
Introduction

신경망을 인간이 해석할 수 있어야 한다는 필요성이 점점 강조되면서, 신경망 해석 가능성(neural network interpretability) 분야가 빠르게 발전하고 있습니다. 특히, 비전 분야에서는 feature visualization과 attribution 두 가지 접근법이 활발히 연구되고 있습니다.
아래에는 각 카테고리에 대한 간략한 개요와 대표적인 방법들을 정리했습니다. 더 자세한 내용은 아래 레퍼런스를 참고해주세요.
I. CNN Feature Visualization
1. Activation Maximization (최적화)

개요:
•
목적: 특정 뉴런이나 레이어의 활성화를 극대화하는 입력을 찾음.
◦
이를 통해 네트워크가 학습한 패턴을 시각화함.
◦
특정 출력을 생성하는 데 중요한 특징과 단순히 연관된 특징을 구별할 수 있음.
•
방법: 입력 이미지의 픽셀 값을 변경하면서 목표 활성화 값을 최대화하는 방향으로 반복적으로 업데이트함.
1.
2. Class Activation Mapping (CAM)
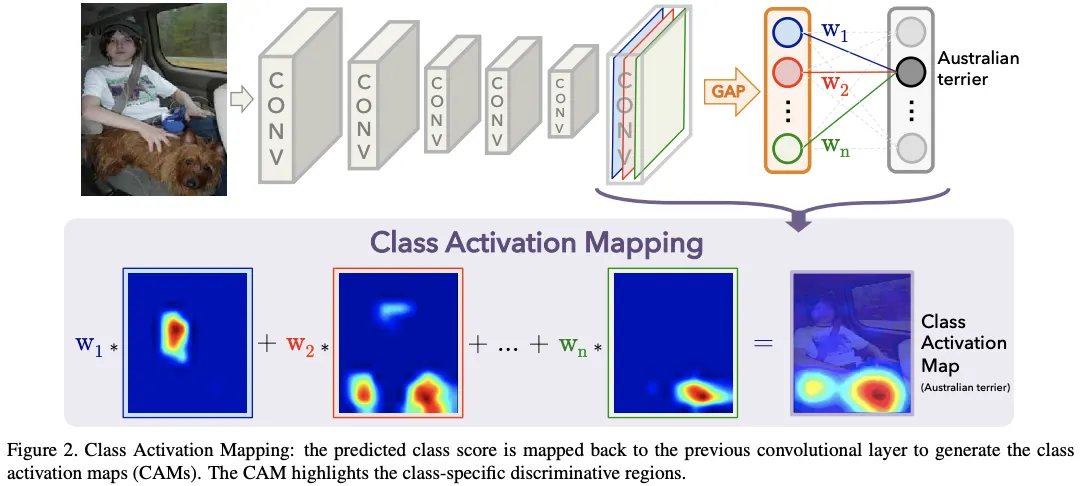
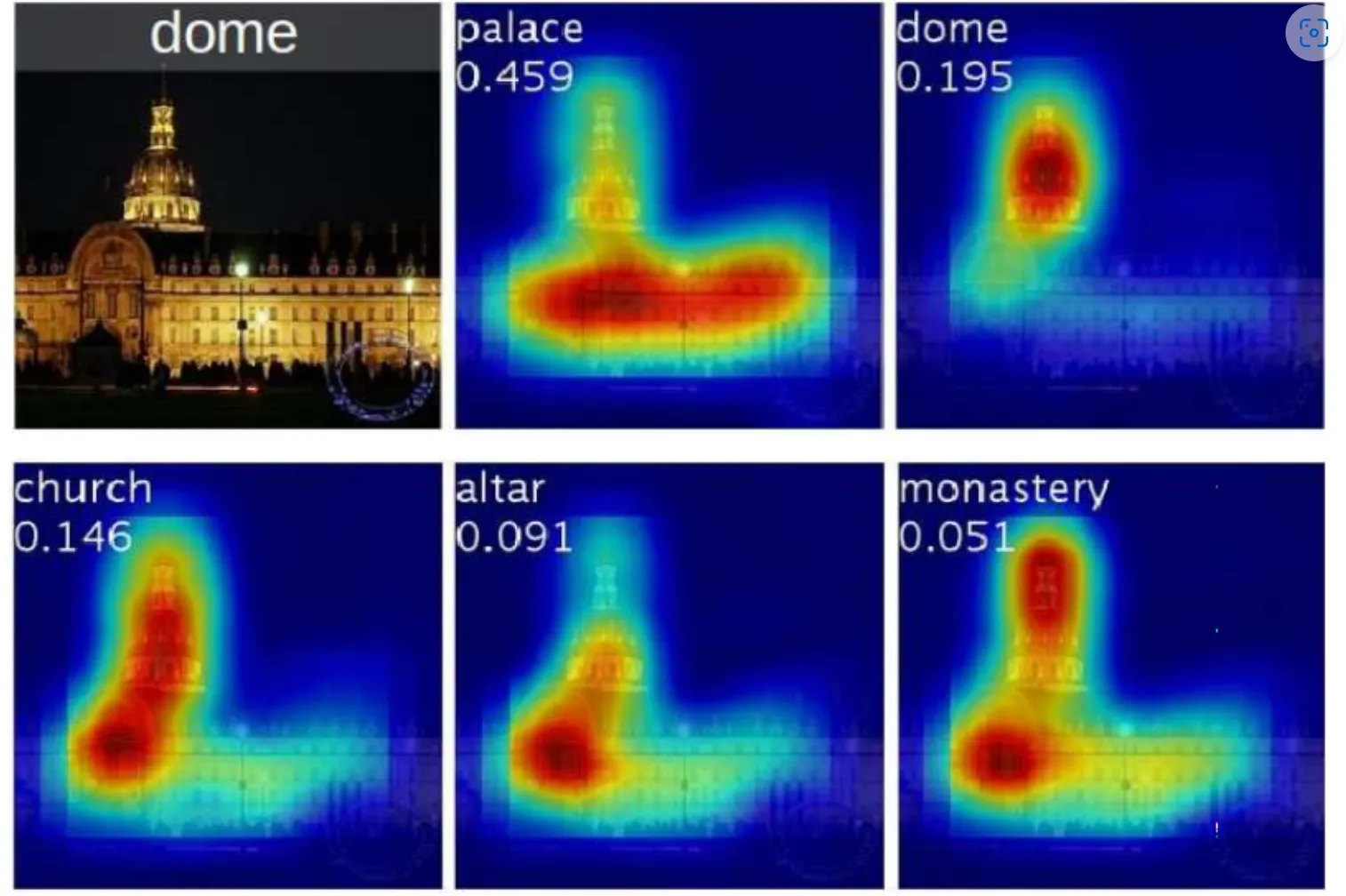
•
개요:
◦
입력 이미지에서 특정 클래스에 대한 모델의 관심 영역을 강조하여 시각화하는 기법.
◦
모델이 특정 클래스를 예측할 때 입력 이미지의 어느 부분이 중요한지 보여줌.
•
연구 동향:
◦
◦
◦
◦
3. Feature Map Visualization

1.
개요:
•
CNN의 중간 레이어에서 활성화된 특성 맵을 시각화.
•
모델이 입력 이미지의 어떤 부분에 주목하는지 파악하는 기법.
2.
