on SPair-71k Dataset. (b) weakly-supervised (c) no supervision.
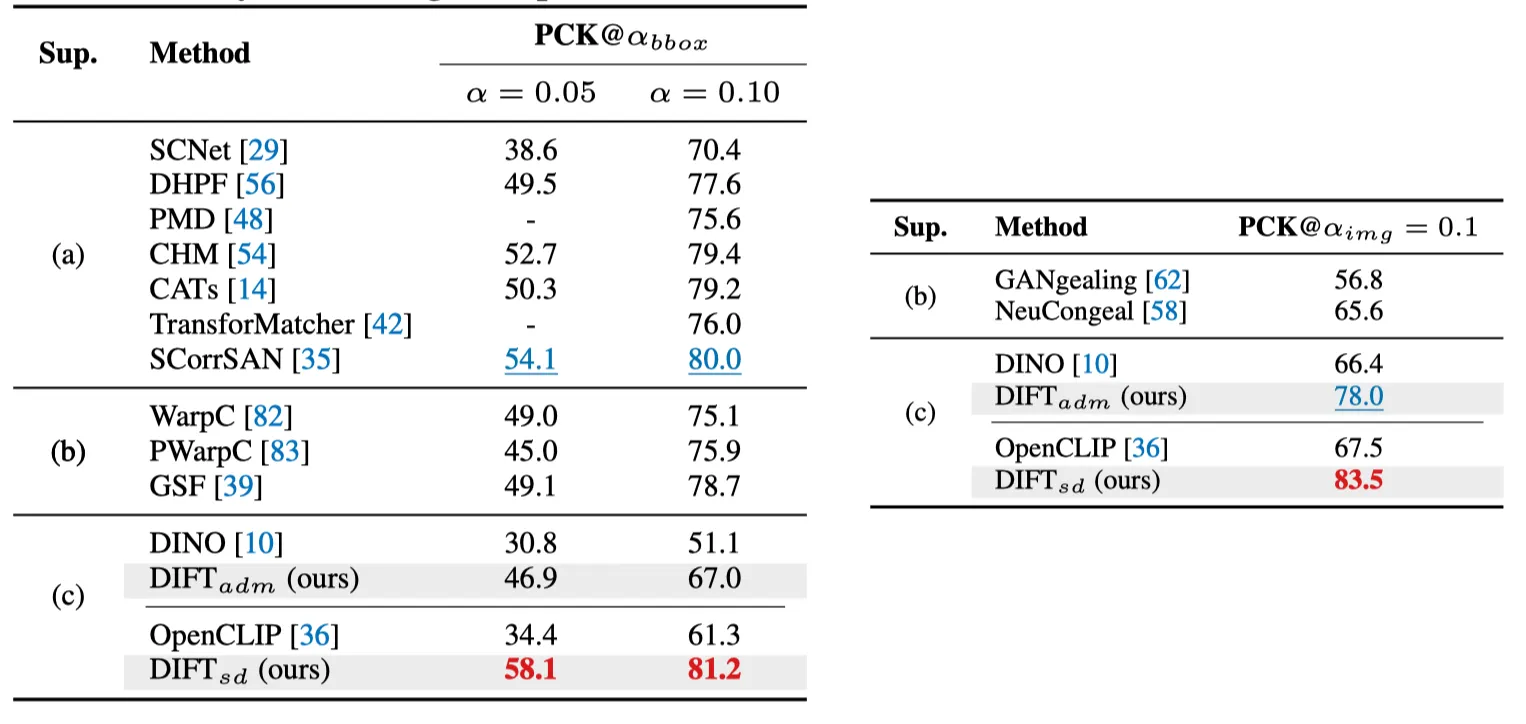
PF-WILLOW PCK per image (left) and CUP PCK per point (right).
•
실험 결과, supervision이 없음에도 불구하고 (b) weakly-supervised (c) no supervision 방법들을 능가합니다. 심지어 (a) Fully-supervised 방법들을 능가하거나 비슷한 성능을 보입니다.

Qualitative Result. SPair-71k. Semantic Correspondence. Credit: DIFT Paper
•
가장 왼쪽 이미지는 키포인트가 있는 소스 이미지이며, 가장 오른쪽 이미지는 타겟 이미지에 대한 정답입니다.
•
중간 이미지는 다양한 특징 매칭을 사용하여 찾은 키포인트를 포함합니다. 다른 색상은 다른 키포인트를 나타내며, O은 정확히 예측된 점을, X는 잘못된 매칭을 나타냅니다.
•
DIFT는 다른 방법들에 비해 어려운 환경에서도 좋은 성능을 보입니다.
