Real-Time High-Resolution Background Matting

CVPR 2021: 7,093 Submitted, 4,312 Rejected, 1,047 Withdrawned, 1,660 Accepted (23.6%)
Best Student Paper!
Introduction


30fps in 4K resolution
60fps for HD on a modern GPU.
•
영화에서 사용되는 특수 효과의 주축을 이루는 백그라운드 교체가 이제 Zoom, Google Meet, Microsoft Teams와 같은 화상 회의의 도구에서 광범위하게 사용되고 있다.
•
현재 많은 도구가 백그라운드 교체 기능을 제공하지만 경계, 특히 머리카락이나 안경처럼 섬세한 디테일이 있는 영역에서 Artifacts를 생성함.
•
반면, 기존의 이미지 매팅 방법은 훨씬 높은 품질의 결과를 제공하지만 실시간으로 실행되지 않으며 수동 입력이 필요함.
•
본 논문에서는 최초로 완전 자동화된 실시간 고해상도 매팅 기법을 도입하여 4K에서는 30fps, HD에서는 60fps로 실시간 백그라운드 교체를 제공함
•
고해상도 영상을 실시간으로 처리할 수 있는 네트워크를 설계하기 위해 영상에서 미세 조정이 필요한 영역은 상대적으로 적음.(배경을 제외한 부분만 조정하면 되기 때문에)
•
따라서, 고해상도가 필요할 수 있는 영역을 지정하는 오류 예측 맵과 함께 Alpha Matt 및 Foreground 레이어를 Low Resolution으로 예측하는 네트워크를 도입한다.
•
Stage 2: Refiner Network는 저해상도 결과와 원본 영상을 합하여 선택한 영역에서만 고해상도 출력을 생성한다.
Approach
이미지 포뮬레이션:
이미지 I 와 캡처된 배경 B가 주어지면 알파 매트 a와 foreground F를 예측한다.
이를 통해 새로운 배경 을 합성할 수 있다.
이처럼 Foreground를 직접 예측하는 것 대신,
Foreground residual 을 예측하여 를 복구하는 접근방식을 고안했다.
이를 이미지에 적합하도록 적절하게 클램핑해주면 다음과 같다.
고해상도 매팅에 딥 네트워크를 직접 적용하는 것은 비실용적인 연산과 메모리 소비량이 발생하기 때문에 어렵다.
이 공식을 통해 학습 능력을 향상시키며,
업샘플링을 통해 고해상도 입력 이미지에 낮은 해상도의 foreground residual을 적용한다.

Architecture

•
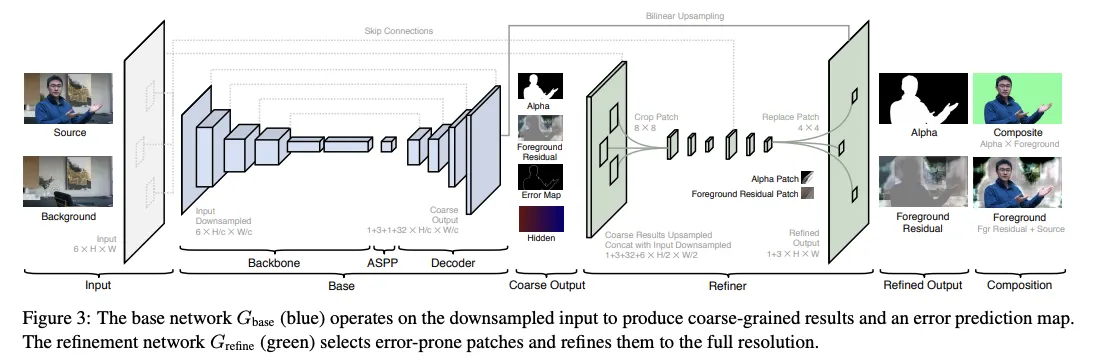
Architecture는 기본 네트워크 base와 세분화 네트워크인 refine으로 구성된다.
•
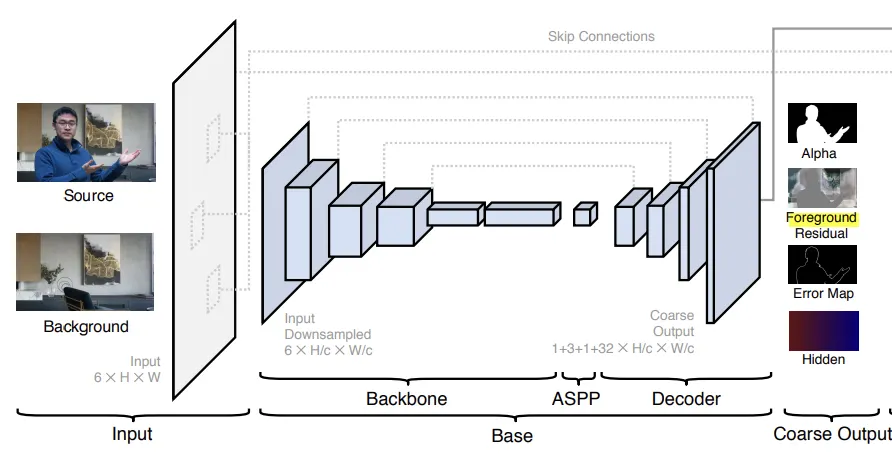
원본 이미지 I와 캡처된 배경 B가 주어졌을 때, 먼저 I와 B에 대한 피쳐를 다운 샘플링한다. (Ic, Bc)
기본 네트워크
•
입력:
•
출력:
◦
: coarse-grained alpha matte
◦
: foreground Residual =
◦
: Prediction Error Map
◦
: Hidden Feature, global context
•
본 모델은 fully-convolutional이며 임의 크기의 input에 대하여 학습할 수 있다.

