

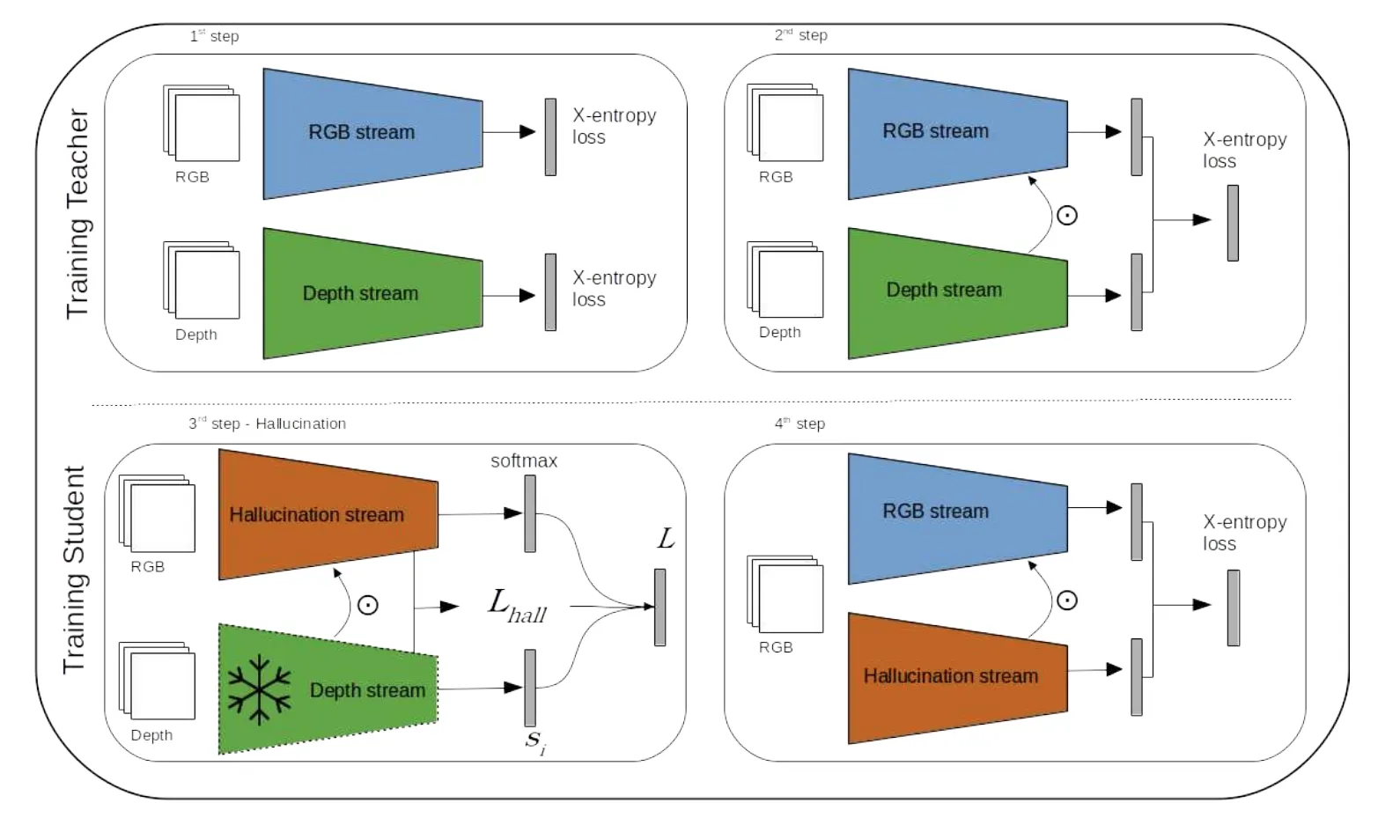
Fig. 1. Training procedure described in section 3.3 (see also text therein). The 1 st step refers to the separate (pre-)training of depth and RGB streams with standard cross entropy classification loss, with both streams initialized with ImageNet weights. The 2 nd step represents the learning of the teacher network; both streams are initialized with the respective weights from step 1, and trained jointly with a cross entropy loss as a traditional two-stream model, using RGB and depth data. The 3 rd step represents the learning of the student network: both streams are initialized with the depth stream weights from the previous step, but the actual depth stream is frozen; importantly, the input for the hallucination stream is RGB data; the model is trained using the loss proposed in equation 5. The 4 th and last step refers to a fine-tuning step and also represents the test setup of our model; the hallucination stream is initialized from the respective weights from previous step, and the RGB stream with the respective weights from the 2 nd step; this model is fine-tuned using a cross entropy loss, and importantly, using only RGB data as input for both streams.