(복잡한 장면 (3행), 시점 변화 (4행), 인스턴스 수준의 외관 변화 (5행))

Qualitative Result. SPair-71k. Cross-category Semantic Correspondence. Credit: DIFT Paper
•
가장 왼쪽 이미지에서 지정된 이미지 패치(빨간 사각형)를 기준으로, 다른 카테고리 이미지의 유사한 부분을 찾습니다. DIFT를 사용하여 SPair-71k 테스트셋의 다른 카테고리 이미지에서 상위 5개의 가장 유사한 패치를 검색합니다. DIFT는 유사한 의미적 부분을 공유하는 서로 다른 객체에 대해 올바른 대응을 찾을 수 있습니다.
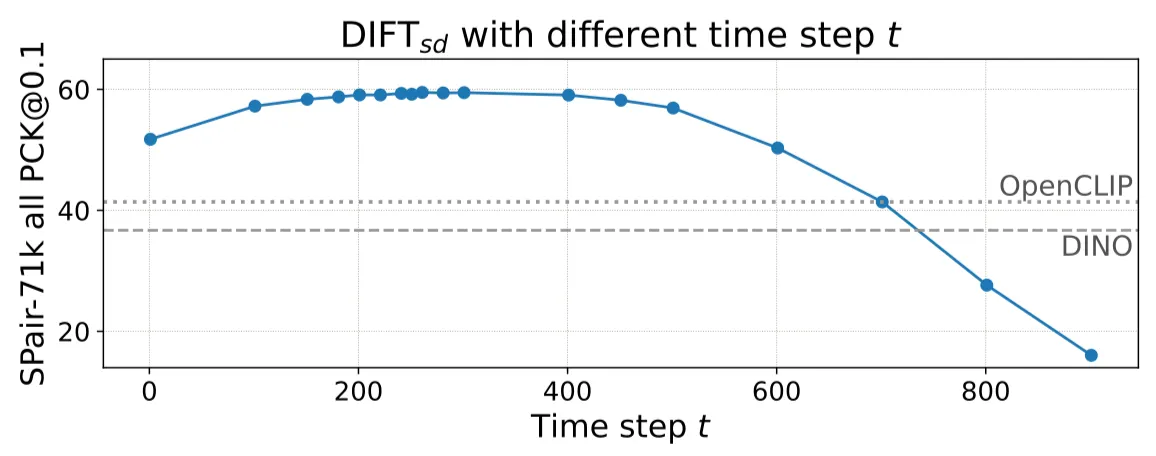
PCK per point of DIFT sdon SPair-71k. 넓은 범위의 t에 대해 좋은 성능을 나타냅니다.
•
Semantic Correspondence에서 가장 좋은 성능을 보이는 를 찾습니다.
•
Semantic correspondence는 넓은 범위의 에 대해 잘 작동합니다. (robustness)
4.2: Edit Propagation
위에서 찾아낸 DIFT의 Semantic correspondence 성질을 이용하여 이미지 Editing에 적용해보았습니다.
목적은 A와 B의 transformation을 찾은 후, 한 이미지 A에 붙인 스티커를 변환하여 이미지 B에 붙여보는 것입니다.
•
두 이미지간의 매칭점을 찾습니다.
•
•
찾아낸 transformation에 대해 이미지 A의 스티커를 B로 transform합니다.
•
B에 붙여봅니다.

Edit propagation. Credit: DIFT.
4.3: Geometric Correspondence
Geometric Correspondence는 Semantic에 비해 더 지엽적인 대응관계입니다. t가 작을 수록 DIFT는 low-level feature에 집중합니다.
•
Benchmark
◦
HPatches benchmark: 116 시퀀스 (57 illumination change, 59 viewpoint change.)
◦
각 이미지에 대해 1,000개의 키포인트를 추출 후 cv2.findHomography() 를 통해 mutual nearest neighbor matches를 찾음.
