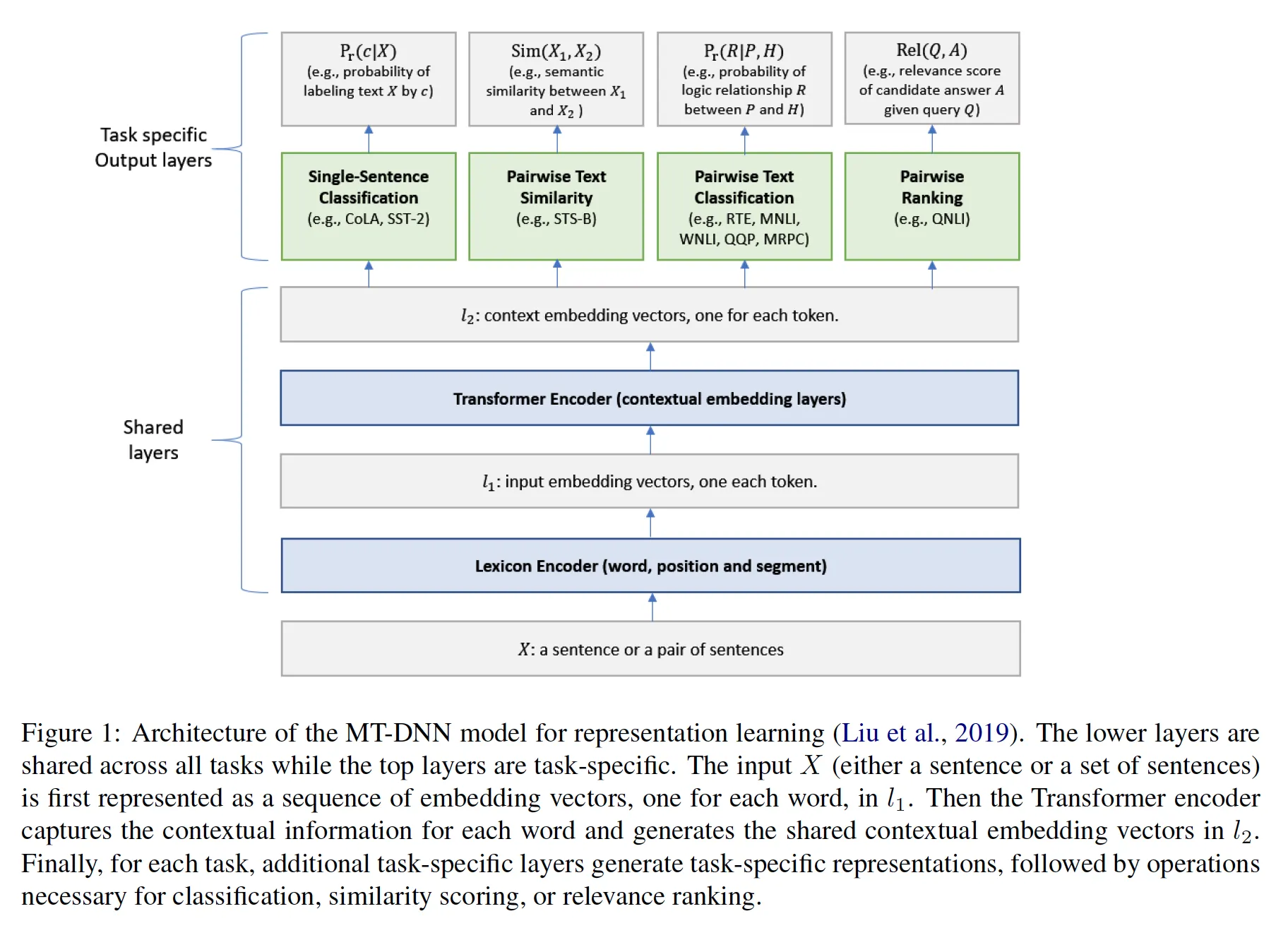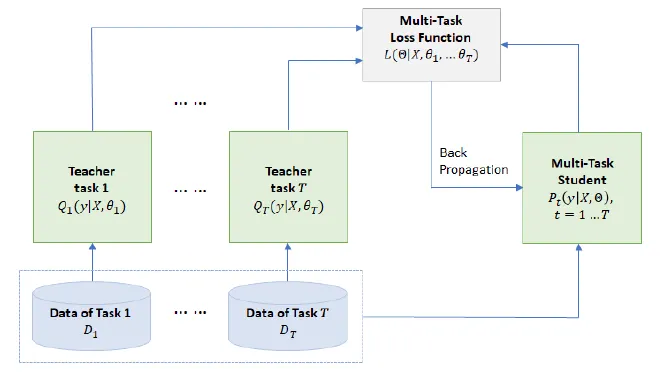
Figure 2: Process of knowledge distillation for multi-task learning. A set of tasks where there is task-specific
labeled training data are picked. Then, for each task, an ensemble of different neural nets (teacher) is trained. The teacher is used to generate for each task-specific training sample a set of soft targets. Given the soft targets of the training datasets across multiple tasks, a single MT-DNN (student) is trained using multi-task learning and back propagation as described in Algorithm 1, except that if task t has a teacher, the task-specific loss in Line 3 is the average of two objective functions, one for the correct targets and the other for the soft targets assigned by the teacher.