

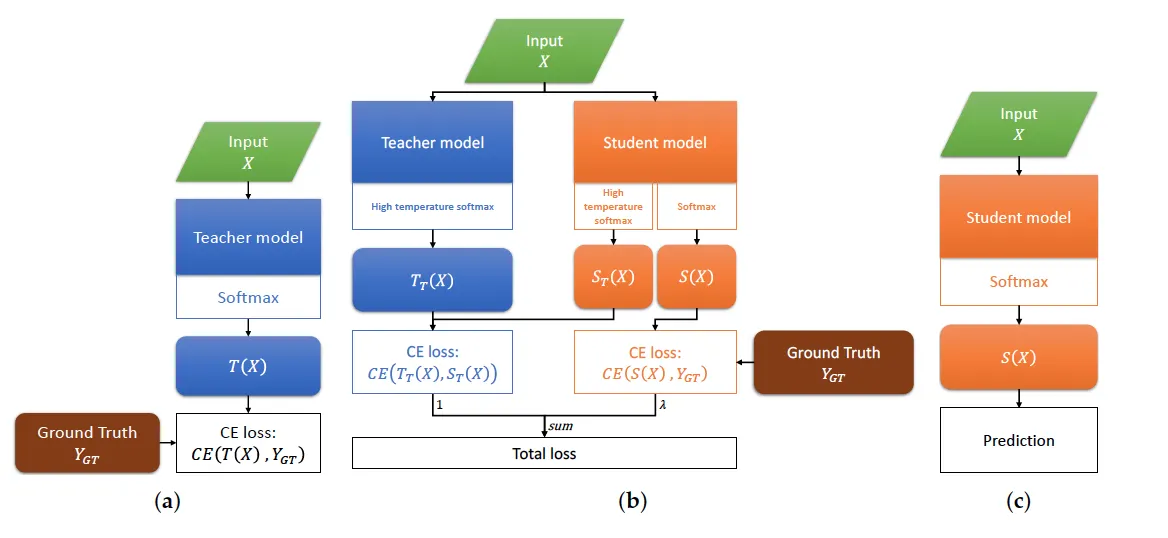
Figure 2. (a) Train the teacher model directly on dataset; (b) The process of KD training. The student
model output two branches: high-temperature softmax output distill knowledge from the teacher
model and the normal softmax output learn to match the ground truth label; (c) In prediction mode or
production environment, the trained student model only output normal softmax result.