연구 동향:
•
•
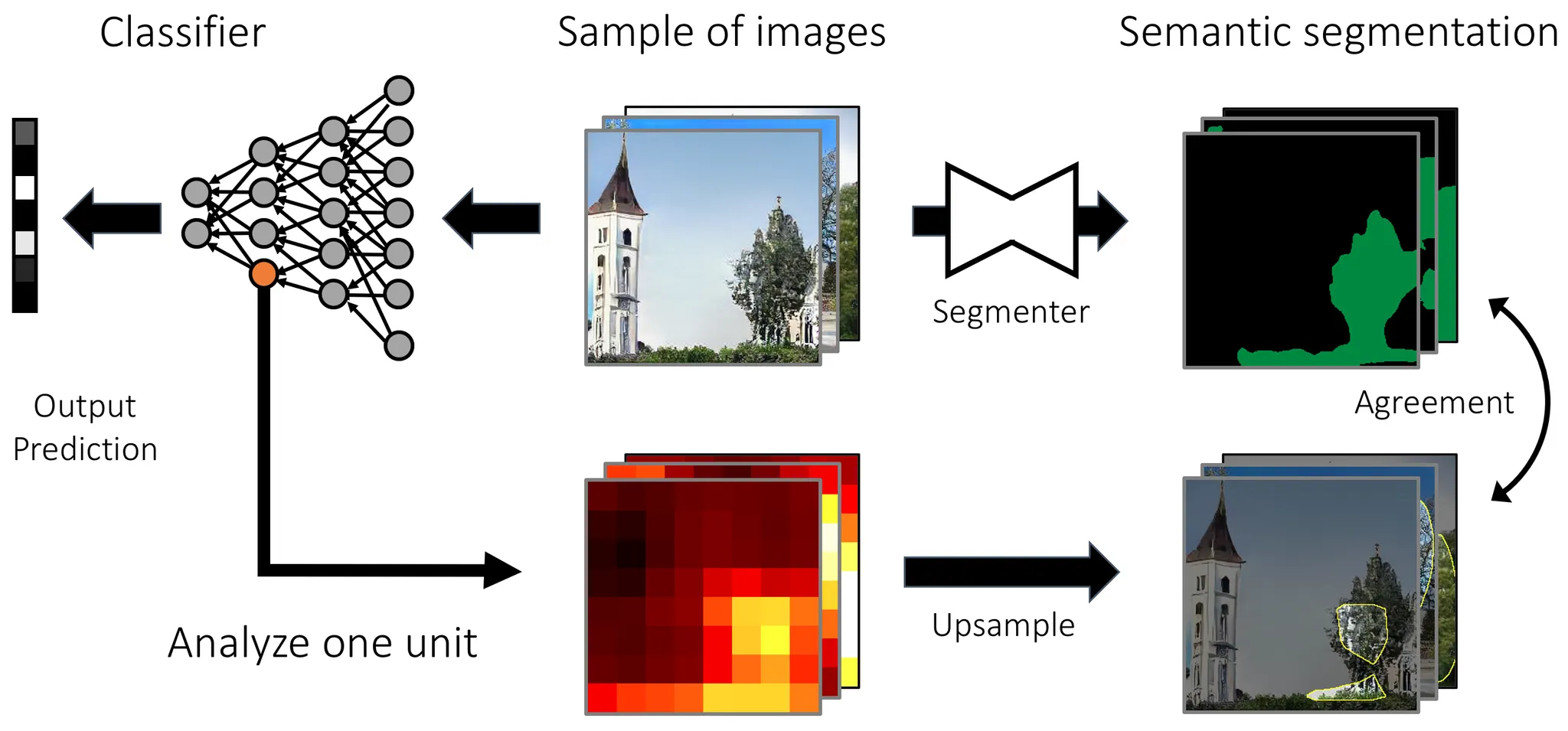
4. Dissection
•
네트워크 내부의 feature map을 upsample해서 output과 aggrement를 평가.
•
Feature map의 각 부분이 어떤 영역을 담당하는지 탐구.