•
Baseline Methods
◦
SuperPoint, CAPS
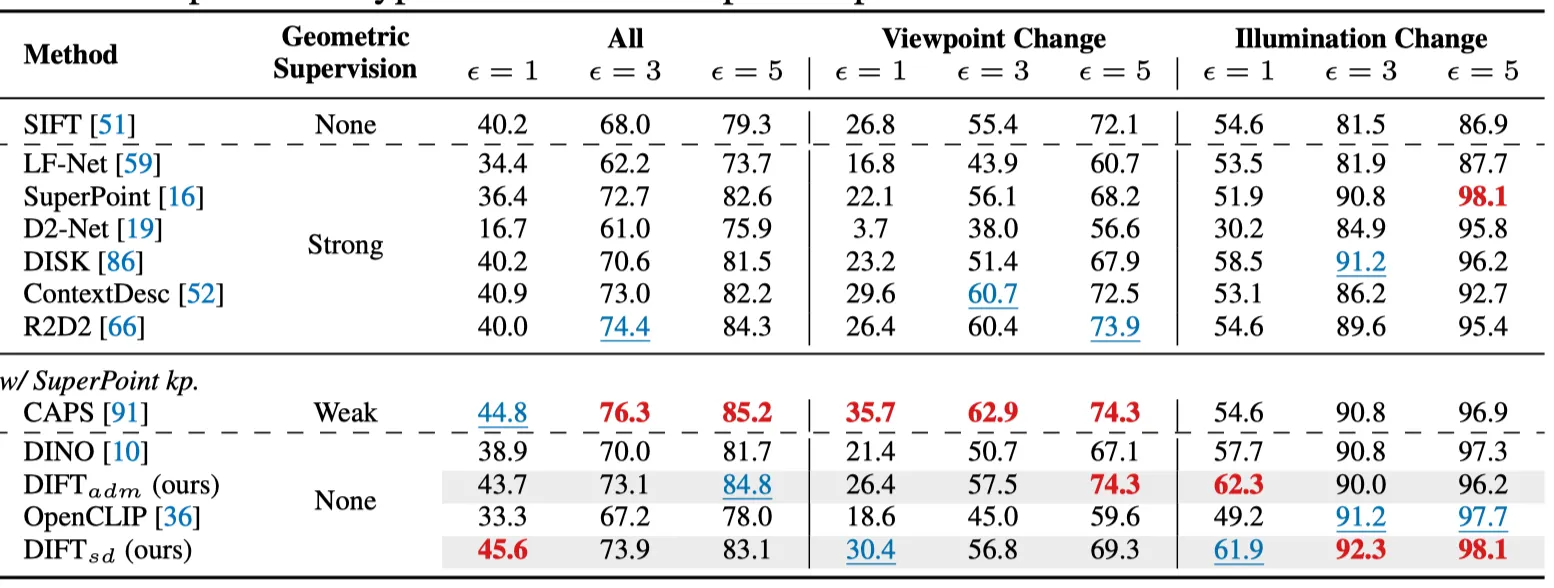
Homography estimation accuracy [%] at 1, 3, 5 pixels on HPatches.

Sparse feature matching using on HPatches after removing outliers with cv2.findHomography().
4.4: Temporal Correspondence
비디오에서 각 프레임간의 Correspondence를 찾아봅니다. Object Segmentation, Pose Tracking관련이 있습니다.
•
Dataset
◦
DAVIS-2017 : Video Segmentation benchmark.
◦
JHMDB : Keypoint estimation benchmark.
•
Evaluation Metrics.
◦
DAVIS-2017: Region-based similarity , Contour-based accuracy
◦
JHMDB: PCK
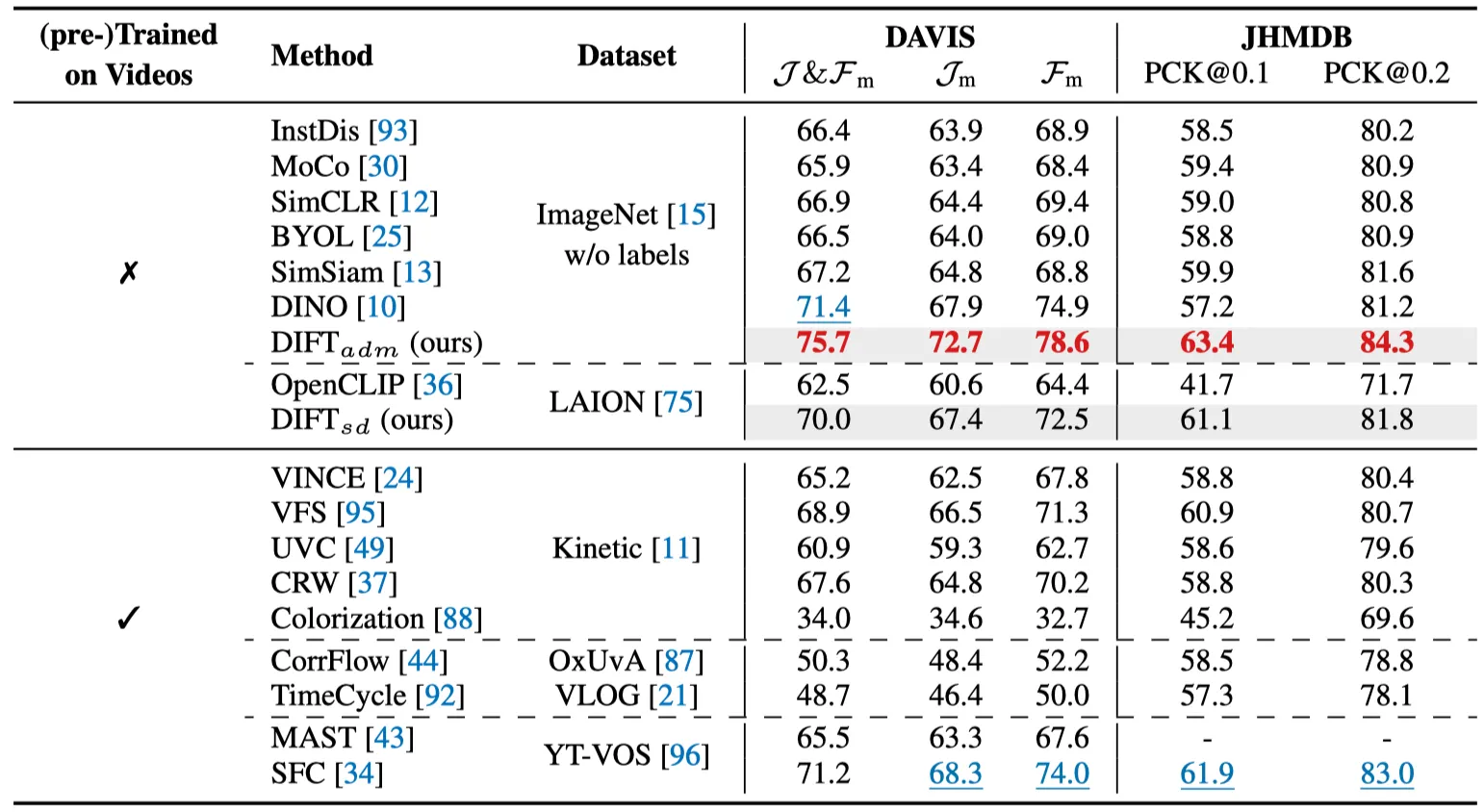
Video label propagation results on DAVIS-2017 and JHMDB.

Video label propagation results on DAVIS-2017. 파란색: 첫 프레임.
Discussions

Diffusion Inversion이 도움될까?
•
를 구하기 위해 단순히 노이즈를 더하는 것이아닌 DDIM Inversion등을 사용할 수 있다.
•
그 결과 성능향상은 크게 없었고, 연산량만 늘어났다.
•
Inversion을 사용한 후속연구를 기대해볼 수 있을것이다.
VAE Encoder에 correspondence information이 존재하는가?
•
SD의 VAE 인코더의 feature에 대해 performance를 조사해보았는데, 모든 면에서 성능이 낮았다.
•
따라서 DIFT는 diffusion-based training이 필요하다.