•
Refine 네트워크에서 Hc, I 그리고 B를 이용하여 예측 오차 Ec가 큰 지역에서만 ac와 FRc를 Refine하고 원래 해상도에서 a 및 foreground Residual FR을 생성한다.
•
Refinement 네트워크를 좀 더 자세히 설명하자면, 계산 중복을 줄이고 고해상도 매팅 세부 정보를 복구하는 것을 목표로 한다. 기본 네트워크는 전체 이미지에서 작동하지만 미세 조정 네트워크는 오류 예측 맵 Ec를 기반으로 선택한 패치에서만 작동한다. 먼저 원래 해상도의 1/2에서 최대 해상도로 2단계 정교화를 수행한다.
•
원래 해상도의 1/c(HD에서는 1/4, 4K에서는 1/8)에서 대략적인 Error prediction map Ec를 먼저 원래 해상도로 다시 샘플링한다. 맵의 각 픽셀은 원래 해상도의 4X4 패치에 해당한다. Refine 모듈을 통해 정교해진 패치 위치를 나타내기 위해 예측된 오류가 가장 높은 상위 픽셀을 선택한다.
•
Refine 모듈에서 나오는 패치들을 원래 해상도 입력 이미지 및 배경에서 추출한 곳에 합친다. 이 과정에서 알파 매트와 foreground residual을 얻을 수 있다. 마지막으로 coarse alpha matt ac와 foreground residual FRc를 원래 해상도로 업샘플링하고 최종 알파 매트와 foreground 잔차를 얻기 위해 각각의 패치를 교환 한다.
Losses
alpha matt loss: L1 loss and sobel gradient
Foreground residual loss: alpha값이 있는 곳에서만 foreground loss 계산
Error Loss: L1 loss
Experiments
•
Backbone: Deeplab V3 pretrained on ImageNet and Pascal VOC
•
step 1: Train base network till converge
•
step 2: Train refinement network and base network jointly.
Dataset
•
they have introduced two large-scale video and image matting datasets
VideoMatte240K

•
484 green screen videos from online.
•
4K (384), HD (100)
•
various human subjects, poses, clothing.
•
Helpful to build robust model
PhotoMatte13K/85

•
13,665 studio-quality image shots.
•
High resolution (2000 x 2500)
•
narrow range of pose.
Metrics
DIM(Deep Image Matting)
FBA(FBA matting)
BGM(Background Matting)
SAD(sum of absolute difference)
MSE(mean squared error for alpha and foreground)
Grad(spatial-gradient metric)
Conn(connectivity for alpha only)
Experimental Results





Notable Points


•
창의적인 접근방법: 이미지를 전체로 처리하는 대신 바운더리만 처리해볼까? → zoom에 최적화.
•
Ready-to-commercial use. : zoom plugin 개발.
•
자신들의 한계를 밝히는 데에 솔직했다는 점.
•
Dataset Release.
•
Well-written paper.
•
Well-visualized.
•
Well-Promoted and viral via twitter.