4-1. CNN Dissection
4-2. GAN Dissection
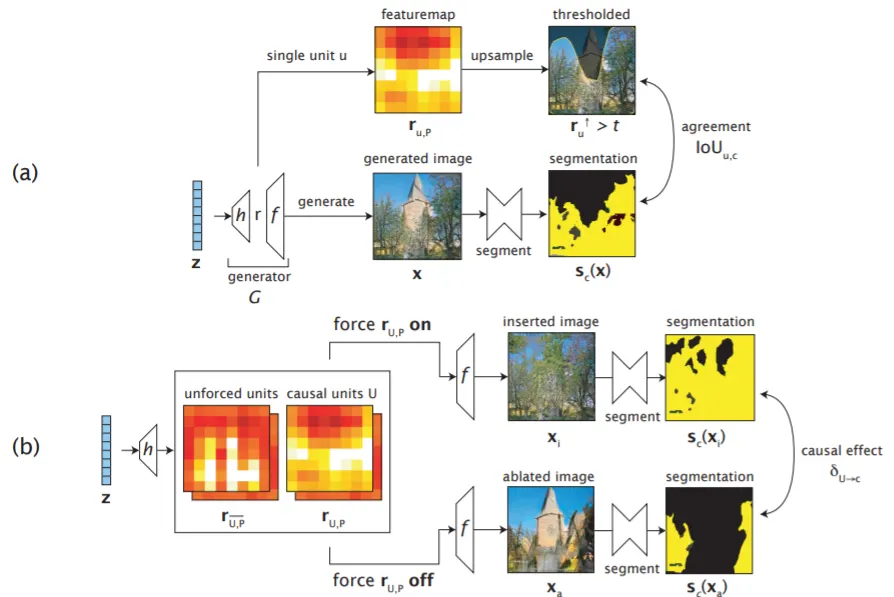
개요:
•
목적: 생성적 적대 신경망(GAN)의 내부 표현을 분석하여 생성 이미지의 특정 요소와 연결된 뉴런을 식별함.
•
방법: GAN의 중간 레이어에서 활성화된 뉴런들을 조작하여 생성된 이미지의 특정 요소를 제어.
주요 특징:
•
뉴런 해부: GAN의 뉴런들이 어떤 시각적 개념을 표현하는지 파악.
•
이미지 조작: 특정 뉴런의 활성화를 조절하여 생성 이미지에서 객체의 존재 유무나 속성을 변경.
관련 연구:
•
5. Diffusion Feature Analysis

개요:
•
목적: 확산 모델(Diffusion Model)의 내부 동작을 이해하고, 생성 과정에서의 특징을 분석함.
•
방법: 확산 과정의 중간 단계에서의 표현을 시각화하고, 노이즈 제거 과정에서의 특징 변화를 분석.
관련 연구:
•
6. 기타 관련 Tasks
•
•
Interpretable Machine Learning: allow oversight and understanding of machine-learned decisions.
II. Dimension Reduction (차원 축소)
•
고차원 데이터를 저차원으로 변환하여 중요한 정보를 추출하고, 모델의 학습 효율을 높이는 기법.
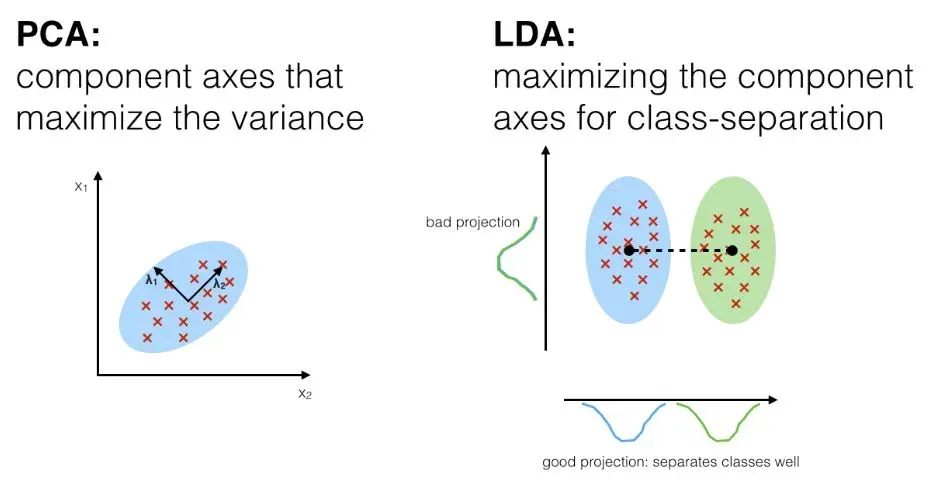
1. 주성분 분석 (PCA, Principal Component Analysis)
1.