task-specific adaptation이 더 좋은 성능을 이끌어낼 수 있는가?
•
충분히 가능하다. 예를 들어, 네트워크 와이어링의 변경, task-specific supervision을 이용한 finetuning, 별도의 Head 부착 후 학습 등이 가능하다.
•
하지만 저자가 제안하는 방법과 결합할 경우 그 효과가 명확히 드러나지 않을 수 있다. DIFT의 효과를 강조하기 위해 adaptation은 최대한 피했다.
•
하지만 이러한 조정은 많은 성능을 향상시킬 여지가 있다.
Contributions & Limitations
Contributions
1.
혁신적인 접근법: 확산 모델을 활용한 이미지 대응 방법론을 제안하여, supervision 없이도 높은 정확도를 달성할 수 있음을 입증했습니다.
2.
실험적 검증: 다양한 벤치마크 데이터셋에서 DIFT의 우수한 성능을 검증했습니다.
3.
범용성: 추가적인 데이터나 주석 없이도 다양한 이미지 대응 작업에 적용할 수 있는 범용적인 방법을 제시했습니다.
Limitations
1.
특정 작업에 최적화된 하이퍼파라미터 설정이 필요합니다. 이는 모델의 일반화 가능성에 영향을 미칠 수 있으며, 다양한 작업에 적용하기 위해서는 추가적인 조정이 필요합니다.
2.
모델의 복잡성으로 인해 학습 및 추론 과정에서 많은 계산 자원이 필요할 수 있습니다. 이는 실제 응용에서의 효율성 문제를 제기할 수 있습니다.
Conclusions
이 논문은 컴퓨터 비전 분야에서 이미지 간 대응 관계를 자동으로 찾아내는 혁신적인 접근법을 제시합니다. DIFT는 다양한 조건에서 이미지 대응 작업의 정확도를 높일 수 있는 강력한 도구로, 향후 연구 및 실용적 응용에서 중요한 역할을 할 것입니다. 특히, 추가적인 데이터나 주석 없이도 높은 성능을 발휘할 수 있다는 점에서, 다양한 실제 문제에 적용할 수 있는 잠재력을 가지고 있습니다. 향후 연구에서는 DIFT의 한계를 극복하고, 더 나아가 다양한 응용 분야에서의 활용 가능성을 탐구하는 방향으로 나아가야 할 것입니다.