개요:
•
고차원 데이터를 저차원으로 변환하여 데이터의 분산을 최대한 보존하는 선형 변환 기법.
•
이를 통해 데이터의 주요 특징을 유지하면서 차원을 축소하여 분석의 효율성을 높임.
2.
주요 특징:
•
차원 축소: 고차원 데이터에서 상관관계가 높은 변수들을 결합, 주요 성분으로 표현해 차원을 축소함.
•
분산 보존: 데이터의 분산을 최대한 보존하는 방향으로 주성분을 추출하여 정보 손실을 최소화.
•
선형 변환: 데이터의 공분산 행렬을 고유값 분해하여 주성분을 추출.
2. 선형 판별 분석(LDA, Linear Discriminant Analysis)
1.
개요:
•
지도 학습 기법.
•
클래스 간 분산을 최대화하고 클래스 내 분산을 최소화하는 방향으로 데이터를 변환.
2.
주요 특징:
•
분류 지향 차원 축소: Class Label 정보를 활용하여 분류에 최적화된 저차원 공간으로 데이터를 투영.
•
클래스 간 분산 최대화: 클래스 간 평균의 차이를 최대화하여 클래스 간 구분을 명확히 함.
•
클래스 내 분산 최소화: 동일 클래스 내 데이터의 분산을 최소화하여 데이터의 응집도를 높임.
3. 독립 성분 분석(ICA, Independent Component Analysis)
1.
개요:
•
다변량 신호를 통계적으로 독립적인 하부 성분으로 분리하는 비선형 변환 기법.
2.
주요 특징:
•
신호 분리: 혼합된 신호에서 원래의 독립적인 신호를 추출하여 원천 신호를 복원.
•
비가우시안성 활용: 데이터의 비가우시안성을 활용하여 독립 성분을 추출.
•
비선형 변환: 선형 변환인 PCA와 달리, ICA는 비선형 변환을 통해 독립 성분을 추출.
4. t-SNE (t-Distributed Stochastic Neighbor Embedding)
1.
개요:
•
고차원 데이터의 국소적 구조를 보존하며 저차원 공간에 임베딩하는 비선형 차원 축소 기법.
•
데이터 포인트 간 유사성을 확률 분포로 모델링해 저차원에서의 유사성을 최대한 반영함.
2.
주요 특징:
•
국소 구조 보존: 데이터의 군집 구조를 효과적으로 시각화할 수 있어, 유사한 데이터들이 가까이 위치하도록 임베딩.
•
비선형 변환: 비선형 특성으로 인해 복잡한 데이터 구조를 저차원에서 표현.
•
계산 복잡도: 대규모 데이터셋에 적용할 경우 계산 비용이 높으므로, 샘플링을 통해 활용할 수 있음.
5. UMAP (Uniform Manifold Approximation and Projection)
1.
개요:
•
고차원 데이터의 전반적인 구조와 국소적 구조를 보존하면서 저차원 공간에 임베딩하는 비선형 차원 축소 기법.
•
위상수학과 기하학을 바탕으로 데이터의 전반적 분포를 잘 표현함.
2.
주요 특징:
•
전반적 구조 보존: 데이터의 전체적 구조와 국소 구조를 모두 효과적으로 시각화하여, 데이터의 전체적 분포를 파악하는 데 적합.
•
고속 처리: t-SNE에 비해 대규모 데이터셋에 대해 더 빠르게 처리 가능.
•
유연한 매개변수 설정: 하이퍼파라미터 조정을 통해 국소와 전반적 구조 간 균형을 조절 가능.